
Recovering A Missing Simple Configuration File
山不轉路轉, 嘿.
今天花了許多時間在挖某個 Jave-based Tool 的使用方式. 就不說是哪個 Tool 了, 也不打緊.
該 Tool 雖然有把 Source 公開 ( in Limited, Private License ), 但是幾乎沒有註解, 也沒有使用方式. 雖然包成了 Jar, 裡面也有 Applet GUI, 但是並沒有讓你直接使用的意思. Manifest.mf 裡面甚麼有意義的東西也沒寫, 也沒有內嵌 Applet 的 .html 檔案在. 換句話說, 該 Tool 作者使用包 Library 的方式在包一個事實上是 HTML Applet 的工具.
更麻煩的是, 某個必要的 Configuration File 並沒有附在裡面. 沒有該 File, 就算摸清程式運作邏輯, 也不可能讓工具動起來.
但是由於該工具可用的話將省下我一個禮拜以上的時間, 加上該工具的程式碼實在寫的太好了, 不使用跟探討看看可能是我的損失. 必須得想辦法回復此 Configuration File. ( 寫信跟作者要? 拜託... 這哪是可能的選項... 這樣不就讓作者得逞了嗎... )
在仔細去看 Loading Configuration 部分的程式碼之後, 發現了令人高興的事情: 該 Configuration File 的結構看起來十分簡單. 先看看他的 Config Loading 設計大概是這樣表示.
然後呢, 細節看看讀取跟處理的程式碼, 首先是如何取得單一設定值的要求.
接著看該工具怎樣處理 Configuration File 的 Parsing. ( 另外這裡只用 One-Pass 的方法, 讓程式更容易寫也值得筆記, 有時候不是非得要求 Two-Pass 來滿足任性的使用者 )
如此一來就可以得到結論, 該工具的 Configuration File 大概是長這樣.
attr1:value1
attr2:value2,value3,value4
attr3:value5, value6
問題是, 該填寫哪些 Attributes 呢 ?
這時候注意到取得單一設定值的要求都是透過同一個 Method Call Interface 處理的.
Config.get("snippet_dir")
Config.get("score_dir")
Config.get("benchmarkdir")
Config.get("classifier")
因此只要寫個簡單的 Python Script 去掃所有的程式碼, 看看出現同樣 String Pattern "Config.get" 的是哪些部分, 然後把所有的 Attributes 值重建就好了.
當然, 這流程只對結構簡單的設定檔案會有用, 略為複雜的就不太可能成功, 或是需要更複雜的演算法幫助, 例如 Apache httpd.conf 那種 = =
不過這個經驗倒是讓我想到一個問題. 假使不考慮這件事情的複雜度跟需要花費的時間, 是否只要有 Program Logic (Source Code), 就一定可以反推出任何該 Program Logic 所會取用的 External File / Data Source 的最基本 Structure ? ( 最基本 = 使該 Program Logic 可以運作 )
這問題是否等同於, 只要我們確定兩個 Components 之間能夠進行溝通, 且必會進行持續溝通, 我們就一定能夠破解溝通的內容 ?
幾個有趣的 Authentication & Authorization 機制
這幾天在做一些 Survey 時, 看到幾個有趣的 Authentication & Authorization 機制.
* Some images/pictures bellow are extracted from the papers. Please let me know if there is any legel right violation.
1. Graphical Password
P. Dunphy, A. P. Heiner, and N. Asokan, “A Closer Look at Recognition-based Graphical Passwords on Mobile Devices,” Proceedings of the 6th Symposium on Usable Privacy and Security, July 2010.
這篇 Paper 提到了事實上 PIN 機制備使用率偏低的情況 (畢竟忘記密碼而不能想打電話就打很麻煩, 要處理更麻煩), 同時就算有設密碼, 也可能是很簡單的 0000, 1111 這種 (我就這樣 @@).
