
Know both Design Abstraction and Implementation Detail ever Resourceful
為了取這個標題, 還特地去查某句成語的英文一般都怎麼說 XD
昨天在處理實驗室 MoinMoin Wiki 出現的一個奇怪的問題. 某個特定頁面只要進行瀏覽, 就會導致 MoinMoin 整個 Crash, 一點 Process 也不留. 自然, 直覺就是該頁面內容有什麼奇怪的東西, 或是內容在磁碟上有毀損, 導致 MoinMoin 讀到該頁面內容就會出現 Exception 而掛掉.
但是在想要近一步去檢視該頁內容是, 猛然發現, 其實我不知道 MoinMoin 是怎樣處理 Page Data 的. 我既不知道 Page Data I/O 的部份在哪, 也不知道 Page Data 平常是保存在哪.
本來, 閉著眼睛也可以大概畫出一般 Wiki System 的 Architectural Design Abstraction, 主要的 Components 有哪些, 各自的責任也清楚. 但是單知道這些對我現在要解決問題幫助卻不是很大.
作為一個在唸 Ph.D. Program 的 Programmer, 這樣的事情真的是很不應該的, 但是還是發生了, 因此特別寫下這個標題--雖然別人看來可以摸不著頭緒--來警惕一下自己.
幸好簡單查一下 MoinMoin 的資料, 馬上就看到 MoinMoin 在 Data 的保存上十分簡單, 直接利用現成的 File System 作儲存而已. 這樣一來馬上補足了在 Data Repository 部份的一些細節, 也就一下子找到 Page Data.
MoinMoin 的 Page Data 存放在 /data/pages/ 中 ( 實驗室的資料比較敏感, 以下用電機系網路服務使用手冊 Wiki 作例子 ),
每個頁面直接用 Relative Page Path 作為 Directory Name, 其中 "/" 以及 "-" 之類的就用特殊符號取代, 像是 (2f) 跟 (2d).
在每個頁面的 Directory 之下, 有幾個主要的檔案跟資料夾, 名稱一看就很清楚, 不一一加註, 只舉頁面內容來說, current 檔案紀錄目前的版本, 而 revisions 資料夾裡面存有所有的歷史頁面資料. 因此實際的頁面資料是存在 revisions 資料夾裡的, 把每個頁面 cat 出來就很清楚了.
從這點也可以看出來, 其實大量頻繁的網頁修改, 在 MoinMoin 系統中是很吃硬碟資源的.
知道 MoinMoin 資料存放的細節後就更有趣了.
目前手上有些給實驗室用的小東西, 過去不是很清楚要怎樣把其輸出直接送到實驗室的 MoinMoin Wiki, 這樣一來其實可以直接在 File System Level 作手腳. 繞過 MoinMoin 本身, 直接輸出到 Data Repository 中, 只要內容格式符合 MoinMoin 語法, 跟 Revision History 等 Meta-data 有正確的填寫, 就能夠被 MoinMoin 讀取, 出現在 Wiki 頁面系統上了.
Know both Design Abstraction and Implementation Detail ever Resourceful.
我要把這句印出來貼在座位旁 :p
Play Sound using Virtual MIDI Piano Keyboard
其實主要步驟只要照著 Compdigitec Labs 的這篇 Virtual MIDI Keyboard In Ubuntu 作即可.
不過實際上在我的系統上有些微的不同. 因為對整個 Sound System 不熟悉, 沒有辦法理解是怎麼回事, 姑且記下來當作 "這樣設定也可以" 看吧.
先記一下安裝的部份, 共需要 ( Package Name 以 Mandriva 2010.1 上的為準 ) :
1. qjackctl ( JACK Audio Connection Kit )
2. zynaddsubfx ( ZynAddSubFx )
3. vmpk ( Virtual MIDI Piano Keyboard )
其中 vmpk 是要作為虛擬 MIDI 鍵盤的主介面. 雖然後來發現 ZynAddSubFx 也有虛擬鍵盤介面, 但是變更 Keyboard Map 設定跟其他各種設定上, 感覺 vmpk 比 ZynAddSubFx 來的方便.
而 qjackctl 是 Connection 控制器, 負責把 vmpk 作為前端介面, 輸出的 MIDI 資料導引到 ZynAddSubFx, 再到實體的音效硬體/音效卡作播出. 因為 vmpk 本身其實就是單純的虛擬鍵盤子系統, 因此到實際播出前需要 Synthesizer 幫忙處理合成. ZynAddSubFx 在這裡就當作 Synthesizer 使用.
接著作 limits.conf 設定,
sudo su -c 'echo @audio - rtprio 99 >> /etc/security/limits.conf'
sudo su -c 'echo @audio - memlock 250000 >> /etc/security/limits.conf'
sudo su -c 'echo @audio - nice -10 >> /etc/security/limits.conf'
把系統 reboot 後重新開啟 qjackctl, 並利用 "Start" 按鈕開啟 JACK server ( jackd ). 這時候如果遇到開啟失敗的訊息, 請利用 Messages 按鈕看錯誤訊息. 如果是 server 啟動失敗, 請把 ALSA 重新啟動試試看. ( alsa command 的位置可能根據系統有所不同 )
sudo su -c '/etc/init.d/alsa force-reload'
啟動沒問題的話, 開啟 ZynaddSubFx 以及 vmpk, 然後利用 Connect 按鈕設定上面說的, 從 vmpk 到 ZynaddSubFx 再到音效裝置的 Connections.
照 Compdigitec Labs 的文章中之示範, 音效卡代號應該會出現在 ALSA 分頁中, 但是我的沒有 ^^b, 所以先只有把 vmpk 的 Output 接到 ZynaddSubFx. 接上的方法很簡單, 用滑鼠把 vmpk Output 拉到 ZynaddSubFx 上放開即可.
而 ZynaddSubFx 到音效裝置間的連結, 則是改在 Audio 頁面中搞定. 其中 playback 1 是左聲道, playback2 是右聲道, 其他的在我系統中無作用.
這樣設定完就 OK 了~, 把視窗 Focus 移到 vmpk 上面, 對應的鍵盤按下去就可以看到琴鍵變化, 以及發出 MIDI 音效. 在 ZynaddSubFx 視窗中也會有對應的變化.
其實當焦點移到 ZynaddSubFx 上也是可以有同樣的反應. 不過如上所述 vmpk 較占優勢的理由, 本篇還是以 vmpk 作為 Front-End 為主.
OpenFoundry Attack (三) Downloads versus Lifespan
延續 OpenFoundry Attack (二) , 把 Project Downloads 與 Project Lifespan 來比對看看.
Project Lifespan 指的是一個 Project 自創造出來到目前為止 ( 2010-04-20 ) 的時間, 在此以天數 (Days) 作為計量單位.
由於在 OpenFoundry 中, Downloads 數量有顯著量級差距, 因此全部一起看反而看不出甚麼. 以下分為幾個不同的 Scales 來看.
首先是 Downloads 在 0 ~ 100 之間的 Projects. 在此不包含 Downloads 為 0 的 Projects, 在圖上會佔據 Y = 0 的軸線, 意義不大.
較明顯的是 Lifespan 在一年半到兩年之間的 Projects 比較集中一點, 這跟 OpenFoundry Attack (一) 中提到 2008 年 10 月前後的大量註冊 Projects 自然有相關. 但是從 Downloads 的角度來看, 其實並沒有特別的傾向, 算是還蠻平均的. 而從其他 Lifespan 的角度來看, 其實在 Downloads 的表現上也是很平均, 並沒有說 Lifespan 長的 Projects ( 也就是比較老的 Projects ) 就比較容易有高的 Downloads 數量.
事實上同樣的情況放到其他 Scales 也是類似.
底下是 Downloads 在 0 ~ 500 之間的 Projects 分佈. 請忽略左下角那團, 那在上圖中已經說明過了. 其他部份也是均勻分佈.
Downloads 在 0 ~ 1000 之間的 Projects 分佈.
Downloads 在 0 ~ 5000 之間的 Projects 分佈.
Downloads 在 0 ~ 10000 之間的 Projects 分佈.
Downloads 在 10000 以上的 Projects 數量相對少很多, 代表性低就不看了. 基本上結論是, 在 OpenFoundry 上, 目前看來 Lifespan 跟 Downloads 的關聯性並不高.
OpenFoundry Attack (二) Project Downloads
接續前篇 OpenFoundry Attack (一) 的 Data Crawlng 設定, 對於 Project 績效最容易理解的指標 : Downloads 數量作統計, 數據如下表.
