
Two Final Projects Inspired by Audi for Beginners
前幾天寫了關於 Audi 的 Travolution,進而想到了兩個相關的題目, 蠻適合給大一學生作 Final Project 的. ( 話說為什麼我會在颱風風雨中騎機車時想到這個呢 = = )
1. 真人版 Travolution
第一個是利用 Wireless Device 直接模擬 Audi Travolution 的運作. 可以在電機系館一樓的空間劃定線格代表街道跟路線, 架設假的紅綠燈, 用不同的 Wireless Device 放置在紅綠燈定點, 就跟 Audi 在真實的紅綠燈上作的一樣.
學生手上拿的是 Notebook 或是 UMPC, 同時學生寫的作業就是要模擬 Audi 在汽車上的 Client Software, 必須時時提醒駕駛員目前的時速應該控制到多少. 整個距離可以用等比例作規劃, 學生就拿著 NB 把自己當作汽車在跑, 感覺有點像大富翁 :p
中間可以加上一些特殊事件, 道路速限, 道路維修, 臨檢等等, 就更像大富翁了. 同時學生之間是需要彼此競爭的. 不過由於這是給大一學生的 Project, 因此基本的環境架設就要由 TA 負責.
2. Travolution 模擬遊戲
跟真人版的一樣, 只是在模擬遊戲中, 學生必須寫出 Strategy 來控制所有的車輛, 從一個既定範圍的四周會不斷的有新的車輛湧入, 要到達特定的出口 ( 一張圖有許多出入口 ), 同樣道路有許多的特性, 中間當然也會有紅綠燈的出現, 而最終目的是要讓所有車輛所使用的平均時間最少. 這樣的模擬遊戲當然也可以讓不同的學生彼此競爭, 只要讓新湧入的車輛分別受不同的 Strategy 控制即可. 同樣的, Strategy 可以執行的 Environment 也需要由 TA 去建構.
這樣的模擬遊戲當然也可以讓不同的學生彼此競爭, 只要讓新湧入的車輛分別受不同的 Strategy 控制即可. 同樣的, Strategy 可以執行的 Environment 也需要由 TA 去建構.
這兩個遊戲的目的都是希望透過進行跟業界真實產品類似的作業, 讓學生可以比較容易想像自己的 Programming 可以用在甚麼樣的地方, 發揮甚麼樣的價值.
Something about Library 2.0 (1) : Digital Library
Library 2.0 的議題在國內外已經有數年的討論了. 關於命名當然跟 Web 2.0 有關, 但是整體概念的演進早在 Web 2.0 被 Tim O'Reilly 拋出之前.
我現在有在訂閱的幾個 Bloggers 也持續的關注此議題, 不過大多是以圖書館員, 或是圖書館界人士的角度. 正巧我之前跟老師的討論中整理了一些關於 Library 的想法, 是從 Architecture Evolution 的角度整理的, 順手搬到 Blog 上, 從不同的角度看 Library 2.0
跟其他的 XXX 2.0 一樣, Library 2.0 絕對不是獨立的技術跟概念, 而是同一個趨勢在不同領域的展現, 透過搬移其他領域的成功經驗, 以及解決其他領域一樣遇到的問題, 才有可能讓 Library 2.0 的理想獲得成功. ( 當然, 還要主事者不腦殘 = = )
1. The Definition
引用 Wikipedia 上對於 Library 的部分敘述 :
A library is a collection of information, sources, resources and services, organized for use, and maintained by a public body, an institution, or a private individual. In the more traditional sense, it means a collection of books. This collection and services are used by people who choose not to — or cannot afford to — purchase an extensive collection themselves, who need material no individual can reasonably be expected to have, or who require professional assistance with their research.
從這段敘述中可以推想出幾個關於 Library 的特性, 我認為也適用於 Library 2.0 :
- Library 內的東西可以有很多種, 而非只有 book 而已
- Library 內的東西必須經過特定的整理以方便使用
- Library 的 maintainer 可以是單一個人, 一小團體, 一個機構, 甚至是大眾, 並沒有特別限制
- Library 的大小並沒有特別的限制
- Library 的使用者數量也沒有特別的限制
2. The Conventional Solution
目前常見的 Library 所採取的做法是, 由 Maintainer Role 負責為 Library 內的各種 contents, 例如 books, 事先以特定的分類方式作分類, 然後 User Role 必需去學習這樣的分類方式, 以便有效率地進行搜尋以取得想要的 contents.
在此做法下, Maintainer Role, Library, 以及 User Role 之間的關係像是這樣的 :
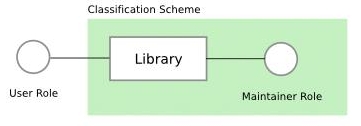
Maintainer Role 除了要負責維持 Library 的 functionality 運作之外, 同時也負責設計及實施 classification scheme, 而 User Role 是在 Maintainer Role 所決定的 Classification Scheme 下所使用 Library.
這樣的 solution 基本上是可以運作並實現 Library 的功能, 但是這樣的 solution 並不夠好 :
在此 solution 底下, User Role 被迫必須接受並使用 Maintainer Role 的觀點, 而難以較有效率且符合自身需要的方式來重新分類 Library 內的 contents
對 Maintainer Role 來說, 也因為此 solution 而限制了他們可以嘗試的 classification scheme. 因為大多數 Users 會希望到各個不同 Library 可以以自己習慣的方式作 contents 找尋的動作, 而不是每到不同的 Library 就需要面對不同的 classification scheme. 因此 Maintainer Role 其實只能被限制在數種主流的 classification scheme 中
我認為之所以會產生這些 imperfect 問題的原因, 其實跟過去基於人力所能負擔的 effort 有限, 以及 Library 是實體的 ( Physical ) 有關, 例如圖書館.
由於過去主要以人力進行管理與維護, 因此如果 classification scheme 不由 Maintainer Role 所掌控, 並強迫 User Role 依照統一的 scheme 使用, 則為了應付不同 Users 的需求, Library Maintainer 必須花費相當巨量的 efforts 來提供服務, 但如此一來 cost 也相對大量增加, 這將與 Library 概念的初衷之一, 減少整體社會接觸知識所需要的 cost, 產生相違背的情況.
3. The Digital Solution
在 Computer 被發明並普及化後, 其實我們應該回頭去思考, 是否可以利用 computer 的 computation power, 重新去改進過去限於人力考量, 所無法圓滿解決的 Library 問題.
利用 computer 的特點在於, (1) computer 具有較為低廉的 computation power, (2) 基於 computer, 許多 Library contents 得以數位化 ( digital ) 的形式存在, 以及被取用. 底下稱呼利用 computer 來解決的做法為 digital solution.
鑑於 application context 的不同, 我認為 digital solution 可以分為下面兩者, 兩者的差別在於 Library 內所管理的 contents 是否具有實體而定.
Semi-Digital Library : 其內的 contents 仍然具有實體, 因此我們不可能使用不固定的 classification scheme 來管理這些 contents, 在實體世界中必然要選擇一種 scheme 來管理這些實體 contents. 但是對於 User Role 在進行搜尋來說, 由於可以把這些實體 contents 以虛擬的物件 ( Virtual Object ) 來表示, 因此在 User Role 端可以保有自己的classification scheme, 透過 computer 進行管理, 不需要花費 Maintainer Role 的 effort. 因此在此 solution 下, Maintainer Role 的責任略小, 只負責實體 contents 的管理, 以及 Semi-Digital Library functionality 的正常運作.

Digital Library : 其內的 contents 完全是 digital contents, 因此完全可以使用 computer 進行儲存以及其他管理. 因此在 classification 部分, Maintainer Role 完全不需要介入, Maintainer Role 將只需要負擔維持 Digital Library 的 functionality 正常運作的責任即可. 而 classification scheme 將完全基於 User Role 運作.
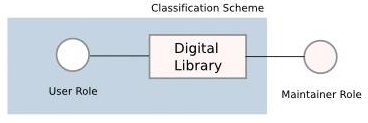
上述的 Semi-Digital Library 以及 Digital Library 兩個 solutions 之共同特點在於, 利用 computer, 將 classification scheme 的調整以及決定, 曝露 ( expose ) 給 User Role. 進而 classification scheme 有機會具備 personalization 的特性. 而回頭去看 conventional solution 中的 imperfect 部分, 將可以藉由此種方式被滿足.
4. Personal Small Library
另外在此想特別針對較小的 Library 討論其應用 digital solution 之後的改變.
在 1999 年日本偶像劇場有一部戲劇叫做 Lipstick, 其內有一句台詞大概是這樣說 :
許多小型的 Libraries 事實上具有特殊的用途, 可能是學者或是作家私人的參考資料庫, 或是一個實驗室共用的圖書研究資料蒐藏, 一個機構的歷史文件彙整等等. 因此裡面所放置的 contents相當程度反映了 Maintainer Role 或是 User Role groups 的相關訊息, 極有可能這些 contents 本身就具有一定的相關度, 而此相關度反映在使用該 Library 的 users 身上. 同時這樣的小型圖書館有一個極大的特點, 在於 User Role 的使用方式以及用途有極高的相似度, 使得嘗試統整所有使用者的 classification scheme, 以及 logic, 來為彼此的搜尋提供幫助, 具有很高的可行性以及實用性.
如果有一個夠小的公共圖書館, 是由一個人單獨維護管理 ( 包含選書以及整理 ), 則透過仔細觀察這個圖書館裡的書, 你將能夠窺視管理者的個人思維.
然而這在 conventional solution 中較難以實現, 理由是各 Users 的使用觀點事實上會隨著時間而有所變動, 進而牽動整個 group 的整體共通觀點改變, 換句話說這樣的改變是動態地, 隨時發生的, 且是藉由許多 Users 的意見交錯協調條而達到一個穩定的狀態 ( Stable Status). 在 conventional solution 中, 這樣的改變較難以達到, 因為這需要所有 Users 定期舉行會議, 討論大家都可以接受的 classification scheme, 相當地耗費時間.
相對來說, 在 digital solution 中顯然就較為容易做到, 藉由 computer 以及 network 的幫助, Users 的使用模式以及使用邏輯 ( Logic ) 可以被紀錄與分析, 進而彼此影響, 達到一個 group 內共享的觀點. 而且此共享的觀點可以隨著 Users 端的改變而動態地調整. 而在此同時, 各 Users 保持有自己的觀點仍舊是可能的.
而由此觀點而言, Semi-Digital Library 以及 Digital Library 使得 Library 不再只是靜態的 content data 的分類存放以及取用場所, 而是轉變為 group 內 users 的意見彙整平台之一, 透過在 Digital Library 內分享觀點, Digital Library 轉變成為引導 group 前進方向的動態角色之一.
5. Public Large Library
Large Public Library 的情況就與 Small Library 的情況不盡相同. 差異在於 Large Public Library 的使用者通常較多且雜, 使用目的也差異較大, 因此利用 digital solution 可以達到的好處應該會比較偏向 personalization 部分. 然而在統計數據的支持下, 或許可以考慮把 Large Public Library 切割成數個 clusters, 然後將每個 cluster 視為 Small Library 來處理. 在此情況下, 需要每個 cluster 有固定的 Users 才可行.