作者們提出利用現在手機上的儲存的私人照片, 讓使用者自行選定某張照片, 或是某個 Combination 作為密碼, 取代原本的數字或字母組合. 其中也探討及引用了人對於影像記憶的能力, 怎樣自動選擇容易被記住的影像, 以及私人照片對於旁邊不經意偷看的人不容易記得等等.
不過我覺得這方法還有一些討論的空間, 像是 (1) 私人照片怎樣可以自動避免出現太過侵犯隱私的, 例如只篩選出旅遊照, (2) 影像組的順序本身往往有 Semantic Meaninig, 是否還有利用空間等等.
2. Eye Tracking
A. D. Luca, M. Denzel, and H. Hussmann, “Look Into My Eyes! Can You Guess My Password?,” Proceedings of the 5th Symposium on Usable Privacy and Security, July 2009.
這篇是整合 Eye Tracking 技術到 Authentication & Authorization 中, 利用你的眼睛注視定點的移動順序, 作為 Password 來通過 Authentication. 主要的優點是, 許多側錄或是旁邊偷看的攻擊方式幾乎就都行不通了.![]()
雖然有趣, 但是實際應用上還有很長的路要走, 要有相當的軟硬體支援才行, 無形中也限制可應用的情境.
3. Changed Context
V. Hourdin, J. Y. Tigli, S. Lavirotte, G. Rey, and M. Riveill, “Context-Sensitive Authorization in Interaction Patterns,” Proceedings of the 6th International Conference on Mobile Technology, Application Systems, Sept. 2009.
此篇利用 Observing Interaction Behaviors 作為 Contextual Information, 來判斷已經過了 Authentication 的使用者, 是否在 Valid Session 中, 被 (偷) 換成其他的真實使用者. 換句話說, 是作為輔助性的機制, 去避免使用者因為任何情況被置換了...比如說忘記 logout 之類的.
不過我覺得這篇 Paper 裡沒有舉出比較具體應用的例子是比較可惜的地方. 因為這方法不一定在任何 Cases 下都會很好用, 因此哪些類型的系統適合, 就變成很重要的資訊.
4. Mode Switch based on Context
J. Seifert, A. D. Luca, B. Conradi, and H. Hussmann, “TreasurePhone: Context-Sensitive User Data Protection on Mobile Phones,” Proceedings of the 8th International Conference on Pervasive Computing, pp. 130–137, May 2010.
現在的高階手機通常可安裝相當多的應用程式, 自然也有相當多的 Data 儲存在裡面. 有不同的 Data 種類, 包含工作, 理財, 家庭, 朋友等等... TreasurePhone 的概念是, 不同的 Data 應該要只允許在相對應的情境下可以被取用. 譬如說工作相關的 Data 就應該只有在工作的情境下可以被取用, 這樣就可以避免被家人或是朋友看到.
作者們把該取用情境稱為 Sphere, 而 TreasurePhone 即根據目前的 Sphere 來決定應該設定為哪種工作模式.
5. Distorted Pictures
E. Hayashi, N. Christin, R. Dhamija, and A. Perrig, “Use Your Illusion: Secure Authentication Usable Anywhere,” Proceedings of the 5th Symposium on Usable Privacy and Security, July 2008.
這篇也很有趣, 應該要跟 P. Dunphy et al. 那篇一起聯想. Authentication by Distorted Pictures 的概念其實就是: "熟悉的人不需要獲得全部的資訊就可以拼湊出正確的資訊". 舉例來說, "pasword" 雖然少了一個 s, 但是看的人直覺就知道是 "password".
所以可以進一步確保, 只有知道原本該照片的 Semantic Meaning 的使用者可以準確答出. Paper 裡面也有討論到在 Distorted 後, 可能產生 Sementic Meaning 混淆的情況, 像是黑白外殼的電池跟熊貓.
6. Musical Password
M. Gibson, K. Renaud, K. Renaud, and C. Maple, “Musipass: Authenticating Me Softly with “My” Song,” Proceedings of the New Security Paradigms Workshop, pp. 85–100, Sept. 2009.