其中 Intervals 為下載數量間隔, 第一個 0 為特殊的間隔, 代表下載數量為 0 的計畫數量, 而 的間隔為下載數量大於等於 1 次, 小於 50 次的意思, 其餘的間隔依此類推. 最後一個 50,000,000 ~ 的間隔代表下載數量在五千萬次以上的計畫數量.
| Intervals | Downloads |
| 0 | 695 |
| 1~ 50 | 133 |
| 50 ~ 100 | 60 |
| 100 ~ 500 | 132 |
| 500 ~ 1000 | 48 |
| 1000 ~ 5000 | 69 |
| 5000 ~ 10,000 | 18 |
| 10,000 ~ 50,000 | 23 |
| 50,000 ~ 100,000 | 6 |
| 100,000 ~ 500,000 | 12 |
| 500,000 ~ 1,000,000 | 2 |
| 1,000,000 ~ 5,000,000 | 1 |
| 5,000,000 ~ 10,000,000 | 1 |
| 10,000,000 ~ 50,000,000 | 0 |
| 50,000,000 ~ | 1 |
其中下載次數為 0 的計畫共有 695 個, 佔所有此調查中所查看計畫總數的 57.87 % , 而除此之外, 算是很正常地在 1 ~ 5000 次下載的計畫佔餘下的大多數.
換成長條圖可以比較容易看出比例差距. ( 圖中的 maximum 就是下載數量大於五千萬次 )
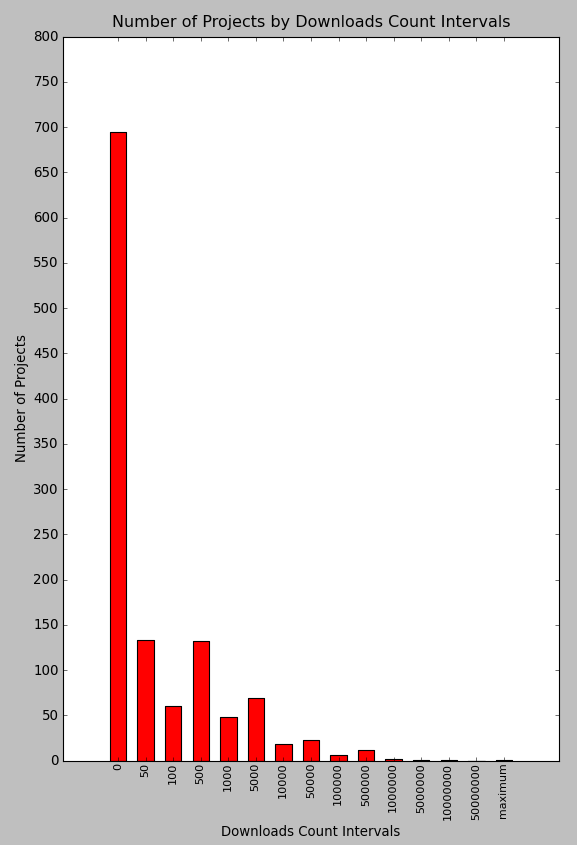
當然對於下此數量在五十萬次以上的少數 Projects 難免讓人好奇, 這些 Projects 分別是 可攜應用程式套件中文化 ( 508,946 次 ), Wow! USB VirusKiller 可攜式儲存設備防毒軟體 ( 734,802 次 ), 新同文堂 ( 1,149,864 次 ), Wow! USB Protector 可攜式儲存設備防毒偵測 ( 8,389,615 次 ), 以及 PCMan 驚人的 104,258,467 次, 這數字即便在 Sourceforge.net 都很驚人. 另外兩個名列前茅的 USB 防毒相關計畫都是中研院同一個研發小組的成果, 所以計畫名稱基本上很類似.
另外隨手附上 Sourceforge.net 在 2006 年左右的圖表, 詳細蒐集日期不太確定, 應該是 9 or 10 月左右. 當時共觀察 58794 個 Projects, 其中下載數量為 0 的有 20751 個 Projects, 約佔 35.29 %

這兩個圖表中, 感覺 Downloads 在 500, 5000, 以及 50000 次似乎有形成三個門檻的趨勢. 不過還需要再觀察, 以及設法跟 Project Lifetime 作交叉比對就是.
OpenFoundry Attack (一) : Project Creation Statistics
因為現在好像沒用 OpenFoundry 的話國科會計畫會比較難過了的樣子, 既然這樣就來研究一下.
不知道系列會寫多長, 也許到終於被禁止 crawling data 為止 ? 系列命名採自 Korea MBC Battle.net Attack -- 其實沒什麼意義, 純粹好玩又想不到要取甚麼.
資料蒐集日 : 2010-04-20
至資料蒐集日為止, OpenFoundry 上共有 1219 個專案, 但是專案編號事實上是從 1 ~ 1470, 換句話說其中有些專案已經因為某些原因被移除了 ( Deactivated ), 被移除的專案共有 241 個左右, 例如編號 14 的專案.
自然資料蒐集就只有針對活動中的 1219 個專案. 而同時由於未知的原因, 我的 Crawling Tool 只能抓下其中 1201 個專案的資料, 不過數量已經相當接近了, 因此餘下的 18 個就當作沒看到 ( 其實是懶得一個一個去找 XD )
把這 1201 個專案依照其 Creation Date ( 以 Month 為單位作收納 ) 來整理, 可以得到下面的分佈長條圖.
很自然地會注意到幾個特別的分佈. 由於 Blogger 的顯示限制, 點選上圖可以看到比較清楚的 X 軸年月份標籤.
其中在 2004 ~ 2006, 以 4 ~ 6 月為中心的 Project Creation 數目明顯比周圍的月份來的高, 2007 年整年相對普通, 而 2008 及 2009 年則是變成 9 ~ 10 月份有相對高檔, 特別是 2008 年 10 月份一舉超過單月 70 個新開設計畫.
基本上一年之中 1 ~ 3 月新計畫的開設量少是可以理解的, 因為剛過完新年, 接近農曆年, 然後馬上又是四月初的春假, 這三個月正好是減溫到加溫中. 不過其他月份在 2008 以及 2009 年的反差實在有點大就是了. 話說這兩年的 10 月究竟有甚麼特別的呢 ?
本來還想做一張 Creation Date 對上 Last File Update 的時間關係, 不過做到一半驚覺 OpenFoundry 有未來檔案的問題. 例如 Simple PHP Blog 正體中文與補強計畫 的最新檔案日期是 2019-11-17, 另外也有 2030 年的, 這樣讓時間可靠性產生很大的問題, 所以還是摸摸鼻子算了.
How Matplotlib and NetworkX Work Together : A Case Study on Figure Instances
最初是因為以下的 Code 讓我對這個問題有興趣. 這段簡單的程式碼 Matplotlib 以及 NetworkX 來合作畫圖. 其中 NetworkX 負責 Graph Model 的建立, 而 Matplotlib 則負責 Figure 繪圖的部份.
最後繪出的圖, 如同程式碼所指定的位置, 畫出三個圓點.
而我覺得程式碼有趣的地方在於, 細看程式碼, matplotlib.pyplot 只有在 line 6, 以及 line 20 被使用, 期間 line 9 到 line 18 都是 networkx 的運作.
而, 在此 Script 中, networkx 跟 matplotlib.pyplot 表面上是沒有任何互動的, 沒有任何 Message Passing 或是 Object Communication 出現. 如果單單依照此 Script 中的 Program Logic 作 Program Slicing, 或許就會被乾脆地切成兩個 Program Slices 了.
不過想當然爾, 既然最後可以順利地畫出圖來, 這兩部份的程式碼肯定在背後有進行某種 Communication, 否則不可能在 networkx 中建好 Graph Model, 在 matplotlib.pyplot 中就知道要畫出甚麼樣的 Figure.
經過漫長的 Code Tracing, 大致上可以把 Dependency Graph 整理如下圖 :
其中比較關鍵的是 Matplotlib 在 Figure Management 上, 允許同時間有數個 Figure Instances 存在, 而目前要畫在哪個 Figure Instance 上, 則視乎目前哪個 Figure 被設定為 Activated.
在 plt.figure() 中 ( 事實上為 matplotlib.pyplot.figure() ), 可以透過參數 num ( 可參考 Online Document, 即 Figure Instance Identity ) 指定要 activate 那一個 Figure Instance, 如果 Instance 不存在, 則會產生一個新的 Instance.