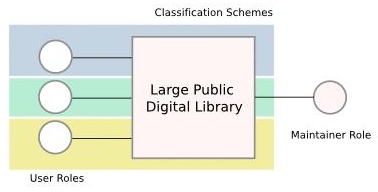
目前在 Web Recommendation System 上已經出現了類似的概念被實現, 例如 Reddit, Mixx 都有讓使用者建立自己的 Community 的能力, 而 Digg 也準備跟進. 當然這只是在 Web 的部份而已.
恐怖的 Adeona
過去兩三個禮拜 Adeona 忽然變成了一個熱門關鍵字 :p
原因是 Adeona 這個 Open Source Project, 號稱是第一個可以對於你的 Laptop Notebook 進行 Tracking 的 Open Source Software, 對於追回失竊的 Notebook 來說特別有用.
其基本的概念是在 Notebook 上安裝一個 Client Software, 每當 Notebook 連接上網路時, 會自動將該 Notebook 的位置 ( IP 以及相對存取周遭網路設備的位置 ) 進行 AES 加密後, 利用 OpenDHT 技術存到特定的 Server 上, 該加密過後的位置資料只有原始擁有者可以開啟, 如此一來 Notebook 的擁有者就可以對於 Notebook 的位置進行追蹤, 並確保自己的隱私.
關於 Privacy 部份, 事實上 Adeona 作的考量更多, 包含無法簡單透過 Location Update 去鎖定特定的 Device 等等, 務求達成 Anonymous, Unlinkable Updates, 詳細內容請見 Adeona 的發表 Paper , 在講述 System Goal 的部份有列舉說明.
我之所以覺得 Adeona 很恐怖是因為, 同樣的概念幾乎可以用在任何可以運作 Software 的地方(或東西). 甚至我可以說, 一般 Notebook 並非 Adeona 最好的利用環境. 理由是一般 Notebook 或是 Laptop 的系統都很容易被重新安裝或是修改. 重新安裝會使得 Adeona 失去作用, 而修改則可能使得竊賊進一步利用 Adeona 對於追蹤進行欺騙.
反倒是其他的高價物品, 利用 Adeona 的可能性以及有效性極高. 例如在無線環境下的汽機車, 高單價的 Mobile Device, 重要的文件盒保險箱等等 ( 不用再害怕忘在公車或是計程車上摟 ). 可以簡單把 Adeona 作成一個具無線網路功能的訊息送出嵌入式設備, 讓使用者自行安裝在要追蹤的物品上. 這種嵌入式系統就可以避免掉上述的問題, 只要不被從保護物品上拆除就好. ( 使用者可以裝在很隱密, 或是無法拆除的地方 ). 從這個角度來看, 其實跟 RFID 又有點像, 但是安全性以及範圍又比 RFID 大很多.
而除了這些可能之外, 最恐怖的是, Adeona 也可能被裝在 Software 或是 Data 身上, 讓我們可以對於 Software 或是 Data 的 Distribution 作追蹤, 例如公司內重要的電子文件管理, 怎樣確保每一份被複製的重要文件, 沒有在允許以外的地方被開啟.
這樣一想, Adeona 的概念幾乎可以用在任何地方, 這能不恐怖嗎, 光用想的我雞皮疙瘩就起來了 = =
James Gosling's Q&A Podcast at Java One 2008
James Gosling 在 Java One 2008 的一個 Q&A Session 內容現在可以利用 MP3 下載聽了. 不過我覺得大多問題其實沒有很深入地回答, 本來看到網頁上寫到 java.net 的未來還蠻有興趣的, 以為會跟 SOA 有很強的關聯, 不過就我聽到的內容, 似乎也是輕輕帶過而已.
大概有以下重點 ( 邊聽邊隨便打打, 內容文法可能...ㄜ, 語句應該也不是很連貫, 重點節錄, 跟 Java 關係不大的議題我就自動跳過了 ) :
- 有人問道 : If you develop Java all over again, what will be done differently. 於是 Gosling 就說啦, Properly wont develop AWT (觀眾笑), and left over calender class ( 這點不是很確定, 因為 calender 不是被大修過, 為什麼是 left over ? ), won't done closure at the first time.
- 有人關心 Balance between continuous adapting, evolving, changing of Java and the the mature of Java, 可能是想問究竟 Java 算不算成熟, 持續的有改變是否是好事之類的. Gosling 回答道, Java 5 is really a change ( 事實上直到 Java 5 才真正做了比較大的改變 ) . There are still many Java 7 proposals on debate. The way people use it is changing. Java works out better then expected. Many proposals, such as bound property proposal, are more complicated than just writing the code. Must consider some issues, such as explosion and chaos of APIs. ( 我覺得這跟一般的 Software 增加新的 Features 是差不多的 )
- Something about Generic, seems similar with last question.
- Favorite IT/IS topics of James Gosling. Depend on who he talks. ( No very related with Java. )
- Future of "small Java" ( Nothing new actually )
- Favorite Language despite Java ? James Gosling : It's an easy quesiton, Scala. ( 一點都不熟阿 = = 要檢討 )
- 有人問道 Java is similar to an OS ( 指在很多表現上很像一個 OS ), platform, not simply a Programming Language environment. James Gosling 順著接手說, bycode is general for many languages. 雖然 JVM 將可以支援很多不同的語言 ( More and more services can built upon JVM in next 10 years. ), 但是某些語言是難以被完整支援的, 特別是跟 pointer 有關的語言. 即便如此, Give up C/C++, that was no-brainer. 中間還有說道 James Gosling 其實很 appreciate Microsoft 對於 C/C++ 的付出貢獻 ( 我應該沒聽錯 XD )
- 有人問道 Java 7 的時間表. Time frame for Java 7 or new features, or progress. James Gosling 說 It not technical question, but policy, JCP, something related ( 就是說沒辦法單單從 Technology 角度給答案啦, James Gosling 目前是 Sun 的 Client Software Group CTO ). There is no schedule, hope yesterday :p
- 給大家的話. Last word for developers : Drink more Beer ^^ (這應該是給 Java One 參加者的話) , Make sure you working on projects for fun.
整個錄音中其實我最有興趣的是 James Gosling 反覆提到的那個 Slide Program, 但是只有發音 ( 類似 Hextor 的發音 ) 不知道怎樣查, 嘗試幾個都找不到 @@
中央氣象局什時會整合 Google Earth ?
颱風夜寫這篇真是應景阿 ^^
長久以來中央氣象局都只有提供俯瞰的衛星雲圖, 但是 Abstraction Level 太高, 也沒辦法任意變更 Granularity, 說穿了只是往往在颱風來時, 只是看到台灣整個被淹沒而已, 沒辦法調整 Granularity 來看自己居住地區的最近幾小時情況. 雖然也有提供即時影像, 但是一來都是定點, 同時一下子又把視野調到太小, 參考度其實也不高.
我相信中央氣象局手上握有的資料一定比利用衛星雲圖給一般民眾看到的更多, 只是受限於經費以及技術限制, 沒辦法在網頁上提供更先進, 更詳細且好用的 Visualization 介面給訪客.
既然如此, 是否中央氣象局應該考慮採用整合既有的技術, 例如 Google Earth, 作為平台, 附加屬於中央氣象局的有用資訊呢 ?
目前 Google Earth 已經可以讓使用者即時觀察颱風以及颶風等天氣狀態, 並且上面可以看到許多有用的天氣資訊, 如果中央氣象局可以讓資訊部門成立一個小組負責把中文化的資訊整合上去, 我相信只有初期會花比較多心力, 之後就會很輕鬆.
甚至當 Google Earth 的 3D 化成熟之後, 將可以進一步把颱風的面貌用 3D 的圖像顯示, 這樣應該有助於一般民眾對於颱風強度以及危害的認識與警覺性, 而不是僅透過一些聽不懂的數據去了解颱風. ( 以下圖片引用自 Google Earth Community )
 |  |
Audi's Travolution, Towards Future Traffic Control : Act After Negotiation
德國汽車大廠 Audi 開始在試驗名為 Vehicle-to-Infrastructure (V2I) 的交通控制概念, 名為 Travolution -- 顯然地是 Travel + Evolution 的併詞.
最近釋出的初期產品是透過在 Traffic Light 上安裝可以透過無線網路回報目前 Traffic Light 狀態的裝置, 使得安裝在汽車上的提醒裝置可以進行計算, 並告知駕駛員應該減速或加速到多少, 以便能夠一路上不會遇到紅燈, 以最有效率的方式駕車.
不過從新聞稿中看不出此裝置是否會考量現實的交通狀況, 畢竟在車量多時要駕駛到指定的速度有可能是辦不到的事. 相關的新聞可以參考 AutoBlog 以及 Traffic Technology Today. ( 以下圖片取用自 AutoBlog )
我覺得從 Audi 的這項產品可以看到, 相對於期待電影裡出現的車輛交通自動控制, 採取的是比較務實的作法. 基本上車輛的控制還是由人來執行, 但是車子本身則是設法提供有用的交通資訊以及建議給駕駛員, 協助整個旅程的順暢, 並消極地達成對於整體的交通控制.
透過這類的裝置, 原本不同的車子是在表現出行為之後才彼此影響, 而未來將可能是經過協調 (Negotiation) 之後, 才表現出行為, 然後造成可預期的影響. 換句話說, 也許在車子上, 此類裝置最後會給出一個 "Traffic Preview" , 告訴你這樣開的話, 五分鐘後會是怎樣的情況. 不過這需要除了 Traffic Light 與車子之外, 車子與車子之間的 Communication 才能達成.
不過這在台灣應該用處不大就是了 :p
Travel Plan Digg + SOA Travel Planning
最近要到蘭嶼去玩幾天 (8/1-8/4), 發現行程規劃實在是件有點複雜的事情.
從台灣本島到蘭嶼有搭飛機以及搭船兩種方式. 飛機的話目前只有台東機場有德安航空到蘭嶼的航班, 其他地方沒有.搭船的選擇就比較多了, 台東富岡有, 也可以從屏東後壁.
如果說旅程規劃沒有任何彈性, 事情就簡單許多, 但是選擇也相對變少. 比如說就是要從台北到蘭嶼, 然後日期就是 8/1 到 8/4, 那麼大約只剩下台北搭火車夜車到台東, 一早坐飛機到蘭嶼, 不過這樣的旅程很累 ; 或是 8/1 早上搭火車, 但是這樣到蘭嶼的時間就變成下午了.
而如果旅程規劃有很多彈性, 像是我們的規劃, 可以接受先到台東住一兩天, 然後從容地搭飛機到蘭嶼 ; 甚至可以接受先到台南待一天, 然後從台南搭火車到台東 (大約只要三個半小時), 這樣比台北到台東快上不少, 旅程也比較不會累. 其他像是先到花蓮, 再到台東等等, 都在可以接受的範圍. 這時候再考量旅館, 交通, 食物等等相關事項, 整個規劃作業瞬間就變的很複雜.