列出這篇單純是覺得有趣. 作者們想要用 Music 取代以字母跟數字為主的密碼. 進行 Authentication 時, 是透過輸入一組旋律的方式來進行驗證.
不過我個人是認為, Musical Password 示好想法, 但是依照這個方向跟設定是錯的. 因為缺點太多. 雖然有些缺點在 Paper 內有想利用一些方式解決, 例如 Training, 但是比起傳統的 PIN 跟 Image-based 方法實在沒有太多優勢, 作者自己也在 Paper 裡面承認這點.
7. Context Sensor Data
A. Nosseir, R. Connor, C. Revie, and S. Terzis, “Question-Based Authentication Using Context Data,” Proceedings of the 4th Nordic Conference on Human-Computer Interaction, pp. 429–432, Oct. 2006.
這篇跟我 Master Thesis 有關, 但是當時真沒想到還有這樣的應用 @@
這篇的作者們利用一般人生活環境中可能有的 Context Sensors, 所回報的 Data, 自動產生 Quesitons, 用來作 Authentication 使用. 比如說, 你今天幾點離開的家門, 幾點泡的咖啡, 泡了幾人份等等... 不是很親密且持續觀察你行為的其他人, 很難正確地做出回答.
不過呢, 我認為這個系統有個致命的缺點... 一旦攻擊者知道你在用這個系統, 就完了 = = , 因為答案就在你的生活中...
Graph Cut Image Segmentation with A Center ( Star Shape Prior )
在找某種 Tool 的過程中發現這個有趣的工具: Segmentation Graph Cut
它事實上是這篇 Paper 內容的實作:
Olga Veksler, "Star Shape Prior for Graph-Cut Image Segmentation," European Conference on Computer Vision, pp.454-467, 2008
雖然 Google Code 頁面上沒有明寫, 不過猜 Project Owner 就是作者本人. 因為 Tool 裡面包含的 Samples 跟 Paper 內容的範例圖都一樣, 同時如果你從 SVN 上 Check-out, 而不是只抓 Binary 的話, 會發現 Repository 裡面還有兩篇相關的 Paper PDF, 如果不是自己有版權, 應該不至於敢直接放到 Repository 裡面吧.
Anyway, 這篇 Paper 跟這個 Tool 的重點很單純, 就是要把所謂的 Star Shape 加到利用 Graph Cut 作 Image Segmentation 的方法中. 至於所謂的 Star Shape, 採用 Paper 中的定義:
A star shape is defined with respect to a center point c. An object has a star shape if for any point p inside the object, all points on the straight line between the center c and p also lie inside the object.
如果用圖來舉例解釋的話, 大概是像下面的 (a) 不管怎樣裡面的任一點都可以做為 Center C, (b) 只有部分的點可以做為 Center C, 因為有些點無法讓 P 的條件符合, (c) 不管哪裡都不存在 Center C 可以讓 P 的條件符合.
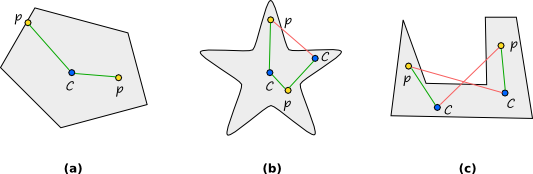
其中 (a) (b) 的情況都符合 Star Shape 的定義.
工具的 Binary Release 本身需要 Visual Studio 2008 的一些 Libraries, 我在 Windows 7 沒法安裝, 直接從 SVN 抓下來 SRC, 裡面有 C++ Code ( 尚不清楚實際用途 ) 跟作為 GUI 的 Python Code. 直接利用 GUI.py 執行極可.
請注意會需要 wxPython 跟 Psyco, 沒有的話會要安裝才能繼續執行.
工具目的單純所以容易操作. 載入圖片後利用滑鼠在圖片上指定 C 跟 P. 左鍵 Click 兩下會出現藍色點是 C, 一下的話會出現黃色點是 P.