而在綠色的流程中 ( 即程式碼 line 9 到 line 18 ), networkx 在 nx.draw_networkx_nodes 進行中會透過 matplotlib.pylab.gca 取得目前為 Activated 的 Figure Instance 其 ax object ( 座標軸物件 ), 之後透過 ax 把要畫出來的 nodes 加進去.
最後 plt.show() 透過 matplotlib.backend_gtk 把圖畫出來.
這 Matplotlib 中的 Figure Instance 取用機制大體上是為什麼原本的 Code Script 中, 在乍看之下 networkx 跟 matplotlib.pyplot 沒有 Communication, 但是還是可以把圖畫出來的主要原因.
CCE Posters
大約兩個禮拜前我幫成大電通所做的兩張海報終於印好公開展示了 :)
這海報是要把成果展示給高中生看的 ( 話說為什麼要作這種事阿 = = ) 當初我申請入學的時候怎就沒有這等待遇... 現在既有交通車, 還有午餐點心, 還有教授解說...
Here's the original design of the two posters : 左邊黑色那張是用 SE4PP/SIMPLE 為主設計的 ( Head-First 風格 XD ), 右邊那張是林輝堂老師 NSDA 實驗室的天使之眼, 加上詹寶珠老師 SMILE 實驗室提供的部份計畫材料完成的. 其他 Lab. 沒提供材料就沒辦法摟~
左邊黑色那張是用 SE4PP/SIMPLE 為主設計的 ( Head-First 風格 XD ), 右邊那張是林輝堂老師 NSDA 實驗室的天使之眼, 加上詹寶珠老師 SMILE 實驗室提供的部份計畫材料完成的. 其他 Lab. 沒提供材料就沒辦法摟~
本來覺得藍黃底色配色很普通有點擔心, 但是其實出來的效果還不錯. 左邊那張被實驗室的 DC 照醜了, 其實做出來的質感搭配木框很不錯, 右邊的漸層效果也很不錯, 唯一的缺點是 NSDA 的 Logo 可能因為輸出軟體跟 Inkscape 在解讀透明圖層上有點差異, 結果變成了色塊了, 不然那邊應該也是漸層的.
左邊那張被實驗室的 DC 照醜了, 其實做出來的質感搭配木框很不錯, 右邊的漸層效果也很不錯, 唯一的缺點是 NSDA 的 Logo 可能因為輸出軟體跟 Inkscape 在解讀透明圖層上有點差異, 結果變成了色塊了, 不然那邊應該也是漸層的.
兩張一起照, 這張看起來好點 : 稍微看了一下其他組的, 覺得還是自己做的這兩張好, 其他很都多都只是貼圖跟文字資料, 還有只有精神標語的, 以及錯別字錯很大的 XD
稍微看了一下其他組的, 覺得還是自己做的這兩張好, 其他很都多都只是貼圖跟文字資料, 還有只有精神標語的, 以及錯別字錯很大的 XD
海報製作除了 DBSE 實驗室自家材料以及兩個實驗室支援的材料, 純粹使用 Inkscape, GIMP, cwTeX 字體, OpenClipArt 素材加以修改, 十分感謝 :)
恐怖的 Adeona
過去兩三個禮拜 Adeona 忽然變成了一個熱門關鍵字 :p
原因是 Adeona 這個 Open Source Project, 號稱是第一個可以對於你的 Laptop Notebook 進行 Tracking 的 Open Source Software, 對於追回失竊的 Notebook 來說特別有用.
其基本的概念是在 Notebook 上安裝一個 Client Software, 每當 Notebook 連接上網路時, 會自動將該 Notebook 的位置 ( IP 以及相對存取周遭網路設備的位置 ) 進行 AES 加密後, 利用 OpenDHT 技術存到特定的 Server 上, 該加密過後的位置資料只有原始擁有者可以開啟, 如此一來 Notebook 的擁有者就可以對於 Notebook 的位置進行追蹤, 並確保自己的隱私.
關於 Privacy 部份, 事實上 Adeona 作的考量更多, 包含無法簡單透過 Location Update 去鎖定特定的 Device 等等, 務求達成 Anonymous, Unlinkable Updates, 詳細內容請見 Adeona 的發表 Paper , 在講述 System Goal 的部份有列舉說明.
我之所以覺得 Adeona 很恐怖是因為, 同樣的概念幾乎可以用在任何可以運作 Software 的地方(或東西). 甚至我可以說, 一般 Notebook 並非 Adeona 最好的利用環境. 理由是一般 Notebook 或是 Laptop 的系統都很容易被重新安裝或是修改. 重新安裝會使得 Adeona 失去作用, 而修改則可能使得竊賊進一步利用 Adeona 對於追蹤進行欺騙.
反倒是其他的高價物品, 利用 Adeona 的可能性以及有效性極高. 例如在無線環境下的汽機車, 高單價的 Mobile Device, 重要的文件盒保險箱等等 ( 不用再害怕忘在公車或是計程車上摟 ). 可以簡單把 Adeona 作成一個具無線網路功能的訊息送出嵌入式設備, 讓使用者自行安裝在要追蹤的物品上. 這種嵌入式系統就可以避免掉上述的問題, 只要不被從保護物品上拆除就好. ( 使用者可以裝在很隱密, 或是無法拆除的地方 ). 從這個角度來看, 其實跟 RFID 又有點像, 但是安全性以及範圍又比 RFID 大很多.
而除了這些可能之外, 最恐怖的是, Adeona 也可能被裝在 Software 或是 Data 身上, 讓我們可以對於 Software 或是 Data 的 Distribution 作追蹤, 例如公司內重要的電子文件管理, 怎樣確保每一份被複製的重要文件, 沒有在允許以外的地方被開啟.
這樣一想, Adeona 的概念幾乎可以用在任何地方, 這能不恐怖嗎, 光用想的我雞皮疙瘩就起來了 = =
Keep Watching : Software Quality Observatory for Open Source Software (SQO-OSS)
記得大約是兩年前作 OSS Quality Measurement Project 時看到 SQO-OSS 這個計畫網站的, 當時裡面還甚麼都沒有, 但是畫了很多 Vision 的大餅. 同時間注意到的還有 Ohloh.net ( 之前文章 Assessing Open Source : Ohloh.net ). 後來 Ohloh.net 陸續公佈了許多新的功能以及介面調整, 而 SQO-OSS 不愧是學術計畫, 一直停留在只聞樓梯響的階段.
而現在, Finally, SQO-OSS 也進入 alpha-testing 的階段了, 公佈了一個 Quality Checking Tool, 名為 Alitheis Core. 不過 Demo 網站好像掛點了, 真是不太捧場阿 :p
雖然 Demo 掛點, 不過需要的話可以下載 0.8 或是 0.8.1 的版本, 在這裡可以找到. ( 主要開發語言是 Java, 大心 ^_^ )
Alitheia Core 的 Architectural Overview 可見下圖 (引用自 SQO-OSS 網站 ). 其實並沒有甚麼特別的地方. 值得注意的是此頁的 Title 是寫 Alitheia Core and Metrics, 但是圖中沒有出現 Metrics, 因此也不確定是用在 Information Extraction 或是 Data Mining 的部份. 不管怎樣, 整個系統的運作其實不難理解.
在 Source 裡面的 Metrics Package 含有很多 Sub Packages, 甚至包含 Productivity Metrics. 不過細看很多內容都是空的 ( 這是怎樣 = = ), 也許正在實做中吧.
既然玩不到 Demo, 改來看看公開的 ScreenShots ( Alitheia Core 0.8.x ) 也好. 但其實從 ScreenShot 看來也蠻讓人失望的.
是的, 看起來有很多 Metrics 可以安裝來用, 但是從 Source Code 以外的 Project Artifacts 進行分析的部份看起來還是缺乏. 而即便是已經有的 Metrics, 在能夠連結到更 High Level 的意義之前, 我想對於 OSS Community 的吸引力也不是很大.
不過不管怎麼說, 人家也是有 Product 了, 我們實驗室的還在難產中. 加油吧~~
FireFox 3 Download Day Certificate
六月中的時候跑去 FireFox 3 Download Day 湊了一下熱鬧, 今天收到來自 FireFox 的通知信, 除了說明登上金氏世界紀錄之外, 還有提供個人 Certificate, 紀念一下摟 :p
話說不知道是不是我看錯, 我記得在 Download Day 之前台灣的 Promise 人數好像遠低於後來的 Download 人數 ? 另外最令我驚訝的是德國, 不管是當時的 Promise 人數跟後來的 Download 人數都高的嚇人 ( 當然是比不過美國啦... ).