在 Web Service 與 SOA 的研究中常見以 Traveling 作為 Service & Workflow 的 Example. 常見以 Time 為根據作行程的銜接, 以及基本的條件設定, 然後加上一些進階條件的選擇, 像是不搭船, 以及 Quality 的要求等等. 這樣 SOA 的 Solution 事實上存在很多複雜度, 除了上面說的以外, 像是 Service 的狀態要能由 Service Provider 更新, 確保 Service Abailability 以及 Quality 等等.
但是若單純以 Bottom-Up 的方式去產生可能的 Workflow, 固然可以得到最多的可能性, 但是畢竟使用者要的通常只有一兩個, 因此中間就需要透過使用者的參與來降低可能的選擇數目, 這又變成了 User Interaction 的問題.
也許因為這樣的複雜度, 許多國內的旅遊服務都只停留在 Information Portal 或是 Service Portal 的階段而已, 而不是真正的 Service Provision Forge.
我認為類似的應用應該考慮利用 Top-Down 以及 User Community 來夾出可能的選擇, 進而大幅降低一般使用者的負擔, 同時確保規劃結果的品質與可行性.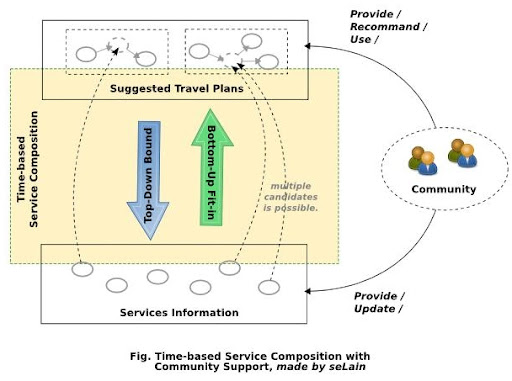
方法就是利用現成的 Travel Plan 作為 Incomplete Workflow 去套可得的 Services. 可以想像一個類似 Digg 的 Travel Plan 推薦子系統, 由一個 Community 維護. Community 成員可以貢獻自己的 Travel Plan, 作為基本的 Template, 而其他成員是以一個 Travel Plan 為單位進行推薦以及參考. 而反過來, Community 也能夠提供 Single Service 的資訊, 有利於一般 Service 資訊的更新與正確性.
當然, 免不了地 User Interface 依舊會是關鍵, 必須要能夠盡量降低使用者輸入以及推薦 Travel Plan 的 Effort, 才能夠在使用者可以得到的幫助與付出之間取得平衡. 另外必須有 Formal Travel Model, 而不是向許多旅遊網站只是讓使用者以 Natural Language + Free Style 分享旅遊心得. 既然要從使用者端取得資訊來再利用, 就應該有系統地蒐集以及使用.
不用把資訊的取得想的太複雜, 也不要期望旅途中相關的商家旅館會時時更新訊息, 單純依靠 Community 的力量來建構這樣的環境, 有效地在資訊進來之前就先篩選, 同時也讓回給使用者的規劃有最高的有效性.
Defining Operational Scalability
Wayne Fenton, Director of Architecture at eBay Inc., 在 JAOO 2007 上給了一個 Talk : Operational Scalability in the Next Generation Web World (連結內有側錄影片 + Slides), 雖然影片長達 48 分鐘, 不過內容其實很簡短, 雖然提到很多次 eBay, 但是其實內容是獨立的, 有認真上 Fault Tolerance 的人應該都很容易聽懂內容, 因為都是基本的概念.
事實上我沒有真的找到對於 Operational Scalability 較為嚴格的定義, 看看幾個從不同網頁 Copy 下來的 :
From SOA Magazine [1] :
Operational scalability is the ability of a service-oriented solution architecture to establish and maintain highly efficient and adaptive, cost effective day-to-day operations as the solution grows and scales with time. It is also represents the ability of the architecture itself to be efficiently re-factored to accommodate change and dynamic business requirements.
From Rajith’s Column [2] :
Operational scalability is a software problem and you need to think about operational concerns right from the beginning. Pay attention to,與 Rajith 類似的說法在 CoverPages 的一篇 Sybase 新聞中也可以看到, 不過搞不太清楚算是甚麼, 比較像是文宣, 就不納入參考.
- Logging metrics, Monitoring.
- Controlling/updating/tuning live apps without disrupting traffic.
Leticia Duboc 的 PhD Work [3][4] 認為 Scalability 基本上不容易也不適合有一個通用的定義, 需要視乎不同的系統以及面對不同的 Stakeholder 而異. 因此他們也建立了一個 Scalability Framework, 在不同的情況下去 Initiate 此 Framework, 定義不同的 Scaling Dimensions, Independent Variable, Dependent Variable, 以及 Evaluation Standard ( Scalability Claim ).
We define scalability as a quality of software systems characterized by the causal impact that scaling aspects of the system environment and design have on certain measured system qualities as these aspects are varied over expected operational ranges.(以下圖片引用自 [4])
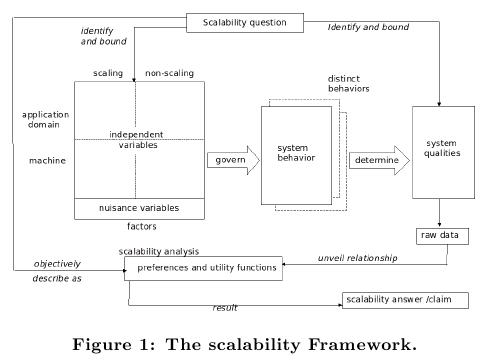
這樣我差不多可以稍稍做出結論. 基本上可以說有 Operational Scalability 這東西, 也可以說沒有. 在 [1][2] 中基本上是在特定的觀點下, 面對特定的 Stakeholder 去定義 Operational Scalability, 而其中 [1] 又更偏向一般性的 Scalability 敘述. 而在 Wayne Fenton 的 Talk 中事實上提到了許多不同的 Stakeholders, 不僅僅是一般的 Customers 而已. 因此他的 Operational Scalability 與其說是以 Stakeholders 作區分, 不如說是以 Operational Reliable Service 為中心思想, 並且放在Community 多變的 Web Service Context 下作說明.
Operational 指的是 Service 本身是必須持續運作的, 你幾乎不能考慮停止這項 Service, 必須隨時 Ready for Use, 概念同於古老的 Non-Stop System 概念. 而 Reliable 指的是 Service 可能會更新 Features, 但是不能夠因為新的 Features 而造成不可逆的改變. 這兩項在新時代的 Web Service 上更顯關鍵. 我們很容易有了想法, 很快的成立網站提供服務, 但是隨之而來的使用者人潮跟對於新功能的需求非常難以預料, 這跟過去 Software 面對的情況有顯著不同, Community 的形成之快是超乎預料的, 但是 Community 的衰落之快也同樣難以預期.
而 Operational Scalability 在此情況下, 我認為其實就是針對 Community Change 的 System Scalability.
References
[1] Ted Barbusinski, "SOA Engineering Focal Points," The SOA Magazine, Issue XIX, June 2008
[2] Rajith Attapattu, "Scaling your system - What I learnt from Dan Pritchett’s (eBay) talk"
[3] Leticia Duboc, David S. Rosenblum, and Tony Wicks, "A Framework for Modelling and Analysis of Software Systems Scalability," Proceedings of the 28th international conference on Software engineering, pp. 949 - 952, 2006 ( Syposium Presentation )
[4] Leticia Duboc, David S. Rosenblum, and Tony Wicks, "A Framework for Characterization and Analysis of Software Systems Scalability," in Proceeding of the The 6th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, ESEC/FSE '07
Beyond Single-Page Web Search Results, and ... What's The Next ? Community Page Ranking ?
本週實驗室會議由學長報告了 [1] 這篇 Paper. 其實之前我旁聽實驗室另外一個 Project 的進度會議時就已經大略看過這篇了, 不過本週趁機重新看一次, 反而有些新的想法 -- 可見得有些 Paper 時不時要多看幾次.
這篇 Paper 的基本概念很簡單, 解決的問題很小 ( 或者該說精準 ) 但很實在.
目前的 Web Search Engine 基本上是以 Single Web Page 作為單位進行關鍵字比對, 然後把符合或部份符合的 Pages 傳回, 通常會依照符合的程度進行排序 (Ranking). 不同的 Search Engine 可能會有額外的 Ranking Factors, 像是 Google 有自己著名的 Page Ranking 演算法, 另外考量商業廣告因素, 關鍵字出現頻率等等, 可以對於排序演算法再做調整.
但不管怎樣作排序跟 Page Ranking, 以 Single Web Page 為單位就會出現, 用了多重關鍵字進行搜尋, 但是沒有任何一個 Page 完全符合關鍵字組的情況. 使用者必須由列出的 Pages 之中, 瀏覽排前面數名的 Pages, 才有可能得到真正想要的資訊. 這大致符合我們的使用經驗.
Paper [1] 的想法則是, 把原本 Single Web Page 的情況, 進步到 Multiple Web Pages -- 既然我們本來就會需要瀏覽多個 Pages 來得到我們想要的東西, 為什麼不在 Search 時就直接給我 Multiple Pages 的比對結果呢 ?
( 下圖修改組合自 [1] 內容的截圖 )
因此 Paper [1] 把 Multiple Pages 結合起來成為一個 Composed Page 作為搜尋結果. 但是 Multiple Pages 也不能亂選, 否則可能造成內容事實上差距很大, 不相干的東西被包裝在一起, 因此考量了 Pages 之間應該會有 Hyperlink 的關係. 同時 Composed Page 內也要避免因為 Pages 太多不好快速瀏覽, 因此針對一個 Page, 也提供了 Query-Specific Summarize 的演算法, 藉由把一個 Page 的文字內容作切段, 以 Query 用的關鍵字組為依據, 利用 Text Information Retrieval 的方法, 以及 LSI 技術, 建立一個 Page Graph, 然後計算出具代表性的部份作為 Summary. 而多個 Pages 在 Summarize 過後進一步把 Summary 結合成為 Composed Page. 詳細的演算法在 [1] 中有說明.
從 User Query 的觀點來說, Paper [1] 注意到越來越多使用者傾向使用關鍵字組作為 Search Context 的 Abstraction, 並期望找到的資訊可以填到 Search Context 中. 而過去 Single Web Page 的作法使得使用者要自己負責彙整 Single Web Pages, 透過 Hyperlink 去找尋 ( Explore ) 更廣的資料, 然後歸納出一個有用的 Page Set 出來. 而此篇 Paper 稍微前進了一步, 在可以幫忙進行事前整理的範圍內, 先把相關的 Pages ( 可能橫跨 Websites ) 做了整理, 同時以 Summarize 過後的內容結合成一個 Composed Page, 來逼近 User 的 Search Context.
從 Single Web Page Ranking 到 Multiple Web Page Ranking ( Summarized, Composed Page ), 下一個階段會是甚麼呢 ?
Community Page Ranking 或許有機會. 不管是 Single Web Page Ranking 或是 Multiple Web Page Ranking, 基本上如果你輸入的是一樣的關鍵字組, 結果應該是一樣的, 換句話說對於所有使用者來說是一視同仁的. 這也是因為我們無法事先預測可能的使用情況 ( Search Context ), 因此只好這樣作. 但是如果可以鎖定一個 Community, 透過 Community Member 就可能定義出屬於該 Community 的可預測 Search Contexts, 這時候要更進一步對於 Pages 作事前組織就是有可能的事情. 同樣的 Pages Set 在 Travel Community 與 Local City Community, 使用同樣的關鍵字組, 可能會是得到不一樣的 Composed Page.