我本來以為會以 P 作為切割邊線的決定條件的, 但看來不是這樣, 像上圖那樣標記, 最後還是會抓到整朵花 (右下的紅框是結果, 是我額外貼上去的, 工具本身是會呼叫你的看圖程式去開結果圖). 但是如果舉個極端一點的例子, 像是這樣:

基本上還是會割到 Boundary 為止, 我猜跟裡面用到的 Graph Cut 演算法有關. 不過我的 Image Processing 只有到基本的傅立葉程度 = = , 這個就沒法猜了.
當然 Title 寫 With A Center 是有理由的...
在一般的情況下, 只要標記上 C, 不用 P 也是可以抓到, 像是這樣:

而且運算時間算是蠻快的, 扣掉開啟看圖程式的時間, 可以直接把結果接到工具畫面輸出的話, 應該是幾乎到無感的程度吧.
很有趣, 改天有空再來從 Python GUI 研究看看是不是可以直接使用裡面的 Kernel Function, 接到別的程式上.
That's Not What I Sent
其實這是上週的事情了, 只是很忙沒空寫下來.
上週在忙的事情, 其中一件是要開始電機系網站, 教授資料部分的 Data Migration. 因為目前的網站在教師資料部分, 超過 90% 的資料比例是用 HTML 網頁方式保存的, 不是用 Database 保存資料. 加上新網站是計算機中心統一跟外面的公司購買, 資料庫系統跟格式都大不相同, 對方也沒有 Migration 的服務 ( 就算有計中應該也不會想付這錢 ), 變成要人工去做. 不過這不是重點啦~
因為資料量太多了, 而且每個教授的資料維護本來就不是我們負責的工作, 所以就乾脆提前開放教師帳號, 給每個教師的工讀學生去處理 Data Migration.
開放帳號, 當然就是要寄出帳號跟密碼啦~ 這時候就發生了此篇的重點事件, 有位同學 ( 幫某教授更新資料的, 簡單說就是新網頁系統的一般使用者之一 ) 打了分機電話過來詢問:信件裡面的密碼有一部分變成笑臉男了, 怎麼辦 ?
沒有啦, 怎麼可能真的變成笑臉男, 這樣就變成 Security 的問題了. 其實只是變成一個驚訝臉的表情符號 ( 找不到完全一樣的, 用類似的替代 ).
沒記錯的話, 該同學用的 Mail Client 是 Outlook 的樣子. 然後他不知道原來 8o 會變成表情符號, 所以也無法自行 Decode 回去 ( 其實我也不知道 @@ ), 原本的密碼應該是 8#fdt8o
這問題有趣在於,
1. 這不是因為 Security Leak 產生的問題
2. Software 沒有錯, 也提供了調整或關閉的方法
3. 收信者不知道其實他有能力讓 Software 呈現正確的訊息
4. 收信者無法自行在腦中作 Decoding
5. 寄信者在收信者沒有 Feedback 前, 完全不會知道這問題的發生. 當然, 也無法預知會有這個問題.
不知道如果從 Sender 端跟 Receiver 端分別考量這個問題, 是不是可以解決. 這樣的問題應該不只存在於 Mail System 中. 更加極端地說, 這是系統中不同 Components 之間的 Trustworthiness 問題. (下圖大小很難調, 不管了, 請將就)
在 Receiver 端要提供更加 User Friendly 的 Active Configuration Notification, 而不是倚賴 Receiver 的使用能力. 而在 Sender 端則是提供 Active Warning 的服務, 類似 Automatic Spelling Check. 不過要做到這些, 其實有許多附加的問題要解決, 不知道是否有更簡單的解決方法呢 ?