StarCraft II 如果 Open for Download, 應該可以打破這個紀錄吧 XD
Functionality versus Capability ? A Case in Java OpenCV
這兩天跟學妹一起在對 Java OpenCV Match Template (以下簡稱 Java OpenCV ) 這個 Tool 作一點修改.
Java OpenCV 其實是一個 Adapter, 把 OpenCV ( 著名的 Computer Vision Library ) 內的 cvMatchTemplate Function ( 用 C++ 寫的 ) 包上 Java 的外衣. 而 cvMatchTemplate 的主要能力就是比對基底影像 ( Source Image ) 與模板影像 ( Template Image ), 找出在基底影像中哪些地方存在著與模板影像相似的影像, 以及該處的位置 ( 在圖片或影像截圖上的 ).
為簡化敘述, 先不論 Java OpenCV 其實是 Adapter 而已, 假設把 Java OpenCV 跟 cvMatchTemplate 包在一起看成一個單一的 Component, 而這個 Component 提供一個 Interface 可以輸入基底影像以及模板影像, 而會回傳一個最佳的比對結果影像物件 ( Java Image Object ), 以及位置. 由於這是此 Component 唯一能夠提供的 Service, 因此就說這是 Java OpenCV 的 Functionality.
但是我們需要的是能夠提供多個比對結果的 Functionality. 例如下面的 Java OpenCV 測試圖, 在四個角落都有幾乎同樣的圓點, 但是 Java OpenCV 只會傳回最相似的一個結果而已. 而我們希望四個結果都可以傳回給我們作選擇.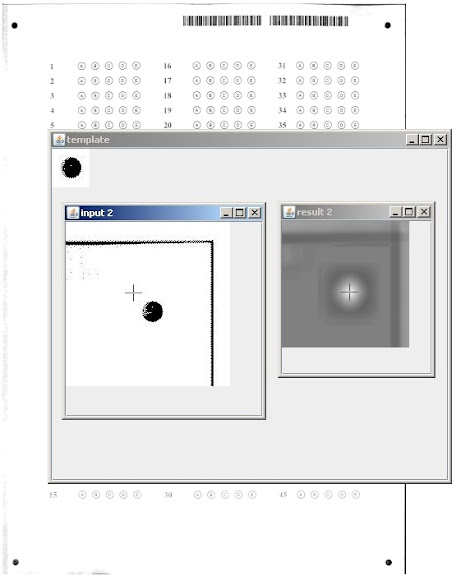
由於短時間內沒有找到其他的 Tool 如此符合我們的需求, 加上 Java OpenCV 的程式碼其實不長, 因此我們去查看了一下原始碼. 在 Java OpenCV 與 cvMatchTemplate之間是使用 JNI 作連結, 而主要的 Image Matching 都是 cvMatchTemplate 進行的沒錯. cvMatchTemplate 是以逐一影像區塊進行比對的方式, 比完整張圖, 因此用了一個很大的 array 來存所有的比對結果.
而 cvMatchTemplate 回傳給 Java OpenCV 的內容其實包含了所有的比對結果, 而不是只有最佳的比對結果. 換句話說, 是在 Java OpenCV 內被做了過濾. 更嚴格來說是在 matchTemplate method 回傳之前, 在 findMaxPoint 裡面被過濾掉了, 只留下最佳的比對結果位置.
這樣一來事情就很簡單了, 我們另外加上了一個 matchTemplateMultiple method, 使用動態決定 Threshold 的方式來過濾出最好的幾個比對結果, 因此可以獲得多個比對結果.
但我覺得有趣的是, 很顯然地 Java OpenCV Component 本身就具有偵測到所有可能比對結果的 Capability, 只是由於他只提供了 matchTemplate 的 Interface, 因此形成了 Functionality 與 Capability 不相稱的情況. 基於 Encapsulation 的原則, 我們不可能從 Interface 就得知 Java OpenCV Component 的真實 Capability, 但是透過知道 Java OpenCV 原本的 Capability, 卻使得我可以評估花較少的 Effort 去增加 Java OpenCV 的 Functionality, 變相地增加了 Java OpenCV 的 Re-usability.
之前會說希望把 Java OpenCV 看成單一 Component 而不要管 Adapter 身份是因為此 Case 有點特殊, Adapter 本身本來就可能對於原本的 Component Functionality 有遮蔽的作用. 但我認為對於一般 Component 來說也可能會有此現象發生, 如果可以有辦法偵測或是表達 Component 本身的 Capability 與 Functionality 之間的差異, 或許會是一件很有用的資訊.
FireFox 3 效能測試
就在本週之初, 與 FireFox Download Day 同一天, MiningLabs 公佈了一個對於 FireFox 3 的部份效能測試 ( Empirical Study ), 並與 FireFox 2 做了簡單的圖表比較.
大致的重點為 :
- JavaScript 執行效率有顯著改進
- Memory 使用量 FireFox 3 比 FireFox 2 更吃重
- Memory 釋放率 FireFox 3 比 FireFox 2 來的好
而 Memory Release 的改善我很明顯的感受到了 :)
以下圖片引用自 MiningLabs.
 過去 FireFox 2 在我的系統上經常會飆高到佔用 Memory 40 % ( 約 400 MB ) 以上的可怕情況, 這固然跟我使用習慣有關, 經常是開了 30+ 以上的分頁, 包含許多 PDF 頁面. 但是即便在 Idle 時期也不會降下來, 這就是 FireFox 2 本身有缺點的地方了.
過去 FireFox 2 在我的系統上經常會飆高到佔用 Memory 40 % ( 約 400 MB ) 以上的可怕情況, 這固然跟我使用習慣有關, 經常是開了 30+ 以上的分頁, 包含許多 PDF 頁面. 但是即便在 Idle 時期也不會降下來, 這就是 FireFox 2 本身有缺點的地方了.FireFox 3 在本週的使用中, 當我偶爾用到一半刻意開 top 觀察的時候, 多在佔用 Memory 20 % 以下, 而 Idle 時則肯定在 10% 以下. 由於我整天 FireFox 幾乎是不關的, 因此 FireFox 本身 Memory Release 效能的改善也帶動整體工作環境的操作順暢感 :)
改變 PHPList 預設語言 (Default Language)
蠻奇怪的, 雖然 PHPList 可以透過頁面上的下拉式選單改變頁面語言, 但是似乎沒有辦法在設定 (Setting) 中直接改變系統預設語言 (Default Language), 必須登入後再透過下拉式選單進行改變. 在 config/config.php 裡面好像也沒有選項可以直接修改.
本來想說, 好吧, 直接把除了中文以外的 Language Module 移除, 只剩下中文讓你選應該可以吧. 結果把 admin/lan/ 裡面的模組都拿掉之後, PHPList 會出錯進不去 = =
雖然沒有實際驗證過, 但是後來去看 admin/languages.php 的內容可以發現, 如果你把 $LANGUAGES array 裡面除了 "zh-tw" 的都註解掉, 也是會出一樣的問題. 這部份我覺得是 PHPList 程式碼沒有寫好, 預設 "en" 英文語系是一定存在的, 因此只要 "en" 被拿掉就會出現錯誤.
因為懶得去 trace languages.php 的內容, 隨便改了裡面程式碼的幾個 "en" 設定改成 "zh-tw" 都不見效果, 乾脆採取暴力法 :p
在 languages.php 的 $LANGUAGES array 宣告後不遠處, 可以看到一個 if {} 正在設定頁面的相關 language 設定, 因此搶在這之前把 $_POST['setlanguage'] 的內容改掉變成 "zh-tw" 即可, 是故加上一行 $_POST['setlanguage'] = 'zh-tw'; 如下 :
這樣一來登入頁面時的預設語言就會自動切換成繁體中文了, 而原本透過下拉式選單切換其他語言的功能當然不受影響.
要改成其他的預設語言也可以利用同樣的方式, 不過缺點就是所有使用者都會被強迫修改就是了. 希望之後 PHPList 可以讓管理者以及一般使用者設定自己習慣的語言環境阿.
PositLog : 隨意擺放內容的網頁製作系統
PositLog 有別於一般 CMS 系統的地方在於, 他把所有內容, 可能是文字或是圖片, 或是自己隨手亂畫的東西, 都放在網頁上包成一個一個的物件, 使得你可以任意拖拉放置到任何一個位置. 相對於重視版模設計跟 Widget 安插的其他 CMS 系統, PositLog 更加強調利用對於內容的置放來展現個人的風格.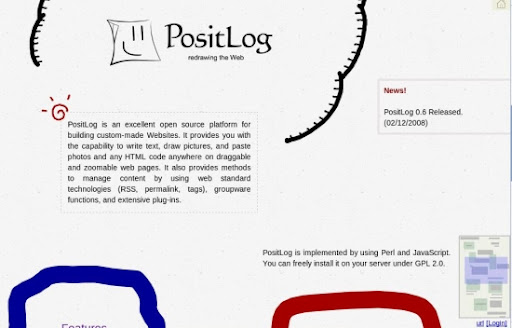
在頁面的右下角, PositLog 提供了一個縮小的 Page Map Overview 以及可以用來調整 Scale 的 ScrollBar, 類似 Google Map 之類的 Ajax 程式也常出現之類的工具.