感覺 Google 已經開始透過 Knol 希望逐漸建立可信賴的 Knowledge Group 了, 或許將來與 Community 在 Knowledge Search 方面會有更加深入的互動.
References
[1] R. Varadarajan, V. Hristidis, and Tao Li, "Beyond Single-Page Web Search Results," IEEE Transactions on Knowledge and Data Engineering, vol.20, no.3, pp.411 - 424, March 2008
Twitter + Google Maps Should Go Beyond TwitterVision
Google Maps 現在也加上 Walking Direction 的資訊了( RWW 也有相關文章 ), 這基本上是一個必然的動作, 能夠讓地圖提供更有效率的幫助. 即便是在有了各種電子地圖後, 查閱地理資訊變得更加容易, 自動規劃路程也變得可能, 然而缺乏更加詳細的資訊卻讓許多理想的服務無法完成. 像是 UrMap 也遲遲未能提供台北縣市以外的大眾交通工具資訊, 以及路線規劃只能提供汽車, 沒辦法照顧到機車族群. 我認為問題不在於 Algorithm 的設計以及 Computation Power 的限制, 而在於 Valid Data 的取得.
像是 UrMap 也遲遲未能提供台北縣市以外的大眾交通工具資訊, 以及路線規劃只能提供汽車, 沒辦法照顧到機車族群. 我認為問題不在於 Algorithm 的設計以及 Computation Power 的限制, 而在於 Valid Data 的取得.
透過 Sensor 或是 GPS Devices 固然是一種方式, 也常用於自然災害偵測與防治以及疾病控管等大範圍監控系統上, 但是幾乎都是透過衛星傳輸資料, 要在城市中使用, 為了降低成本需要仰賴於城市無線網路基礎設施, 同時即便如此, 大量的 Sensor 裝設費用仍然很嚇人.
在這些困難下, 其實過去的警廣交通網作法, 反而是可以讓人考慮的一條路. 台灣主要道路的路況是由熱心的駕駛回報到警廣, 然後由警廣彙整略加查核後由廣播通知鄰近其他駕駛人
同樣地, 我們可以期待類似 Twitter 與 Google Maps 的結合. 透過 Twitter, 使用者可以時不時地簡短報告自己周圍的地理狀況, 然後以 Google Maps 作為具體呈現的平台, 廣播給大家知道. 已經有類似的服務在 TwitterVision 被實現. 相關的主題也可以在 Google 上利用 "Twitter Google Maps Mashup" 作為關鍵字找尋, 有相當多的討論.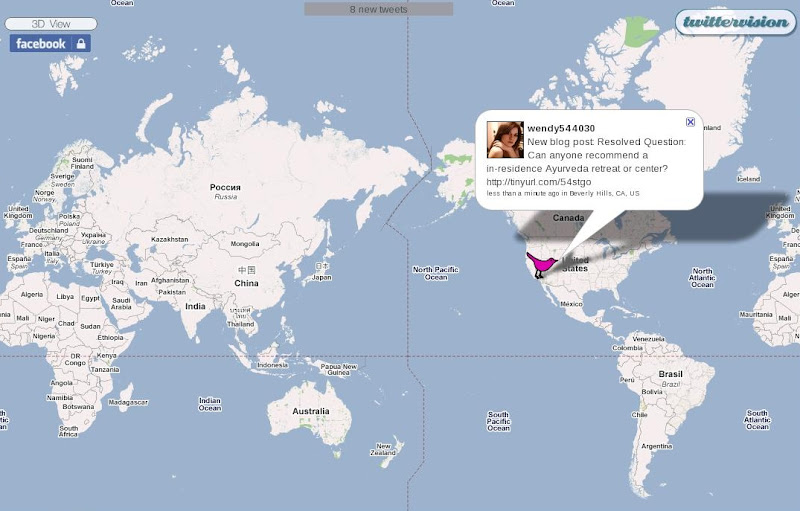 然而 TwitterVision 也只是讓 Twitter + Google Maps 發揮 1 + 1 = 2 的效果而已, 我們需要讓 1 + 1 > 2 .
然而 TwitterVision 也只是讓 Twitter + Google Maps 發揮 1 + 1 = 2 的效果而已, 我們需要讓 1 + 1 > 2 .
透過 Twitter 而來的 Message 或是 Media (Photo, Vedio Clip, etc) 應該可以在使用者輸入時先作簡單的分類或是 Tagging, 然後在後端利用 Semantic Analysis & Semantic Web 以及 Image Recognition, Image Classification 對於這些資料根據 Google Maps 的基本地理條件 (Constraints) 作彙整, 針對不同使用者的使用需求, 提供即時的相關資料整理.
交通以及路況就是一個很容易處理的應用. 只要在輸入者提供一些簡單的 Template, 很容易就能得到使用者身邊有用的 Data, 然後就能夠整理成該地區有用的交通及路況資訊. 當然, 這依舊仰賴於無線網路基礎設施的鋪設, 以及手持式電子裝置的普及 -- 不過話說回來, 這時代有哪項網路服務不是建立在這樣的預想 (Assumption) 之下 ?
期待很快能看到這樣的 Product 出現 :)
Something about Cloud Computing : 軟體產業的二次分工 ?
RWW 上的一篇文章 : Reaching for the Sky Through The Compute Clouds, 我覺得寫的不錯, 算是從一個容易理解的角度說明 Cloud Computing. 同時他提出 Google Data Cloud 的例子來輔助他畫出的 Clouds 概念圖增加不少說服力. ( 不過 You vs Them 段落之後感覺有點混亂, 不是很能同意 )
其中請注意到底下回應中, Avner Algom 的回應 ( No.15 ). 為了紀錄方便, 完整轉錄 (稍加編排) 如下 :
It is to remember that without the convergence of grid, virtualization and SOA concepts, the cloud implementation cannot be done. In fact, the Cloud Computing concept is a Grid based business model that provides utility Computing services and/or SaaS services目前來說, 我傾向認同這樣的歷史觀點, Cloud Computing 並非技術面上的突破, 而是技術面上的成熟代表. 然而, 僅僅是相關技術的成熟, 有必要 Google 大張旗鼓的推廣此概念嗎 ? 僅僅是為了對於顧客的商業包裝, 推廣相關技術到一般人面前嗎 ?
Terminology Synch:
- Grid provides the Service-Oriented Infrastructure Virtualization (SOIV) that enables IT scalability and flexibility
- Service Orientation - Service-orientation is a design paradigm that specifies the creation of automation logic in the form of services. It is applied as a strategic goal in developing a service-oriented architecture (SOA).
- Virtualization - a technique for hiding the physical characteristics of computing resources from the way in which other systems, applications, or end users interact with those resources.
- Utility Computing – Pay-per-Use for network based Compute and Storage services
- Software as a Service (SaaS) - Pay-per-Use for network based software applications’ services
我覺得除了把 Cloud 跟過往 Network 上的雲狀圖示作聯結之外, 是否應該想想取用 "Cloud" 這個字所隱含的意義呢 ?
在 Webster's Dictionary 上可以查到下面的解釋 ( 只取較為相關的部份 )
1. Any collection of particles (e.g., smoke or dust) or gases that is visible.
2. A visible mass of water or ice particles suspended at a considerable altitude.
3. Out of touch with reality; "his head was in the clouds".
然後我們又知道, Cloud 的形狀, 大小, 高度, 都會因為各種氣候條件而有所不同, 如果再結合 RWW 文章中的這張圖, ( 引用自 RWW, 由 Alex Iskold 繪製 )

霎時卻讓我想到了, Cloud Computing 從軟體工業的角度來說, 或許代表的是軟體產業的二次分工.
第一次分工是著重於軟體製造業的分工, 從 System Design, Software Analysis & Design, 到 Implementation, Testing 的分工. 這在目前世界軟體產業已經是普遍的模式, Global Software Engineering 也早已被討論多時.
而我所指的軟體產業的二次分工, 則是軟體服務業的分工.
上圖中的各種 Cloud 都可以被視為是一群提供相關服務的業者 ( 服務提供者, 未必是真實人類 ) 所組成, 但是與單純的 Service Group 不同的是, 在此 Cloud 內的 Particles ( 服務提供者 ), 必須遵守同樣的 Protocol 規範, 包含 Interface, Quality 等等, 因此對於採用該 Cloud 服務的顧客而言, 面對的是整個 Cloud, 而非單一個服務提供者.
這個觀點相信也與 RWW 的該篇文章(特別是 You vs Them 段落), 以及網路上的許多文章應該是相容, 只是從產業改變的觀點來說.
不過必須再加說明的是, 我不認為此分工模式會導致軟體服務創意被壓縮. 事實上, 這種分工模式是一個把餅做大的分工模式, 而不是為了要做出很多不同口味的餅. 在此情況下, 最大的得利者會是開發出新口味大餅的業者, 其次則是某種口味大餅做的最好賣得最好的業者, 最後則是勉強作一種口味的大餅可以餬口的業者. 而 Google 跟其他在推 Cloud Computing 的業者這當然是前兩者 :)
Linux 市佔率提昇的影響 ?
前陣子 Acer 自打嘴巴地推出了 Aspire One, 加上今天看到了 ComputerWorld Blog 上的這篇文章 : PC Vendors Want to Sell You Desktop Linux, 其實很顯然的, 在 EeePC 的成功之後, 不僅是在 Desktop PC 上, 各種 NB, 小 NB, Mobile Device 上, 廠商業者考量採用 Linux 的傾向得到了更為強烈的市場反應支持, 加上 Desktop Linux 系統的成熟, 產品廠商在付出額外的 Desktop Linux 修改成本與降低銷售成本以提高顧客購買率與競爭力之間, 只要能取得有利的平衡, 就是對於他們可行的方案.
反正, 改用搭配 Desktop Linux 是一個進可攻退可守的方案, 君不見 EeePC 還是會推出附有 Windows 的版本嗎 ? 甚至更奸詐的把改裝 Windows 的選項留下來, 任由顧客自己去找盜版的 Windows 進行重新安裝. 或許有很多人是會改裝回 Windows, 不過不管如何, Desktop Linux 的市佔率提高是一定的事情, 只是速度快慢而已.
乘著這個趨勢, 可預見的, 產品廠商還是會持續的考慮採用 Linux, 除非 Microsoft 釋出更有利的方案. 而這會形成一個有趣的現象, 這些本來是整合硬體跟軔體, 然後採用 Microsoft 軟體的產品廠商, 會不會開始做起軟體 ( OS, Desktop, Apps ) 的部份呢 ?
ASUS 的 EeePC 在軟體操作介面上並不是只套用常見的 Linux Desktop, 而是再進提供了 Easy Mode, 以 Task-Oriented 為主. 雖然不是創新的設計, 但是怎麼說也是自家要做的東西, 變成了整個自家產品開發的一部分. 過去我們買 NB 時在 OS 方面沒辦法比, 因為都是一樣的系統跟介面, 所以幾乎都是比同樣價格下硬體的規格, 穩定度, 主要用途適用性, 售後服務等等. 但說穿了, 除了售後服務, 其他大概都差不多, 一般使用者也鮮有機會感受到差異.