Know both Design Abstraction and Implementation Detail ever Resourceful
為了取這個標題, 還特地去查某句成語的英文一般都怎麼說 XD
昨天在處理實驗室 MoinMoin Wiki 出現的一個奇怪的問題. 某個特定頁面只要進行瀏覽, 就會導致 MoinMoin 整個 Crash, 一點 Process 也不留. 自然, 直覺就是該頁面內容有什麼奇怪的東西, 或是內容在磁碟上有毀損, 導致 MoinMoin 讀到該頁面內容就會出現 Exception 而掛掉.
但是在想要近一步去檢視該頁內容是, 猛然發現, 其實我不知道 MoinMoin 是怎樣處理 Page Data 的. 我既不知道 Page Data I/O 的部份在哪, 也不知道 Page Data 平常是保存在哪.
本來, 閉著眼睛也可以大概畫出一般 Wiki System 的 Architectural Design Abstraction, 主要的 Components 有哪些, 各自的責任也清楚. 但是單知道這些對我現在要解決問題幫助卻不是很大.
作為一個在唸 Ph.D. Program 的 Programmer, 這樣的事情真的是很不應該的, 但是還是發生了, 因此特別寫下這個標題--雖然別人看來可以摸不著頭緒--來警惕一下自己.
幸好簡單查一下 MoinMoin 的資料, 馬上就看到 MoinMoin 在 Data 的保存上十分簡單, 直接利用現成的 File System 作儲存而已. 這樣一來馬上補足了在 Data Repository 部份的一些細節, 也就一下子找到 Page Data.
MoinMoin 的 Page Data 存放在 /data/pages/ 中 ( 實驗室的資料比較敏感, 以下用電機系網路服務使用手冊 Wiki 作例子 ),
每個頁面直接用 Relative Page Path 作為 Directory Name, 其中 "/" 以及 "-" 之類的就用特殊符號取代, 像是 (2f) 跟 (2d).
在每個頁面的 Directory 之下, 有幾個主要的檔案跟資料夾, 名稱一看就很清楚, 不一一加註, 只舉頁面內容來說, current 檔案紀錄目前的版本, 而 revisions 資料夾裡面存有所有的歷史頁面資料. 因此實際的頁面資料是存在 revisions 資料夾裡的, 把每個頁面 cat 出來就很清楚了.
從這點也可以看出來, 其實大量頻繁的網頁修改, 在 MoinMoin 系統中是很吃硬碟資源的.
知道 MoinMoin 資料存放的細節後就更有趣了.
目前手上有些給實驗室用的小東西, 過去不是很清楚要怎樣把其輸出直接送到實驗室的 MoinMoin Wiki, 這樣一來其實可以直接在 File System Level 作手腳. 繞過 MoinMoin 本身, 直接輸出到 Data Repository 中, 只要內容格式符合 MoinMoin 語法, 跟 Revision History 等 Meta-data 有正確的填寫, 就能夠被 MoinMoin 讀取, 出現在 Wiki 頁面系統上了.
Know both Design Abstraction and Implementation Detail ever Resourceful.
我要把這句印出來貼在座位旁 :p
Play Sound using Virtual MIDI Piano Keyboard
其實主要步驟只要照著 Compdigitec Labs 的這篇 Virtual MIDI Keyboard In Ubuntu 作即可.
不過實際上在我的系統上有些微的不同. 因為對整個 Sound System 不熟悉, 沒有辦法理解是怎麼回事, 姑且記下來當作 "這樣設定也可以" 看吧.
先記一下安裝的部份, 共需要 ( Package Name 以 Mandriva 2010.1 上的為準 ) :
1. qjackctl ( JACK Audio Connection Kit )
2. zynaddsubfx ( ZynAddSubFx )
3. vmpk ( Virtual MIDI Piano Keyboard )
其中 vmpk 是要作為虛擬 MIDI 鍵盤的主介面. 雖然後來發現 ZynAddSubFx 也有虛擬鍵盤介面, 但是變更 Keyboard Map 設定跟其他各種設定上, 感覺 vmpk 比 ZynAddSubFx 來的方便.