Page Map Overview 對於 PositLog 來說這是一個必要的設計, 因為在 PositLog 的哲學之下, 個人的網頁內容可能不若一般的網頁來的有閱讀的規則性, 這時候 Page Map Overview 可以讓訪客有一目了然的感覺, 降低整個網頁的複雜感.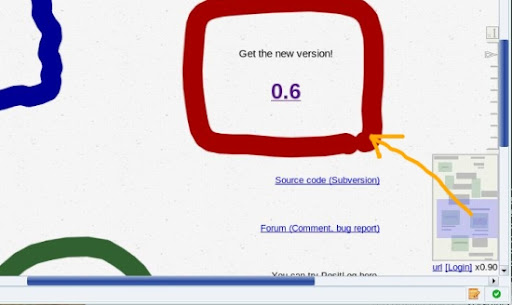
ScrollBar 可以用來調整網頁的大小, 這對於希望在瀏覽時動態放大局部的訪客來說應該是很便利的功能.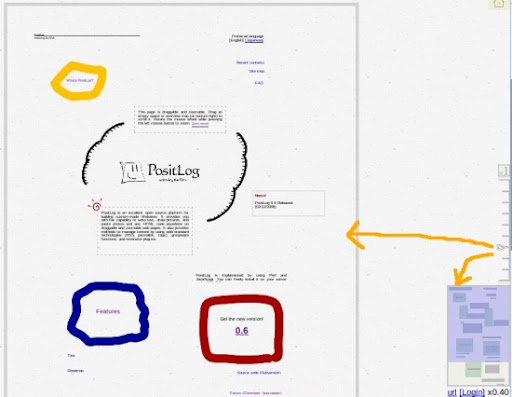
PositLog 的安裝非常簡單, 下載之後在 document 資料夾內有非常詳細的說明. 在系統需求上, PositLog 只需要
- Web Hosting Server, 例如 Apache.
- Perl 5.8+, 一般的系統應該都很容易安裝, 或是已經有內建了
如果懶得裝想直接試試看, 也可以直接在 PositLog 主網頁右下角找到 SandBox 連結. 目前提供 Rich 模式, Simple 模式, 以及測試中的 Wiki 模式. 以 Rich 模式為例, 可以很容易的選擇任何一個物件進行拖曳 (Drag) 移動以及編輯, 同時上方的 toolbar 也可以用來改變這個物件的一些 attributes.
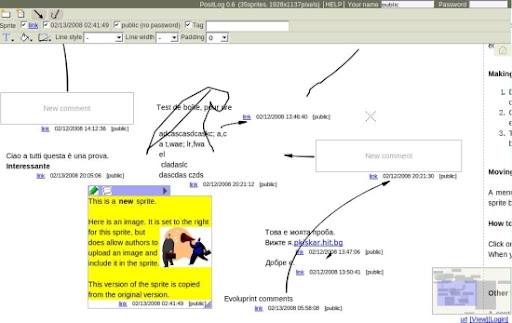
雖然不能說 PositLog 是全新的想法, 而是把過去的兩項很多人想要的 features ( 內容隨意擺置以及簡易放大縮小 ) 結合起來作為主打, 但是的確過去市面上也少見類似的產品. 在這兩項 features 之上, 將有可能發展出許多有趣的應用.
舉例來說, 有許就會有人利用 PositLog 做出一個網頁版的 FreeMind. 利用 FreeMind 製作 MindMap 的缺點在於幾乎只能編寫文字, 同時當整個 MindMap 很大時, 無法快速的看到 Map 全貌, 無法放大縮小 MindMap 等等. 商業化的 MindMap 製作工具對於這些缺點有比較好的改進, 但是仍不夠自由. 試想想如果利用 PositLog 做出網頁版的 MindMap 工具, 對於以上的問題會有比較好的解決, 同時還能夠較為方便地進行多人編輯.
期待在不久的將來就可以看到很多基於 PositLog 衍生出的 OSS 計畫 :)
SourceForge.net Marketplace
昨天收到 SourceForge.net 的通知信了, SourceForget.net Marketplace 正式開張.
在 Marketplace 上, 可以購買 services, 也可以提供 services.
提供 services 的人不一定要是某 project 的維護者, 舉 XAMPP 為例, 目前提供的一個相關 service 是 XAMPP Instalation, 提供者 (seller) 並非原本在 S.F.net 上, XAMPP project 的維護者之一. 不知道這會不會引發在 S.F.net 上的 SEO 問題 : 我的 services 要怎樣比較容易讓需要的人找到呢 ?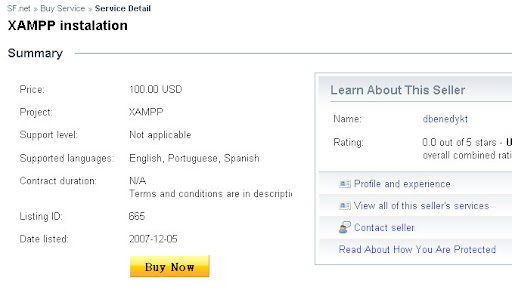
同時從右側的進階資訊 widget, 可以看到此提供者同時提供的其他 services, 以及 profile. 在 profile 內的資訊除了基本資料, 聯絡方式, 以及該 seller 在 S.F.net 上參與維護的 projects 之外,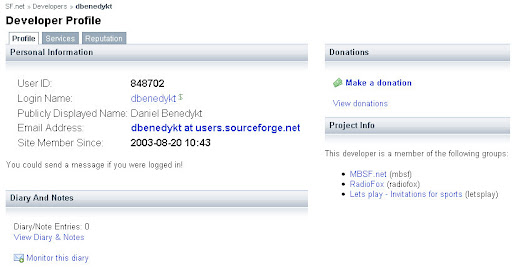
同時可以察看該 seller 的 reputation 評分, 算是某種 customer feedback 的 service quality 紀錄. 但是此 quality 統計紀錄是針對 seller, 而非針對該 seller 的不同 services. 由於同一個 seller 對於不同的 services 能夠提供的服務品質可能有所不同, 因此我覺得如果可以同時提供該 seller 在不同 services 的表現會更好. 左下角有一個 detail 選項, 或許可以看到各次評分的詳細紀錄, 但是因為沒有找到已經有紀錄的 seller, 不知道下面的資訊會如何出現.
另外在 reputation 評分上, 也只有提供 excellent, good, satisfactory, fair, bad 等等模糊的評分, 而沒有辦法根據不同的 software services 有更細節的描述, 或許可以結合 ontology-based [1] 的方式給予更有意義的評分.
身為 OSS portal 的龍頭, SourceForge.net 的 Marketplace 能夠獲得怎麼樣的成功, 相信全世界都在看吧. 如果 Marketplace 能夠在獲得一定的成功, 很可能給投入 OSS 的力量帶來相當大的影響, 同時在 software company 營運模式也會有所改變也說不定. ( 派遣的品格 !? )
References
[1] M. Sensoy and P. Yolum, "Ontology-Based Service Representation and Selection," IEEE Transactions on Knowledge and Data Engineering, vol.19, no.8, pp.1102-1115, August 2007
The Economic Power of BUG Labs + Open Source
前幾天寫了關於 BUG Labs 的一些觀察, 剛好這兩天因為 Lab meeting 的緣故看了一篇文章, 是 Dirk Riehle 的 "The Economic Motivation of Open Source Software : Stakeholder Perspectives" [1]. 在文章的前半段, 作者用了兩張圖來解釋 open source 對於 software company 獲利的影響.