但是 Software 就不一樣了. 光是 Desktop 使用介面的設計的差異就會造成使用者極大的不同感受, 更別說對於使用者安裝新軟體的便利性以及常用軟體的穩定性. 這些都會比其他方面對於使用者造成更直接更巨大的影響. 也許在這方面沒有一家公司可以取得獨特的領先地位, 但是誰也不敢落後太多吧 :p
在此考量下, 不知道這些產品公司會不會開始成立自己的軟體部門--有別於過去只有處理軔體跟驅動程式, 以及 MIS 的部門, 而是會負責建立或是修改 Open Source OS, Desktop, 以及 Apps 的部門. 或是採取外包的方式, 有專門的軟體公司來與這些產品公司合作進行 Customization, 就跟過去 Microsoft 的角色一樣.
Either way, Software Rules. ^^
從LED七段顯示器 到 用宿舍燈光玩貪食蛇
昨天經過別人的推薦在 YouTube 上看到芬蘭學生利用宿舍大樓玩貪食蛇的影片. 在 YouTube 上利用PIOW 或是 P.I.O.W. 作搜尋可以找到應該是同樣的一群人玩的其他花樣.
這其實不算是甚麼新的東西了, 也常看到夜晚利用商業大樓作同樣的事情, 像是求婚, 假日煙火節慶等等.
雖然不是很清楚背後的工作原理, 不過對於電機資工學生來說應該也不難想像. 比較笨一點的就是在電燈開關上裝設可程式控制的電機裝置, 但是這很麻煩, 也可能會破壞原本的電燈開關設施. 或者我們可以製作簡單的嵌入式設備, 結合電燈以及可程式化的 IC 版作控制. 但是這會有同步的問題, 很可能無法做到影片中那麼完美.
不過呢, 加上個簡單的 Wireless 裝置, 利用一台 PC 作 Server 來發出命令給所有房間內的嵌入式電燈裝置, 應該就差不多可以做到類似的事情. 如果需要不同的顏色, 可以在一個房間內準備多個電燈設備, 或是複雜點利用多顏色的電燈, 一樣透過程式控制.
想起來很複雜, 不過其實只是中間加上了不同的 Components 接起來而已, 基本的控制概念與想法, 其實跟所有電機資工學生大概都會碰過的七段顯示器控制, 其實沒什麼兩樣. ( 圖片取用自這裡 )
不過有多少電機資工大學部學生, 會聯想到七段顯示器呢 ?
不過反過來說, 這也未嘗不是一個好的教材. 可以把簡單的七段顯示器控制, 加上 Wireless 網路概念, 馬上就可以讓學生玩一樣的事情. 去建議系上的微算機實驗課程, 把簡單的七段顯示器控制換成這個好了, 然後期末要利用電機大樓玩一樣的事情 :p
搞不好幾年後會出現學生用這招在學校裡玩告白 XD
也是一種 Biosignal Decvice
或許該說是 Behavioral Biosignal Device 比較貼切 ?
根據 Engadget 的報導, 一家名為 Airun Plus 的公司準備發佈一款特殊的運動鞋, 針對一般運動員設計了 BMI 計量以及卡路里熱量消耗計量, 同時還具有走路時的重力 ( 應該是指施加於鞋子的壓力吧 ) 與速度感應器. 可以協助運動員或是一般人的運動計畫成效, 同時避免腳部因為過大的壓力而受傷. ( 圖片引用自 Engadget )
我在想這個運動鞋除了自身的功能之外, 如果他的偵測資料可以從外部下載, 或是由他主動上傳到外部的裝置, 這也可已是一個十分有價值的 Biosignal Device.
除了熱量消耗資料外, 像是走路運動時的速度以及腳步承受的壓力, 其實一般人進行一般的運動行為時, 固然有可能因為瞬間的壓力過大而受傷, 因為長時間姿勢不正確或是習慣不好, 導致慢性傷害的也不在少數. 同時慢性傷害往往更加難以復原,
對於可能進行中的慢性傷害, 將可以透過分析一般的運動行為, 像是日常走路, 來作可能的偵測與預防. 不過針對於一雙鞋子來說有點負擔太大了, 再說常走路的話, 其實一雙運動鞋大概一年多就要換一次, 還有人是每天刻意要換不同的鞋子. 透過外部的生理訊號分析, 可以整合到同一份資料中, 還可以跟其他相關的生理訊號作結合, 應該還是比較正確的作法.
Document Built-In Formation Test
昨天幫一個學弟進行碩士口試的 Dry Run, 投影片裡面要改正的小缺點相當多, 雖然說我當初在準備碩士口試時也是有不少地方需要修改, 不過倒沒有像學弟一樣出現很多有點離譜的錯誤 -- 以我們實驗室兩年的 Training 來說.
這種同 Hierarchy 字體大小不一, 條列式內容的標示混雜地以數字跟符號組成, 同時並沒有特殊意義. 還有同一頁的文字表格太多太雜等等問題, 表格文字超過虛擬邊框 (Soft Boundary) 等等.
現在的編輯軟體大多有提供 Spell Checking 功能, 可能是自身內建的, 也可能是利用外部的 Spelling Checking Component, 像是 GNU Aspell 等等.
雖然說可以利用建立 Template 來軟性規範一些可能出現的 Inconsistency, 但是手殘的時候還是有可能像是上面的 Format Inconsistency.
不知道是否在編輯軟體上, 可以支援對於特定 Document Template 加上 Built-in Formation Test, 來確保 Document 中不會有不經意的 Inconsistency 出現. 像是同一個 Hierarchy 的文字大小, 粗細設定以及字體應該一致, 同一頁的文字數量以及行數應該小於某個數值, 甚至可以根據整頁的字數跟圖的複雜度所含的資訊量作檢查, 避免同一頁的內容太多且雜.
其他一些投影片製作的 Rule of Thumb 或許也可以變成一些 Tests 來協助製作在 Formation 上具一定水準的投影片.
利用 Twiddla 遠距討論 Design Diagram
Twiddla 是一個免費的電子白板服務, 之前為了跟在美國的學長討論 Paper 上的 Architecture 圖, 其實在 Survey 時有注意到, 但是當時以為只是普通的畫圖用電子白板, 鑑於畫起 Design Diagram 實在太累, 加上動作過快會讓網頁上的 JavaScript 陷入暴走狀態, 把整個 Browser 鎖死, 因此後來沒考慮使用 Twiddla.
今天看到 Library Views 圖書館觀點 的一篇介紹文章, 才發現原來 Twiddla 可以開啟特定的網頁網址, 在上面進行文字或畫圖註解討論. 這樣一來問題就好處理多了, 可以先把要討論的 Design Diagram 放到一個可以取用的 Web Server 下, 然後再利用 Twiddla 去開該檔案的網址, 就可以當作底圖進行討論, 畫註解等等.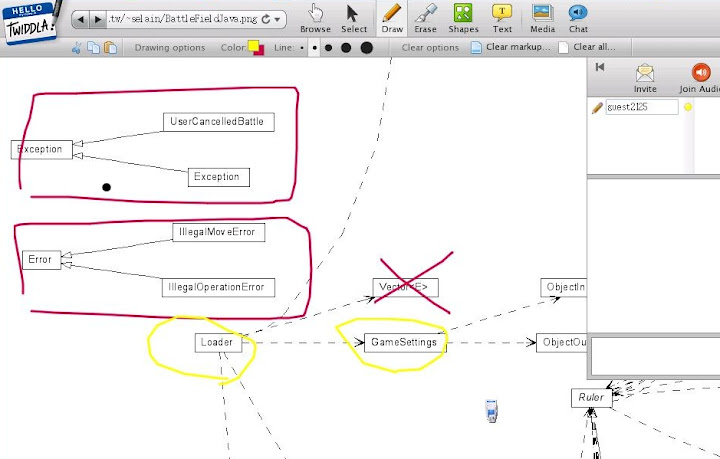
在技術面上, Twiddla 有利用 Scribd 的 iPaper 的服務, 把許多不同的檔案格式轉成 Flash, 因此可能可以直接開啟, 然後在上面討論. 嘗試了幾個不同的常用 File Format, 像是 Python Source Code 會被當作普通的純文字檔轉成 Flash, Block 會亂掉, 沒辦法好好看 Code. 而 PDF File 可以開, 但是非常 lag, 相對來說 OpenOffice 檔案倒是還好.
這樣 Twiddla 加上 SkyPe 以及各種 IM Software, 基本上就可以是窮人版的 Web Meeting Solution 摟 :)
Multi-Languages Adapter
不是正式的 Pattern Documentation, 只是隨手記記, 這種情況其實還蠻常遇到的. 但需要進一步討論的是, 如果我們說 Programming Languages 的選擇決定通常是在 Design Phase 末期或是 Implementation Phase 初期, 那麼這個情況是否 應該出現 呢 ? 而如果出現了, 是否下面的 能夠使用 呢 ?
Context
Used when components developed in different programming languages, which with low interoperability between each other, have to communicate and collaborate together.
Solution
Use a common infrastructure as a language-independent third party media, and develop a common protocol as communication standard.
The ProtocolAdapter is responsible for maintaining the Protocol, translating language-specific message into message under Protocol, and vice versa.
Example
An example using socket and TCP/IP network is illustrated bellow.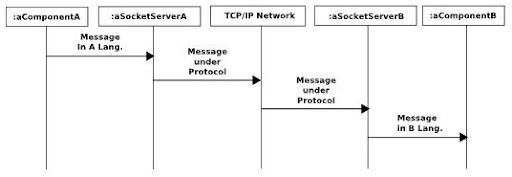
Consequences
- Increase the reuse of components implemented in different programming languages.
- The language-independent third party media usually contributes to constraints on usage of the applied application. Usability may be somewhat sacrificed.
- There will definitely be performance issues.
- Mediator Pattern
- Adapter Pattern
街頭垃圾壓縮機 與 Service-Oriented Computing
在癮科技看到的這篇新聞 : 費城將在街上設置垃圾壓縮機 很有趣, 等同於是把小型的垃圾車放置在城市中固定的地點, 透過科技的進步來增加垃圾收納量, 以及降低環境污染度, 克服過去公設垃圾桶會有的許多缺點.(以下圖片引用自 KYW Newsradio)
 |  |
過去在談論 Service-Oriented Computing 時, 我們似乎都會很自然的想到各種商業應用, Shopping Services, Business Services, Travel / Hotel / Transportation Services 等等, 然而回歸到現實面, 其實還有很多非常小, 但是很實用的 Services 經常就被忽略.
像是很常遇到的, 走在街上, 可能是因為剛剛買了小吃, 飲料, 或是打噴嚏的衛生紙, 很容易的手上就會有想丟掉的垃圾. 如果是在不熟, 非生活圈的地方, 一時之間要找垃圾桶就不是如此容易的事情. 如果費城的垃圾壓縮機可以在 Service-Oriented Computing 基礎設施上搭配提供這種 垃圾 Service, 應該會讓計畫的效果更好吧.