而 qjackctl 是 Connection 控制器, 負責把 vmpk 作為前端介面, 輸出的 MIDI 資料導引到 ZynAddSubFx, 再到實體的音效硬體/音效卡作播出. 因為 vmpk 本身其實就是單純的虛擬鍵盤子系統, 因此到實際播出前需要 Synthesizer 幫忙處理合成. ZynAddSubFx 在這裡就當作 Synthesizer 使用.
接著作 limits.conf 設定,
sudo su -c 'echo @audio - rtprio 99 >> /etc/security/limits.conf'
sudo su -c 'echo @audio - memlock 250000 >> /etc/security/limits.conf'
sudo su -c 'echo @audio - nice -10 >> /etc/security/limits.conf'
把系統 reboot 後重新開啟 qjackctl, 並利用 "Start" 按鈕開啟 JACK server ( jackd ). 這時候如果遇到開啟失敗的訊息, 請利用 Messages 按鈕看錯誤訊息. 如果是 server 啟動失敗, 請把 ALSA 重新啟動試試看. ( alsa command 的位置可能根據系統有所不同 )
sudo su -c '/etc/init.d/alsa force-reload'
啟動沒問題的話, 開啟 ZynaddSubFx 以及 vmpk, 然後利用 Connect 按鈕設定上面說的, 從 vmpk 到 ZynaddSubFx 再到音效裝置的 Connections.
照 Compdigitec Labs 的文章中之示範, 音效卡代號應該會出現在 ALSA 分頁中, 但是我的沒有 ^^b, 所以先只有把 vmpk 的 Output 接到 ZynaddSubFx. 接上的方法很簡單, 用滑鼠把 vmpk Output 拉到 ZynaddSubFx 上放開即可.
而 ZynaddSubFx 到音效裝置間的連結, 則是改在 Audio 頁面中搞定. 其中 playback 1 是左聲道, playback2 是右聲道, 其他的在我系統中無作用.
這樣設定完就 OK 了~, 把視窗 Focus 移到 vmpk 上面, 對應的鍵盤按下去就可以看到琴鍵變化, 以及發出 MIDI 音效. 在 ZynaddSubFx 視窗中也會有對應的變化.
其實當焦點移到 ZynaddSubFx 上也是可以有同樣的反應. 不過如上所述 vmpk 較占優勢的理由, 本篇還是以 vmpk 作為 Front-End 為主.
最初學 Programming 時的作業樂趣
正在看一篇跟 Code Readability 相關的 Paper, 不知怎忽然想起大一剛進成大電機時, 學 Programming 的作業...
當然, 當時我學 Programming 與其說是上計概課學的, 不如說是自己學 + 認識的資工學長作榜樣居多, 但是書本上的練習跟上課的練習還是有差, 特別是你不想端出去的作業比別人差, 而且我們的計概課也不是一般呼嚨用的計概課.
我印象深刻的是一個 Hanoi Tower 的作業. 說到 Hanoi Tower, 其實我國中的時候就用數學的角度解過這個問題了, 但是寫程式是另外一回事. 稍微熟悉的人應該都知道, Hanoi Tower 是練習 Recursion 的基本入門題之一. 但是該作業有趣的是, 附帶了一個額外的加分題: 請用 Non-Recursive 的方式寫出解 Hanoi Tower 的程式 (當然, 要 step-by-step 輸出).
* 其實這題目有些書在 Recursive 章節後面也會加. 只是小大一是不會主動去看後面的練習作業題的 XD
那時候其實還不太會用 Search Engine, 而且 Google 在台灣也還沒有知名度, 很"傻"地就一頭鑽下去想解法, 以及怎樣寫成 Program, 還附帶要寫成 Document.