第一張圖 ( referred and re-drawed from [1] ) 如下, 橫軸是潛在的願意購買 customer 數目, 縱軸是 customer 需要付出的價錢. 一個完整的 product 是由 hardware, software, 以及 services 所構成, 而非單只有其中一者. Customer 的需求被 modeling 成為一條曲線 ( 雖然圖上是一條直線, 不過這只是示意圖 ). 當 open source 被引入 software 那個區塊時, 由於對於整體 product 來說, 軟體的研發製作成本降低了, 因此在維持原售價的情況下, software company 可以從每個 customer 身上獲得的利潤就會增加.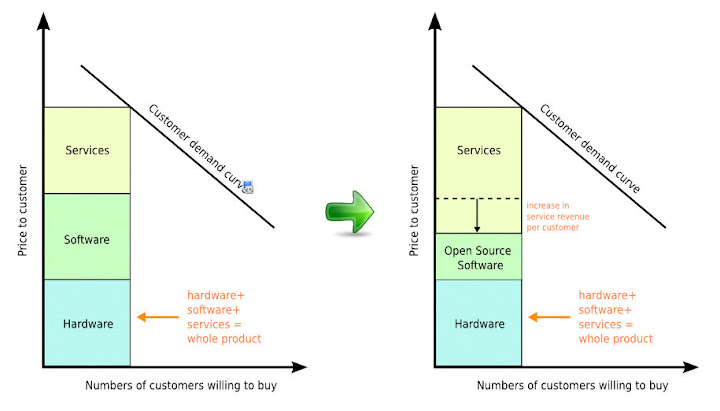 而假使 software company 的利潤完全來自於 service, 而不包含販賣 hardware 以及 software 時可能獲得的利潤, 這時整個 hardware 以及 software 的兩個部份對於 product 就是完全的成本而已. 那麼扣掉 service cost, 剩下的就是 software company 可以獲得的 service profit.
而假使 software company 的利潤完全來自於 service, 而不包含販賣 hardware 以及 software 時可能獲得的利潤, 這時整個 hardware 以及 software 的兩個部份對於 product 就是完全的成本而已. 那麼扣掉 service cost, 剩下的就是 software company 可以獲得的 service profit.
當然 service profit 會根據最後的 service 定價而定, 假設 service 最低價要高於所有的成本, 那們我們就可以在成本與 customer 需求曲線之間括出一塊可以獲利的區域, 在下圖左中以灰色區域標示. 當 open source 取代原本的 software 區塊後, 可以想見的, 因為成本降低, 因此可獲利區域也就隨之增大. 同時藉由價格的調降, 負擔得起該 service 售價的 customer 將會變多, 亦即相對市場就可以變大. 這是下圖右的說明.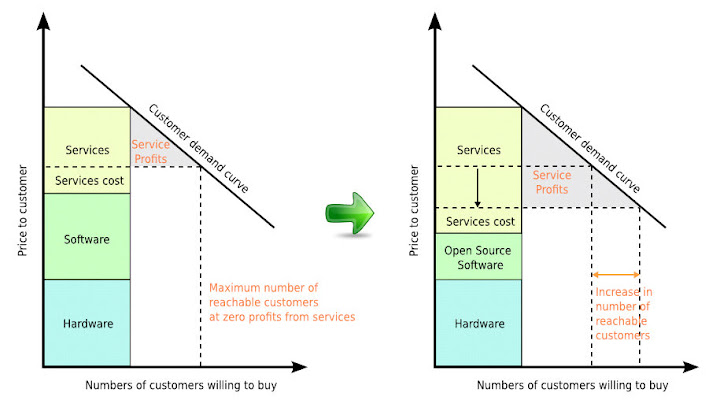 在 [1] 中並未討論到 hardware 的問題. 而如果我們考量 BUG Labs 的願景, 以及所謂 open source hardware 的想法, 很有可能我們可以基於 open source software 之上, 把成本再一次地降低, 使得更多的人可以負擔起一樣的 service.
在 [1] 中並未討論到 hardware 的問題. 而如果我們考量 BUG Labs 的願景, 以及所謂 open source hardware 的想法, 很有可能我們可以基於 open source software 之上, 把成本再一次地降低, 使得更多的人可以負擔起一樣的 service.
下圖左是只有 open source software 的樣子, 下圖右把 hardware 部份用 BUG Labs 取代, 由於硬體部份不再需要一個整體性的產品, 而是可以讓 customer 根據自己的需要選購適用的硬體, 電子製造商將沒有辦法將電子產品的硬體規格掌握在手中, 因此我認為這部份的成本可以降低. ( 事實上也可能帶動 open source software 部份的成本再度降低, 因為 open source software/hardware 的整合會在 project 中完成, 不需要採用者額外進行, 但這裡先不考量這一點 )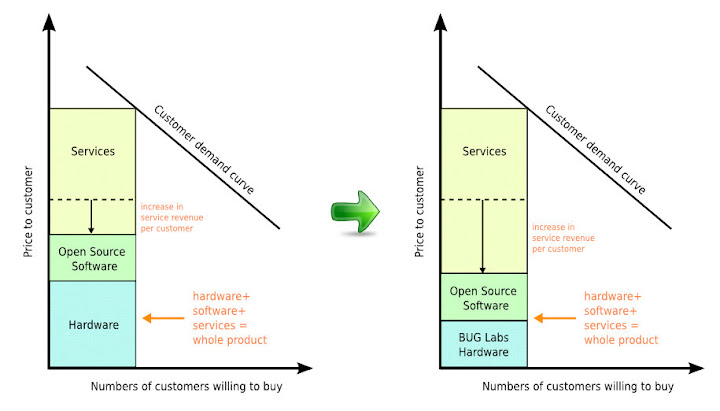 很顯然的, 所帶出的結果就是 service profit 的可調整空間再度變大, 同時有意願購買, 也有能力購買的潛在 customer 市場也變得越大. 對於 customer 來說, 將可以用更加便宜 (或者該說是更加有彈性) 的購買方案, 來獲得需要的 service.
很顯然的, 所帶出的結果就是 service profit 的可調整空間再度變大, 同時有意願購買, 也有能力購買的潛在 customer 市場也變得越大. 對於 customer 來說, 將可以用更加便宜 (或者該說是更加有彈性) 的購買方案, 來獲得需要的 service.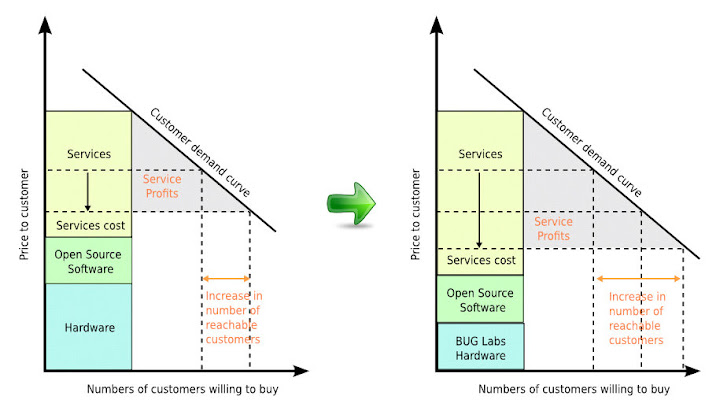 同時在這樣的市場中, Long Tail 的效應可能會更加明顯, 因為新的 service 未必一定要搭配新的 hardware, 在目前的市場中受限於電子製造商, 使得我們要換 service 好像就一定要買新的 device, 手機就是一個很明顯的例子 (如果我可以把現在手機的 300 萬畫素攝影模組移到新手機, 我就不用買新手機的 600 萬畫素模組, 我只需要 300 萬畫素的就夠用了 ).
同時在這樣的市場中, Long Tail 的效應可能會更加明顯, 因為新的 service 未必一定要搭配新的 hardware, 在目前的市場中受限於電子製造商, 使得我們要換 service 好像就一定要買新的 device, 手機就是一個很明顯的例子 (如果我可以把現在手機的 300 萬畫素攝影模組移到新手機, 我就不用買新手機的 600 萬畫素模組, 我只需要 300 萬畫素的就夠用了 ).
References
[1] Dirk Riehle, "The Economic Motivation of Open Source Software : Stakeholder Perspectives," IEEE Software, pp.25-32, April 2007
Who Should be Responsible for the Installation Burden and Risks ?
其實我只是想換個 theme 罷了.
基本上我這個人對於 Desktop Operating System 越來越沒有特定的信仰. 以前無知時只用 Windows, 後來還是有點無知時只用 Desktop Linux, 再後來雖然還是蠻無知的, 不過變成了看心情跟需要, 一陣子用 Windows, 一陣子就改用 Desktop Linux. 昨天剛剛換成了 Mandriva 2008, 好一陣子沒用, 之前是用 Ubuntu. 但是可能因為 KDE 版本有差, 之前沿用的 theme 讓 menu bar 出現了問題, 所有的 icons 跟 quick links 都不見了, 變成空白一條. 弄了幾下調不回來, 索性整個 KDE 相關的設定都重來吧, 反正只是調整幾個地方.