這種 垃圾 Service 看起來很小很無聊, 可是需要的時候功用卻是很大的.
Keep Watching : Software Quality Observatory for Open Source Software (SQO-OSS)
記得大約是兩年前作 OSS Quality Measurement Project 時看到 SQO-OSS 這個計畫網站的, 當時裡面還甚麼都沒有, 但是畫了很多 Vision 的大餅. 同時間注意到的還有 Ohloh.net ( 之前文章 Assessing Open Source : Ohloh.net ). 後來 Ohloh.net 陸續公佈了許多新的功能以及介面調整, 而 SQO-OSS 不愧是學術計畫, 一直停留在只聞樓梯響的階段.
而現在, Finally, SQO-OSS 也進入 alpha-testing 的階段了, 公佈了一個 Quality Checking Tool, 名為 Alitheis Core. 不過 Demo 網站好像掛點了, 真是不太捧場阿 :p
雖然 Demo 掛點, 不過需要的話可以下載 0.8 或是 0.8.1 的版本, 在這裡可以找到. ( 主要開發語言是 Java, 大心 ^_^ )
Alitheia Core 的 Architectural Overview 可見下圖 (引用自 SQO-OSS 網站 ). 其實並沒有甚麼特別的地方. 值得注意的是此頁的 Title 是寫 Alitheia Core and Metrics, 但是圖中沒有出現 Metrics, 因此也不確定是用在 Information Extraction 或是 Data Mining 的部份. 不管怎樣, 整個系統的運作其實不難理解.
在 Source 裡面的 Metrics Package 含有很多 Sub Packages, 甚至包含 Productivity Metrics. 不過細看很多內容都是空的 ( 這是怎樣 = = ), 也許正在實做中吧.
既然玩不到 Demo, 改來看看公開的 ScreenShots ( Alitheia Core 0.8.x ) 也好. 但其實從 ScreenShot 看來也蠻讓人失望的.
是的, 看起來有很多 Metrics 可以安裝來用, 但是從 Source Code 以外的 Project Artifacts 進行分析的部份看起來還是缺乏. 而即便是已經有的 Metrics, 在能夠連結到更 High Level 的意義之前, 我想對於 OSS Community 的吸引力也不是很大.
不過不管怎麼說, 人家也是有 Product 了, 我們實驗室的還在難產中. 加油吧~~
Borland's New Tools : TeamDemand, TeamFocus, and TeamAnalytics, to Make SDP More Transparent
Borland 今天正式公佈了三個預計於秋季釋出( release ? 販售吧 :p )的新工具. 詳細情況可以參考 Computer World 的這篇新聞 : Borland adds tools aimed at making application development more transparent.
三個 Tools 分別為 :
- TeamDemand : 這個是三個 Tools 裡我覺得最沒想到的. 企圖把 User Requirements 連結到 Development Tasks 以及 Development Process, 想要提供 Business Users ( Customers ) 一個可以即時 ( Real-time ) 獲知目前進度的溝通管道. 我認為這要做得到其實不難, 但要做的好不容易. 簡單的來說, 能夠讓 User 根據 Requirement 隨時輸入 Test Cases 其實就成功一半了, 接下來只要自動找到相對的進度作 Testing 就是另一半, 不過這之間都還隱藏許多問題.
- TeamFocus : 看來應該是用來連結 Developers 使用的 Tools, 彙整相關的 Information, 產生開發過程中的相關 Reports. 預計可以大幅降低 Developers 需要花時間在整理 Intermediate Report 的時間.
- TeamAnalytics : 根據 Project 內部可以獲得的各種 Information, 結合在特定 Domain 下適用的不同 Metrics 組合, 量測出 Project 目前的狀態, 對於不佳的情況可以事先給予 Warning. 尚不知內部怎樣管理 Metrics,不過如果是用類似 GQM 方法的話, 應該可以想像 Goal 沒有達到預期就是一種 Warning 了.
Borland 真是 IDE 界的巨人阿~~
Will Dual-Touchscreen Brings More Issues to the GUI Design ?
今天看到 Laptop 的這篇文章 : V12 Designs’ Dual-Touchscreen Notebook Coming within Two Years, 裡面提到 V12 Design 的 Dual-Touchscreen Notebook.
這怎麼說呢, 雖然乍看之下就是兩片 LCD 螢幕合在一起, 然後其中一片可以用作鍵盤顯示以及使用, 理想的話還會有 V12 Design 宣稱的感應回饋 ( Haptic Feedback ) 能力, 但是把 Notebook 上鍵盤那側變成 LCD 所帶來的 User Interface 改變還是很巨大的. ( 以下圖片引用修改自 Laptop )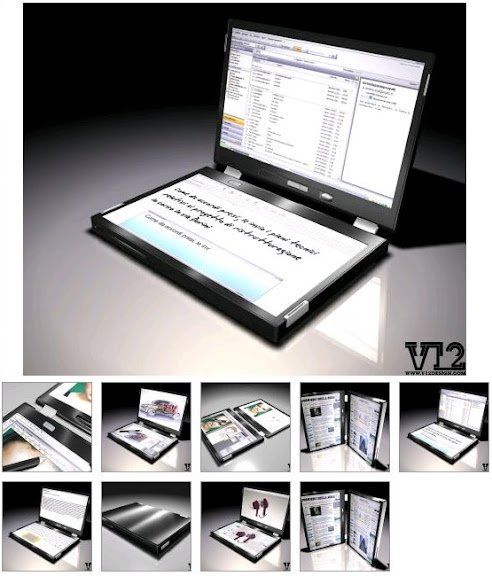
把目前的 Notebook 具有固定式鍵盤, 到 Optimus Maximus 萬鍵之王的想法, ( 以下圖片取用自 Optimus Maximus 網站 )
再到 V12 Dual-Touchscreen, 硬體輸入裝置給了 Software 越來越多的自由. 在萬鍵之王上, Software 可以更加容易的改變按鍵的定義跟配置, 這在之前需要具備一定電腦知識的使用者才能辦得到. 而在 Dual-Touchscreen 上, Software 將甚至可以自行定義輸入用的 "鍵盤" 長甚麼樣 ( 如果他還長得像鍵盤的話 ), 而且不像過去會佔用到 Software 用來呈現 Data 的空間.
Software Usability 與 System Usability 的定義之間或許會更加的模糊, 真難想像這是會帶來無限的可能還是混亂 :p ( 更別提 Multi-Touch Screen 摟 ~~ )
Realtime Mining Applied
上學期修課跟學弟合作的一個期末計畫是建立一個巴士系統的 Embedded Middleware. 目前這東西也慢慢延伸變成學弟的 Master Research. 在整個 Vision 中, 有一部分就是關連到即時地蒐集巴士系統中 Customer 相關的資訊, 以及整理分析這些資訊, 產生出足以作為決策支援的資訊 ( Structured Information ).
類似的東西已經開始有人用 GPS 得到的資料做出 Prototype 來摟.
6/22 的 NY Times 報導了此一 Prototype : Predicting Where You’ll Go and What You’ll Like , 由 Sense Networks 這家公司開發 ( 我覺得他們名字取得不錯 ) . 基本概念是利用 GPS 得到 Location Data 以及 Movement Data, 然後透過適當的 Mining Algorithm 分析, 就可能得到關於行為模式的猜測結論. 在文章中期時也提到, 可以用來被追蹤 (Track) 的東西很多, 不見得只有 Location 可以用來追蹤猜測人們的行為. ( 以下圖片引用自 Sense Network Media Center 公開資料, 上面還有 Vedio 可以下載 )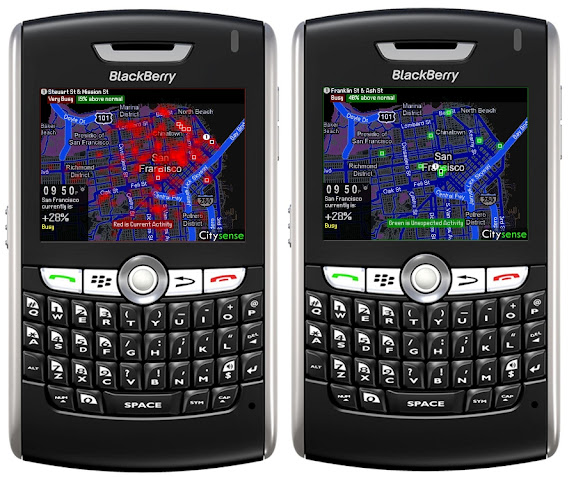
Realtime Data Mining 技術本身其實不是困難點, 困難的是怎樣讓整個 Process 可以真正應用到商業行為中使用. 期間需要考量的, 整合各種軟硬體設施, 同時城市無線網路的基礎也不可或缺. 另外就是使用者願意曝露自身資料的意願.
不過從過去的成功經驗來看, 其實這個世界的人們對於自身的資料隱私其實不是真的那麼在意 -- 只要有利可圖的話.
Sense Network 做出了很合理且聰明的決定, 他們不是一廂情願的向使用者買 Data 或是期望使用者會自動主動提供資料. 而是利用提供給使用者相關服務來換取資料 ( 原文為 : Sense decided to trade services for data. ) 而 Sense Network 自然可以從操作廣告以及服務之間得到適當的利益. 從 Google 以來, 這似乎已經是 Web 2.0 唯一具有足夠商業成功案例的模式了.
但是 Sense Network 是否能夠獲得足夠久的成功卻還很難說, 相當仰賴於他們的商業操作手段. 使用者的 Location 資料並非是會有長久價值的資料, 其 Lifecycle 可能只有短短的數個小時, 因此 Sense Network 不可能像是某些 Blog Supplier 一樣透過累積大量的懶惰使用者讓自己不倒, 而就算是在 使用者 <-> 手持裝置 <-> 位置及其他資料 <-> 可得服務 的 Cycle 中, Sense Network 也不是居在任何不可取代的位置. 因此一切都還很難說.
唯一能肯定的是 Realtime Mining 相關應用的這個趨勢應該確實會發生.
BASE : An ACID Alternative
上個月的 ACM Queue 趕在最後幾天刊出了 Dan Pritchett, Technical Fellow at eBay, 的一篇文章 : BASE: An ACID Alternative.
BASE ( Basically Available, Soft State, and Eventually Consistent ) 相對於傳統的 ACID 以強調 Consistency 為主, 改為採用犧牲 Consistency 來換取 Availability 的概念.
基本上 Consistency 跟 Availability 常常是唱反調的, 因為要確保 Consistency 免不了需要在每個動作之前進行妥協 ( Negotiation ) 或是動作之後的檢查, 例如經典的 Two Phase Commit ( 2PC ), 而這就會傷害到 Availability. 在 BASE 的方法中, 把 Consistency 的檢查做了延遲, 先允許部份動作的進行與 Commit, 等所有的動作完成之後再設法確認無誤.