上 KDE-look 找了個看起來不錯的 theme : Domino style engine, 想說裝裝看, 結果到我可以 make 為止, 總共遇到了以下的問題 :
- 缺少 C++ Preprocessor
- 缺少 libX11 development package
- 缺少 libxext
- 缺少 libz
- 缺少 Qt-devel
- 缺少 KDE headers
configure: error: C++ preprocessor "/lib/cpp" fails sanity check
在Mandriva 2008 中, 根據 package manager 的分類, 利用 gcc 關鍵字可以查到的有四個主要的 packages, gcc, gcc-c++, gcc-cpp, gcc-gfortan, libgcc1. 如果只知道要裝 gcc 是不夠的, 因為這裡的 gcc 是指 GNU Compiler Collection, 包含的是 GNU 的各個 compilers 會需要的基本元件, 而各種 programming languages 的 compiler 在架構上是分開的, 也就是還需要裝 gcc-c++ 在這裡才能夠符合需要.
第四個問題的訊息是這樣的 :
checking for libz... configure: error: not found.
Possibly configure picks up an outdated version
installed by XFree86. Remove it from your system.
這個 libz 又是甚麼呢 ? 而且他的提示訊息居然還建議我移除可能的安裝 !? 查了許久才確定應該是 libz.so.1 這個 library, 隸屬於 zlib package, 而且他需要的是 zlib-devel package.
我不想討論這些 installation burden 跟 risks 的問題, 這已經被討論到爛了, 從六年前 Desktop Linux 看起來開始可以讓一般使用者接受時, 到現在一直還是存在這問題.
基本上我覺得這是短時間不可能消失的問題, 應該要被討論的是, 誰應該對這個問題負責任 ? Who Should be Responsible for the Installation Burden and Risks ?
是使用者自己嗎 ? 這樣 Desktop Linux 又變為只有 hacker 可以用的系統. 使用者說, 我只是想換個 theme 阿, 為什麼看起來不相干的準備工作這麼多, 這些動作到底在做甚麼, 為什麼這些不是給我 software 的 developer 處理好.
是 software developer 嗎 ? developer 會說, 我哪管得了那麼多, 那根本是在我的 software 之外阿, 我哪知道不同的 distro. 會預設哪些 library, 哪有美國時間每個 distro. 都去測試, 況且沒幾天就有一個新的 distro. 誕生. 這問題還是丟給 distro. 公司以及 community 解決吧.
是 Desktop Linux distro. 嗎 ? 製作 Linux distro. 的公司說, 奇怪了, 使用者又要可以選擇自由安裝的 flexibility, 又抱怨不知道該裝哪些, 我對於每個 package 的說明不是都寫的很清楚了, 我怎麼可能知道使用者會裝哪些我預期外的 software, 又怎麼可能幫該 software 決定要抓哪些 library 來裝, 這是 developer 的事情阿.
當大家都把責任往外推的時候, 其實就是建立標準的時候了. 這不是個不能解決的問題, 只是沒有任何一方想要擔負這個責任, 因為很麻煩. 之所以麻煩就是因為缺乏標準. 如果可以有一個標準讓所有人去遵循, 結果可能就會出現像 UPnP 的東西, 大家遵照該標準做事就 OK 了.
附帶一提, 結果我還是沒辦法把該 theme 裝起來, 因為 make 後還是出現了看不懂的 compilation error, 這又要誰來解決 ?
UMLSpeed : a C-style light weight UML edition, layout tool
UMLSpeed 是一個 light weight 的 UML edition 以及 layout tool, 以 text-based 方式撰寫 UML-based design, 同時 UMLSpeed 則幫忙產生 SVG UML graphical layout, 以及支援轉換成 XMI 輸出, 或是其他 programming language 的 code generation.
UMLSpeed 作者之所以開發的理由包含 : (引用修改自 UMLSpeed 網頁)
- Graphical UML tools in general suck - why should we, as programmers have to drag and drop stupid graphical things and use a mouse when we could express what we want 10 times faster with a text editor and a simple notation?
- A declarative approach is closer to the mental model used by developers when designing systems.
- Why should we layout diagram components when the computer could do it for us?
- Graphical UML tools are bloated, huge, memory and disk-hogging monsters.
- Graphical UML tools use either a binary data format or XML, which is not particularly friendly to source code control systems.
以第 3 點來說, 雖然說 layout 不可能完全由 computer 取代, 身為吹毛求疵的 designer, 就算 tool 能夠自動幫我做 layout, 八成還是會對結果動手動腳的. 但是基本上 layout 結果的好壞是可以用一些 graph complexity metrics 去評量好壞的, 因此自動產生的結果是可以趨近 designer 會感到滿意的結果, 因而還是可以省下不少功夫, 更別說可以根據 designer 的喜好產生專用的 layout style. 第 4 點的問題應該常用許多 IDE 的 designer 都有相同的感覺吧, 有時候想要功能比較強, visualization 比較好看的 IDE, 卻會有需要大量 resource 的問題. 而 light weight 的 tool 往往功能上就比較被侷限住. 不過這基本上是個很難兩全其美的問題. 唯一的 solution 可能是能夠有一個 easy-customizable 的 IDE, 使得在不同的 environment 下可以很容易作 customization, 得到最需要的功能就好. (不過至今沒有這樣的 IDE 出現, 連 Eclipse 也還做不到)
同樣地對於第 1 點來說, grphical editor 在 visualization 上有他的優勢在, 我相信 graphical software design 只是還沒有突破性的發展, 但是 visualization 在 software design 上至少可以同時結合 design layout 與 design document (design code) 之間的 traceability, 但是像 UMLSpeed 這樣的 tool 就沒有支援這樣的 traceability, 只是因為 UMLSpeed 功能不強大, 所以這樣的缺點也就沒有被放大. 第 5 點也是見仁見智的問題, 採用 XML-based solution 是為了標準化以及延伸性考量, 如果不考慮此點當然可以批評採用 XML 的做法. 但是相對來說, 採用自家標準的 tools 往往容易被淘汰, 至少我就不太會想用, 因為 data 無法被不同的 tools 共用, 換句話說無法被長久保存, 這是很困擾的事情. 要是 UMLSpeed 沒有支援 SVG 或是 XMI 輸出, 我大概也不會想用了.
UMLSpeed 的使用是以 C-style 的 text-based code "programming" 展開, 看圖就很清楚了, (下圖取用自 UMLSpeed 網站 )
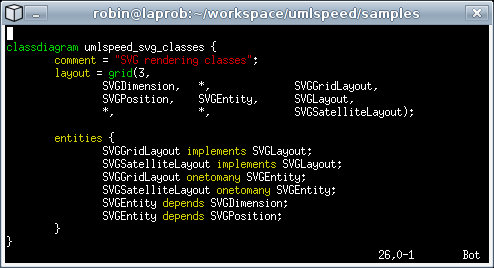
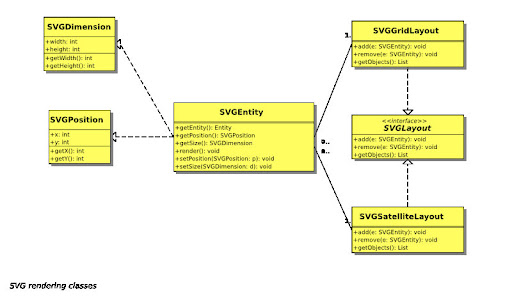 而輸出是以 SVG 格式的檔案輸出, 另外支援 XMI UML 文件輸出. 另外從網站上看來, UMLSpeed 目前支援 use case diagram, class diagram, sequential diagram, 以及 deployment diagram.
而輸出是以 SVG 格式的檔案輸出, 另外支援 XMI UML 文件輸出. 另外從網站上看來, UMLSpeed 目前支援 use case diagram, class diagram, sequential diagram, 以及 deployment diagram.基於 UMLSpeed 的特性, 我認為有幾個不錯的額外用途 :
- Software project 階段性的 design review, code review : 在 software project 進行過程中, 偶爾會需要進行 design review 或是 code review. 這通常是由於 design 或是 source code 已經有點混亂, 因此該部分的 leader 會召開會議, 把所有負責各部分的 designer / programmer 集合起來, 針對整個 design / source code 作 review, 確認每個部分的用途, 以及解決方法是否足夠好. 由於會議人數眾多, 同時進行會議中可無法容忍慢吞吞的大型 IDE, 或是時不時出現的 IDE 怪問題. 因此像是 UMLSpeed 這樣能夠快速進行 pure text-based modification 以及自動 layout 的 tool 應該適合使用. 但是要達成此點, UMLSpeed 跟其他 project 會用到的主流 IDE 之間的 data consistency 問題可能需要被解決.