在文章中舉了一個例子 : 在 eBay 上有兩個角色, Seller 以及 Buyer. 當 Seller 把商品賣給 Buyer 之後, 首先要更新交易紀錄表, 再來兩邊的 Account 資訊都要進行更新 ( Schema Design 請參考文章 ). 在傳統 ACID 的角度上來說, 通常這些動作會收集在同一個 Transaction 內部, 只進行一次 Commit, 確保兩邊 (交易紀錄表以及使用者紀錄表) 的 Consistency. (以下範例及圖片引用自 [1] )
而 BASE 的作法則是, 把交易紀錄表的更新與使用者紀錄表的更新分開, 變成數個 Transactions. 首先進行交易紀錄表的更新 Master Transaction, 然後再執行兩個更新使用者紀錄表的 Sub Transactions ( Seller 以及 Buyer ). 在 Master Transaction 中除了更新交易紀錄表之外, 事實上還發出了進行接下來數個 Sub Transactions 的要求到一個 Message Queue 中, 然後進行 Commit. 而在 Message Queue 中的 SQL Statement 則會在之後個別以 Transactions 作包裝進行 Commit. 基本概念大略是這樣, 文章後半段還有討論到 Peek Queue Message 以及 Remove Message 的細節, 以及使用 SQL Statement 作整個敘述上的簡化.
基本概念大略是這樣, 文章後半段還有討論到 Peek Queue Message 以及 Remove Message 的細節, 以及使用 SQL Statement 作整個敘述上的簡化.
BASE 的作法當然可能在 Sub Transaction Fail 時引起 Inconsistency 的問題, 但是透過適當的 Traceback 機制, 我想應該可以快速的作 Error Recovery, 例如在 Master Transaction 送出的 Messages 上標記特殊的 Tag, 一旦出問題就可以追蹤到所有相關的 Transactions. 但是文章內容沒有對 Error Recovery 的處理部份著墨太多.
BASE 的應用關鍵我認為是在 Transaction 的結果事實上是應對到不同的使用者上, 包含 eBay 系統本身, Seller 以及 Buyer. 由於並非同一個角色, 因此在這些 Transactions 進行時所實際短暫產生的 Inconsistency 不會被三者察覺到 ( 除非 Seller 跟 Buyer 即時溝通確認 Consistency ). 而技術上來說, BASE 也沒有刻意隱藏 Temporal Inconsistency 的事實, 只是當 Seller 與 Buyer 角色分開時, 他們各自無法透過 Partial Information 去推知 Inconsistency 的發生罷了 :p -- 當然, 這也暗示了 BASE 的應用領域相較於 ACID 來說是會比較受侷限的.
從這點回頭來看這篇文章被放在這期的 ACM Queue 是很有趣的事情. May /June 這期的 ACM Queue 主題是 Object-Relation Mappers. 其他三篇文章都在講 ORM, 唯獨這篇殺出 ACID 與 Consistency/Availability 的問題. 是意外嗎 ? 或是 BASE 的方法事實上是把 eBay System 中的 Objects 與其 Behaviors, 給 Mapping 到了 Relational Database 中了 ?
References
[1] Dan Pritchett, "BASE: An ACID Alternative," ACM Queue, vol.6, no.3, May/June 2008, visit online version
Tool Support for the Navigation in Graphical Models
這篇 Short Paper [1] 以及所建立的 Tool ADORA, 包含重點大致可以歸納為兩點.
首先是使用 Fisheye View 的概念改進目前大部分 Tools 在協助使用者瀏覽整張 Software Design Diagram 時的問題. 既有的 Tool 在面對相當複雜且巨大的 Diagram 時大多無能為力, 往往需要使用者自行將 Design Diagram 從 Object Analysis ( 如果是在 OO Paradigm 中 ) 以後, 分為 Class Level 0, Class Level 1, ...... 等詳細程度不同的數張 Design Diagrams, 方便在不同的 Abstraction Level 間切換. 少部份 Tools 可以自動隱藏 Details, 但是當進行 Zoom In / Zoom Out 時卻是會對於整張圖作變化, 無法自由地只 Zoom In 想要進一步觀察的部份. Fisheye View 則讓此操作方式成為可能. ( 以下 ADORA 圖片皆取用自 [1] 並稍加編輯, 且無修改圖片本身內容 )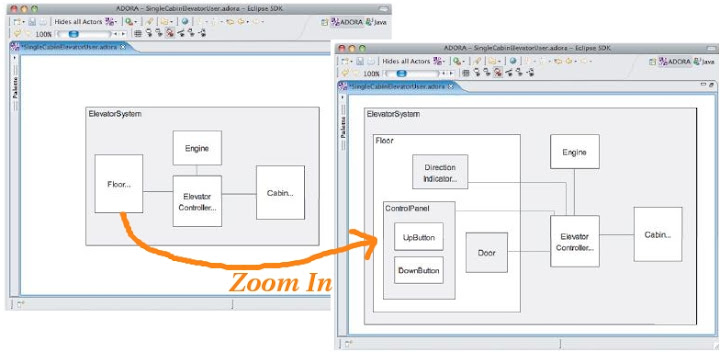
關於第一點在去年底我們實驗室有一位同仁在進行實驗室會議報告 Paper 時也有提到類似的概念, 當時他是用 StarCraft 當作例子, 在 StarCraft 中同時有主操作畫面 ( Local ), 以及左下方的微縮地圖全圖 ( Global ), 來說明如果 Design Tool 有類似的支援好像不錯. 當時大家討論都集中在使用方式上, 看了 [1] 的實做, 好像在 Layout 計算位置上也不是那麼容易實現, 畢竟要兼顧到整張圖的 Re-arrangement, 不能因為 Fisheye 使得整張圖亂掉. 我想這也是 [1] 裡面要強調可恢復性 (Stability) 的原因. ( 以下 StarCraft 插圖引用自 http://spyhunter007.com/game_over.htm )
第二是對於 Single Integrated Model 的理想. 在 Paper 尾段嘗試性的把不同時間點的一些 Diagrams 疊合在一起, 包含 User & Context, Use Case Diagram, 以及 Class Diagram. 可以想見的, 這樣一來就可以透過 ADORA, 在 Software Development Phases 之間快速自由的移動, 瀏覽相關的 Analysis Diagrams, Design Diagrams.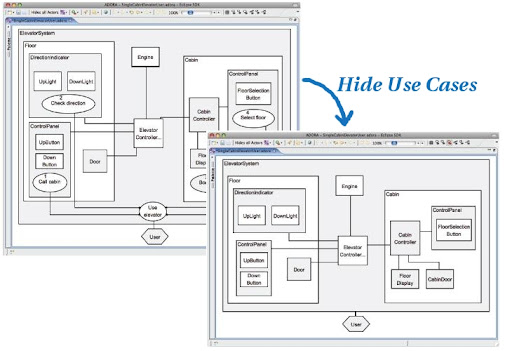
不過我認為 Single Integrated Model 的需求, 使用時機及模式, 以及呈現方式都還有很多探討的空間, 在本篇 Paper 中也沒有再著墨太多. 像是上圖左, Use Cases 跟 Classes / Components 混在一起的感覺就很奇怪, 也沒有因此曝露更多 Information. 如果改用 Use Case Map [2] 來作整理可能會好點. ( 話說 Use Case Map 是怎樣, 不紅到原本的介紹網頁都消失了, 現在只依附在 jUCMNav 底下了 XD )
或許之後在 Software Design Tools 中會出現更多這種 Visualization Information Mash-Up 的應用.
References
[1] T. Reinhard, S. Meier, R. Stoiber, C. Cramer, and M. Glinz, "Tool Support for the Navigation in Graphical Models," Proceedings of the International Conference on Software Engineering, pp.823-826, 2008
[2] R. J. A. Buhr and R. S. Casselman, Use Case Maps for Object-Oriented Systems, Prentice-Hall, 1995
My Activity, My Life Calendar, My Swurl: Operating the Lifestream
跟隨著 RWW 文章 Swurl: Your Lifestream, Made Beautiful 的腳步去試用了Swurl -- another Lifestreaming Service.
基本功能上其實沒有甚麼好說的, 跟 FriendFeed-like 的 Services 雷同, 甚至可以說現階段功能上不如 FriendFeed 來的好. 但是我喜歡他的 Visualization, 雖然概念簡單, 但是很強大.
Swurl 並非像 FriendFeed 一樣只是把蒐集來的資訊依新舊排列, 而是再多提供了一個類似 Calendar 的整理方式, 以時間軸, 只紀錄有活動天數, 形成一個 Life Calendar Matrix. ( 以下借用 RWW 文章的圖, 我的只有文字不太好看 :p )
Visualization 的目的一般是為了把 Invisible Information 變成 Visible.
在 Swurl 的 Life Calendar 上, 提供了一個介於統計式每日每週文章照片數量, 到 Blog 式落落長文章串之間, 折衷的摘要總覽介面. 輔以 Calendar 的 Metaphor, 我們會很自然地把相近日期的事件連結起來, 於是過去一天, 一週, 一月, 一年, 很快地就可以在你的腦海中流逝而過. 在每天每天每週每週 Blog 文章跟照片, 多媒體資料之間, 其實我們都遺漏 / 篩選掉了很多細節, 心情的轉換...... 這些東西我們沒辦法, 也不可能一一記錄下來, 但是透過 Life Calendar, 就像整理舊相簿一樣, 時間可以在手上流過, 本來一點一點的文章照片, 就可以銜接變成一整串記憶之流.
我想 Swurl, 以及他的相似 / 後繼者,會逐漸揭露一個方向 : 把Lifestream 的焦點從紀錄, 開始轉移到操作上. 就像編輯家庭錄影帶, 透過不同的操作, 我們可以再次提供不同的觀點, 不同的交集, 不同的思考, 以及不同的懷念 -- 為什麼我又會想到羅賓威廉斯的迴光報告 ( The Final Cut, 2004 ) 呢 ?
btw, My Swurl : http://selain.swurl.com/
FireFox 3 Download Day Certificate
六月中的時候跑去 FireFox 3 Download Day 湊了一下熱鬧, 今天收到來自 FireFox 的通知信, 除了說明登上金氏世界紀錄之外, 還有提供個人 Certificate, 紀念一下摟 :p
話說不知道是不是我看錯, 我記得在 Download Day 之前台灣的 Promise 人數好像遠低於後來的 Download 人數 ? 另外最令我驚訝的是德國, 不管是當時的 Promise 人數跟後來的 Download 人數都高的嚇人 ( 當然是比不過美國啦... ).
StarCraft II 如果 Open for Download, 應該可以打破這個紀錄吧 XD
When to Reject the Customers/Users from Participating Your SDP ?
在 Software Development Project ( SDP ) 中, 理論上在哪個時間點之後, 絕對不能再有 Users ( Customers ) 的參與 ? 這是約莫一年半以前, 我的 Advisor 問所有 Lab. 同仁的問題, 但是直到現在, 我也依舊沒有肯定的答案 ^^b
先來看看手邊幾本的說法. 當然, 這是依我的解讀做的時間點判斷及說明, 同時內容以及最後我自己的想法都侷限在 Conventional Object-Orientation Paradigm. 同時只考量 General Customer, General Software ( to-be-built ), 以及 No Changing Requirements ( during development process ).
[1] Dean Leffingwell and Don Widrig, Managing Software Requirements: A Use Case Approach, second edition, Addison Wesley, 2003
我的理解 :
- 書中分為六個階段的 Team Skill, 我認為在 Team Skill 2 結束時也同時代表 customer 的參與告一段落.