- Design on mobile devices : 可能會想要這樣功能的人很少, 但是我就是其中之一 :p . 在 mobile devices 上, 或是如最近的 ASUS EeePC 上要跑平常的 IDE 幾乎是不可能的(很辛苦), 但是畢竟我想要的只是在等人或是喝個咖啡時, 可以思索一下最近手上計畫的 software architecture 的一小部分 design 而已, 一個 light weight, 可以馬上產生圖的 tool 就足夠使用了. 這些需求 UMLSpeed 看起來通通符合 :)
- UML programming on Wiki, Blog System : 我們實驗室使用的是 MoinMoin Wiki System, 偶爾會想在 Wiki 上畫個 UML 圖形來說明. 在 MoinMoin 上已經有類似的 plug-ins, 使用上跟 UMLSpeed 有點像, 只需要撰寫特定格式的 UML code, 就可以在頁面上被轉換成為 UML graph. UMLSpeed 應該可以提供在 Wiki 或是 Blog System 上的類似支援
Assessing Open Source : Ohloh.net
我大約在一年前第一次到 Ohloh.net 一逛, 那時整個網站公開還不久, 大約幾個月而已. 一切都還很陽春, 只有大約 3000 多個 projects (其中有些是空號, 因為我那時閒閒沒事寫個 crawler 把人家資料整個抓下來分析 XD), 其中有很多還是空號. 那時的 project assessment 頁面長的像這樣 (幸好有舊資料留著), 以下是舊畫面歐 :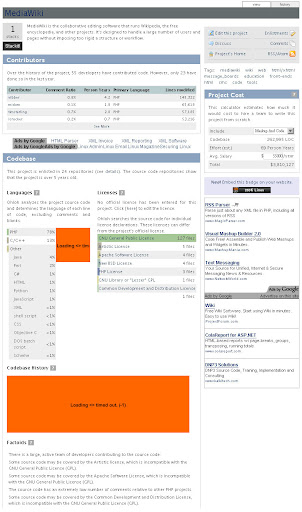
而資料方面只有針對 project 的 contributors 以及 code base 作分析. code base 只有 language 比例分析, license 分析, 以及 code base 大小增長曲線分析. 其中比較有趣的是右方的 project cost estimation, 用來推測此 OSS project 在業界的 cost 會是多少. 當初已經有 community 功能, 但是參與的人還很少. 現在已不可同日而語了, 除了 project 本身的 statistics 統計有更好的分類以及更詳細的內容, 結合 project 相關 news 也使得我們一次可以接收到該 project 進行的最重要發展訊息, 以及 community 內的相關 comments.
一樣是 MediaWiki, 現在比較漂亮, 資訊也比較多了.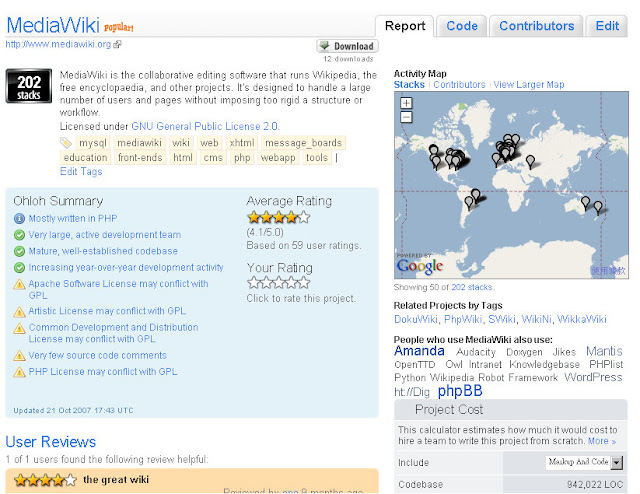
當初會找到 Ohlon.net 的原因之一是因為, 當時我正在參與實驗室的一個 OSS software measurement 相關計畫, 也作了一個簡單的 tool 分析 SourceForge.net 上的 OSS software 其 source code 相關資訊, 包含 programming language 組成, package 組成, quality evaluation 等等. 當時就想到, 雖然 software measurement 的 tools 已經有很多, 但是似乎沒有看到過有作成網站提供服務給 software project 的. 加上當時已經是 open source portal 龍頭的 S.F.net 也沒有類似的功能 ( 直到現在 S.F.net 還是只有基本的 project statistics 統計功能 ), 就想說把做好的 tool 延伸作成 web application, 然後作成一個提供此種服務的網站應該會是很有趣的事情, 比起 OpenFoundry 要學 S.F.net 又學的不好來的有市場機會多了.
沒想到 domain analysis 作著作著就發現 Ohloh.net 早已經開始作一樣的事情了.
Ohloh.net 創始者只有兩個人, Jason Allen 以及 Scott Collison, 有趣的是兩個人都是從 Microsfot 出身的. 在離開 Microsoft 之後, 有感於當時的 Open Source community 缺少統一的 software evaluation 服務, 無法讓其他開發者或是使用者對於有興趣的 OSS project 在 management 以及 quality 上有更深入的了解, 因此創立了 Ohloh.net, 希望不只幫助有興趣的人了解, 也讓 OSS project manager 可以從 engineering 觀點提升自己的 project efficiency 以及 product quality.
一年來 Ohloh.net 穩健地成長, 不僅網站提供的 evaluation angles 越來越多, community 也有逐漸茁壯的感覺. 但我覺得在 Ohloh.net 提供的 services 到 project manager 如何利用這些 services 以改善 projects 還有一些 gap 存在. 或許 Ohloh.net 應該針對他們的服務是否有達到預期的效果作 validity 檢測, 或是以問卷詢問 services 使用者的 satisfaction, 作為未來要增加的新服務之基礎.
Anyway, 這是一個值得時常造訪, 長期觀察的網站 :)
Python-based Parser Generator & ANTLR Python
前一陣子有需要利用 Parser Generator 產生 Python-based Parser,
用來 parsing Java source, 因此就做了一點 survey.
不過出乎意料的, 找不到幾個好用的工具, 大致上 Python Parser SIG [1]
裡列出的都嘗試過了, 有些雖然可以用, 但是沒有人寫好 Java grammer,
要自己寫實在有點麻煩. 有些則是看起來不錯, 也有 Java grammer, 但是卻
無法成功使用, 例如 PyBison [2].
附帶一提如果有人想嘗試 PyBison 的話, 記得裝 PyBison 時要先裝 :
sudo apt-get install python-dev
sudo apt-get install build-essential
最後我是採用有名的 ANTLR [3], 它的 Python Interface 雖然還在發展中,
但是勉強是可以用了, 小 bug 自己改一下就好.
我使用的流程如下, 提供參考(以 MS 環境為例) :
1. 首先到官方網站下載 ANTLR 3, URL : http://www.antlr.org/
2. 解壓縮到特定資料夾, 例如 C:\antlr-3.0\
3. 設定 CLASSPATH, 讓 C:\antlr-3.0\lib\ 底下的所有 .jar 檔案都在
CLASSPATH 設定內, 可以參考這裡的說明進行 :
http://www.antlr.org/wiki/pages/viewpage.action?pageId=728
4. 到 C:\antlr-3.0\runtime\Python 底下進行 python runtime 安裝, 請參考 :
http://www.antlr.org/wiki/display/ANTLR3/Python+runtime
5. 到 ANTLR 網站上下載 Java grammer file :
http://www.antlr.org/grammar/list
嘗試產生 Python-based Java parser, 請參考 :
http://www.antlr.org/wiki/display/ANTLR3/Antlr3PythonTarget
6. 上述網頁上的 Java 1.5 grammer files 有很多個, 如果是使用 Terence Parr
的 grammer file (我是用這個), 則需要對於產生出來的 JavaLexer.py 以及
JavaParser.py 作一點修改. 此修改為在按照上面網頁執行 parsing 的過程中,
會出現語法上的錯誤, 請把錯誤的部分, 從 Java 語法改為 Python 語法即可.
如果有需要對產生的 Parser 作修改的話, 可以參考 ANTLR Python API Doc. :
http://www.antlr.org/api/Python/index.html
References
[1] Python Parser SIG, URL : http://wiki.python.org/moin/LanguageParsing
[2] PyBison, URL : http://wiki.python.org/moin/PyBison
[3] ANTLR Python, URL : http://www.antlr.org/