- 在 software GUI 部份, 書中傾向於使用 Use Case 以及 Storyboarding 解決. 鑒於內容是以 Storyboarding 方式, graphically 呈現 Use Case, 因此我還是認定為 Storyboarding 的應用, 屬於 Team Skill 2 的範圍內.
- After Requirement Elicitation, Feature Listing, Interviewing, Brainstorming, and Storyboarding
- Before Use Case Diagram
我的理解 :
- 書中於 Requirement Phase 到 Object-Oriented Analysis Phase 之間, 特別分出了一個 Specification Phase. 在 Specification Phase 中提到 :
...this document must be clear and intelligible to the client, who probably is not a computer specialist. After all, the client is paying for the product, and unless the client believes that he or she really understands what the new product will be like...
- 因此我認為以書中的觀點, customer 至少會參與到 specification 的制定.
- 書中所指的 Specification Phase 事實上等同於一般說的 Analysis Phase[2], 而 Object-Oriented Analysis Phase 是作為 counterpart 存在.
- 同時書中也提到, 在 specification 訂立之後才能進行較準確的 project time and cost estimation, 而 customer 會根據評估結果決定是否繼續委託開發. 從 project 角度來說, customer 在此時仍影響 project 的進行, 但是從 software development 的角度來說, 並未影響 software development 的各種 decisions.
- End of Specification Phase
- Right after Project Time and Cost Estimation and Evaluation
我的理解 :
- 書中把 Requirement 分為 C-Requirement ( Customer Requirement ), 以及 D-Requirement ( Detailed Requirement ) 兩部份. 其中 C-Requirement 包含了 Use Case 的建立與撰寫, 以及 Draft User Interface Design. 此階段仍有 customer 參與.
- D-Requirement 的撰寫雖然主要是提供 software developers 一個之後進行 design 以及 implementation 的共同基礎,但是書中也提到 D-Requirement 需要 customer 參與 validation 的工作. 但是由於書中對於 D-Requirement 的內容敘述, 甚至包含了 Classes / Objects 的辨認, 因此 customer 協助確認的應該不是全部的 D-Requirement 內容.
- Right after D-Requirement ( Detailed Requirement ) is released
- Very close to the end of Object-Oriented Analysis Phase
我的理解 :
- 書中提到 :
A review of the Software Requirement Specification ( and / or prototype ) is conducted by both the software developer and customer.
- 而依據書中所述, Software Requirement Specification 是 Requirement Analysis 的產物, 因此在此 customer 的參與應該是到 Requirement Analysis 結束之後, 或是 Software Requirement Specification 的 review
- End of Requirement Analysis
- Review of Software Requirement Specification
[5] 我的想法
由於我對於 OO Paradigm 底下的 Software Development, 主要的認識來自於 [1][2][3] , 因此以這些書中所提的觀點以及方法 ( Techniques ) 來回答此時間點。
我所 prefer 的時間點為, Use Case Diagram 的建立。
但此時間點僅包含 Use Case Diagram 的建立, 不包含 Use Case 的 Pre-Condition, Post-Condition, 以及中間的 Event Flow, Alternative Flow 的撰寫。
我所持的理由為, Use Cases 能夠將 Scenarios 化為數個合理大小的 User Action Sets。 雖然 Use Cases 本身仍然用 nature language 描述居多, 但是比起一般的 Scenarios 描述, Use Cases 提供一個更適切的 granularity, 讓 customer 認識自己與 software 之間的互動。 而適切的 granularity 也是此時間點僅止於 Use Case Diagram 的理由。 我認為 Use Case 的內容又過於仔細, 對於一般的 Customer 來說反而可能造成困擾, 如果要求 Customer 參與 Use Case 內容的撰寫, 對 Developer 來說也會是一種困擾。
但是在 Customer 參與 Use Case Diagram 的制定時, 所提出的一些意外的要求或是 Concerns, 有可能會影響到 Developer 對於 Use Cases 內容的撰寫。
另外我認為要特別考量的一個問題是 Software GUI。 鑒於我所知道的, 在 OO Software Development, 並沒有公認的時間點來決定 customer 所 prefer 的 GUI 樣式, 但是 software GUI 又是影響 software usability 甚鉅的部份, 因此大部份情況下, 與 customer 針對 GUI 作溝通是免不了的。 因此在 software 有 GUI 的設計考量下, customer 能參與的 software development 的時間點我認為就會受到 software GUI 要在何時與 customer 取得共識的影響。 不過此時間點僅與 GUI 設計有關, 與其他部份無關。
Zero-Day Copy ?
剛剛又看到一個複製網站 說你這行 (ShowUrJob) , 很顯然想法是來自於 Glassdoor.com . 透過 Community Member 的群體力量, 讓許多公司的薪資跟待遇透明化.
在 Software Security 領域有 Zero-Day Attack, 在 Internet Venue 領域也要有 Zero-Day Copy 了嗎 :p
不過我並不是想嘲笑 Zero-Day Copy 的行為, 相反地, 這類網站能獲得成功也相當不錯, 沒有人會嫌可以用的服務太少, 不是嗎 ?
Zero-Day Copy 的可行性我認為與 Localization 關係極大, Glassdoor.com 對於非英語系的國家還沒有那麼大的 Community, 而缺乏 Community 就缺乏資訊. 如果有相似的網站可以快速複製實現類似的功能以及制度, 藉著語言以及文化優勢搶在開拓者 ( 如 Glassdoor.com ) 之前嘗試建立夠大的 Community, 成功的可能性並不低.
在 Zero-Day Copy 中, 最難得到的 Idea 來自於別人, 要搶佔的 Resource 本來就在 Community 中, 而中間快速複製才會是重點. 因此在 Zero-Day Copy Company 中, 最重要的角色可能會是兩種人 : Reverse Engineer 以及 Project Manager. ( 為什麼我會想到 Pay Check 這部電影 :p )
這裡的 Reverse Engineer 包含不只軟體技術上的 Reverse Engineer, 還包含可以從 Social 角度進行 Reverse Engineering, 分析開拓者成功因素跟行為模式的 Reverse Engineer. 換句話說, 需要的是一個 Socio-Technical System Reverse Engineering Team.
Project Manager 就不用說了, 能夠在合理的時間跟成本下領報開發團隊完成 Software Development 的 Manager 是每家軟體公司都想要的人.
也許將來 ( 或是現在就有 ? ) 會出現專門支持 Zero-Day Copy 的創投公司也說不定. 平常就養一堆技術高超的資訊人食客, 在 DEMO 展之類看到有價值的外國網站就馬上進行 Zero-Day Copy 工程, 反正現在軟體服務專利幾乎是沒有辦法申請的狀態. 有這種公司也是蠻有趣的, 跟我有點合得來 :p
Functionality versus Capability ? A Case in Java OpenCV
這兩天跟學妹一起在對 Java OpenCV Match Template (以下簡稱 Java OpenCV ) 這個 Tool 作一點修改.
Java OpenCV 其實是一個 Adapter, 把 OpenCV ( 著名的 Computer Vision Library ) 內的 cvMatchTemplate Function ( 用 C++ 寫的 ) 包上 Java 的外衣. 而 cvMatchTemplate 的主要能力就是比對基底影像 ( Source Image ) 與模板影像 ( Template Image ), 找出在基底影像中哪些地方存在著與模板影像相似的影像, 以及該處的位置 ( 在圖片或影像截圖上的 ).
為簡化敘述, 先不論 Java OpenCV 其實是 Adapter 而已, 假設把 Java OpenCV 跟 cvMatchTemplate 包在一起看成一個單一的 Component, 而這個 Component 提供一個 Interface 可以輸入基底影像以及模板影像, 而會回傳一個最佳的比對結果影像物件 ( Java Image Object ), 以及位置. 由於這是此 Component 唯一能夠提供的 Service, 因此就說這是 Java OpenCV 的 Functionality.
但是我們需要的是能夠提供多個比對結果的 Functionality. 例如下面的 Java OpenCV 測試圖, 在四個角落都有幾乎同樣的圓點, 但是 Java OpenCV 只會傳回最相似的一個結果而已. 而我們希望四個結果都可以傳回給我們作選擇.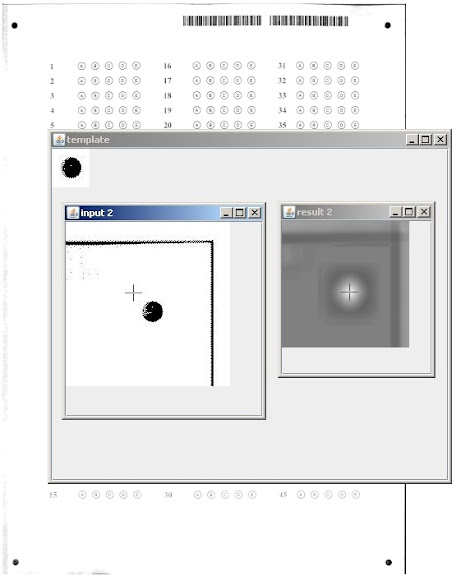
由於短時間內沒有找到其他的 Tool 如此符合我們的需求, 加上 Java OpenCV 的程式碼其實不長, 因此我們去查看了一下原始碼. 在 Java OpenCV 與 cvMatchTemplate之間是使用 JNI 作連結, 而主要的 Image Matching 都是 cvMatchTemplate 進行的沒錯. cvMatchTemplate 是以逐一影像區塊進行比對的方式, 比完整張圖, 因此用了一個很大的 array 來存所有的比對結果.
而 cvMatchTemplate 回傳給 Java OpenCV 的內容其實包含了所有的比對結果, 而不是只有最佳的比對結果. 換句話說, 是在 Java OpenCV 內被做了過濾. 更嚴格來說是在 matchTemplate method 回傳之前, 在 findMaxPoint 裡面被過濾掉了, 只留下最佳的比對結果位置.
這樣一來事情就很簡單了, 我們另外加上了一個 matchTemplateMultiple method, 使用動態決定 Threshold 的方式來過濾出最好的幾個比對結果, 因此可以獲得多個比對結果.
但我覺得有趣的是, 很顯然地 Java OpenCV Component 本身就具有偵測到所有可能比對結果的 Capability, 只是由於他只提供了 matchTemplate 的 Interface, 因此形成了 Functionality 與 Capability 不相稱的情況. 基於 Encapsulation 的原則, 我們不可能從 Interface 就得知 Java OpenCV Component 的真實 Capability, 但是透過知道 Java OpenCV 原本的 Capability, 卻使得我可以評估花較少的 Effort 去增加 Java OpenCV 的 Functionality, 變相地增加了 Java OpenCV 的 Re-usability.
之前會說希望把 Java OpenCV 看成單一 Component 而不要管 Adapter 身份是因為此 Case 有點特殊, Adapter 本身本來就可能對於原本的 Component Functionality 有遮蔽的作用. 但我認為對於一般 Component 來說也可能會有此現象發生, 如果可以有辦法偵測或是表達 Component 本身的 Capability 與 Functionality 之間的差異, 或許會是一件很有用的資訊.