最後當然是有寫出來 ( 還上台介紹 = = 我大學生涯中第一次上台 ), 利用某些規律可以知道在三個 Towers 處在特定的 State 時, 就應該怎樣做 Transition 來到達下一個 State, 並且達到 Optimization. 也當然啦, 當時小大一是不會知道其實我在畫 State Transition Diagram 的 XD
其實在寫成 Program 以前, 我在找規律以及推導的過程, 本身就是 Programming 最重要的邏輯觀念之一. 可以在憑空找以及運算這些邏輯之中得到樂趣, 是後來可以成為一個積極的 Programmer 最重要的條件之一.
後來的作業印象中就比較偏向 Application 導向, 例如寫簡單的火車訂票系統之類的. 雖然其中也有很重要且複雜的 Scheduling 問題存在, 但是因為整個系統要考慮的 Functions 變多, 反而重要的 Scheduling 問題對於當時只是程式初學者的人來說, 變得不是那麼重要與有趣.
直到現在, 可能因為我們 Lab. 的大家習慣以系統角度通盤思考事情, 因此也反映到出給學生的作業上. 現在的作業寫滿整整兩頁 A4 的說明是基本 ( 一次作業一題而已歐 ), 前兩年甚至出現了高達六頁的說明 ( 印象中, 一樣是一次作業而已 ). 而看這作業說明的學生, 大多只是剛上大學, 剛要開始認真接觸 Programming 而已...
我們不禁應該思考, 這樣的作業美其名可以讓學生提早從整個系統角度思考 Programming, 可以更加貼近真實生活中的應用系統, 但是效果真的有比當初的 Hanoi Tower 好嗎 ? 如果我們並不期許計概課裡的所有學生最後都是一個好的 Software Engineer, 或是都要走 Pure CS 路線, 或許多些 Hanoi Tower 的題目能更引起學生自發的思考, 也更加容易傳遞 Programming 課程每次的教學重點.
Proceedings Review of the 5th International Conference on Software Engineering Advances (ICSEA 2010)
今年雖然有投上 ICSEA 2010, 但是受限於早先已經申請了到 SEKE 2010 的補助了, 不太方便再跟國科會申請, 只好放棄 Nice 之行, 委託也有投上的另位實驗室同仁代為進行 Presentation.
不過帶回來的 Proceedings 還是應該掃過一次. 雖然 ICSEA 不算是頂好的 SE Conference, 但是我還蠻喜歡逛這種 Proceedings, 有時候會發現一些不成熟但是有趣, 具啟發性的想法 :)
1. A. Martin, R. Mazalu, and A. Cechich, ''Supporting an Aspect-Oriented Approach for Web Accessibility Design,'' pp.20-25
Software GUI Design 事實上從 70 年代以來就沒有公認的 Process. 雖然期間曾經有一段時間出現了各種 Methodology, 也有類似於 OO 分析的方法出現, 但是始終對於應該在何時開始考量 GUI, 中間的 A/D/P Process 與 Application 本身的 A/D/P Process 關係, 以及後續的 Maintenance 議題, 沒有一個串起來的發展系統. 而 Web GUI Design 近年來的思考似乎也漸漸向 Conventional Applications 靠齊... 除了看起來 Style 不太一樣, 其實操作模式都跟 Conventional Applications 很類似. 如果我們把 Browser 換成一般的 Client-side Interface, 似乎就也沒什麼兩樣. 我倒是很期待看到 Web GUI Design, 或是討論 Accessibility 議題是, 如果針對 "User 使用同樣的 Client-side Interface (Browser) 來看所有的 Web Applications'' 這點作討論的話, 會出現什麼樣的 Papers.
2. H. P. Breivold, D. Sundmark, P. Wallin, and S. Larsson, ''What Does Research Say About Agile and Architecture ?'' pp.32-37
我對於這篇的 Summary 不太意外, 因為整篇直接嘗試把 Agile 對於 Architecture 的影響在不限定 Context 的情況下去評估, 本身很可能得不到任何有意義的結論. 對我來說 Agile 其實是不適合直接跟其他的 Paradigms 去比的. 更進一步來說, 大部分的 Paradigms 都有它最適合的使用情境, 硬是要拉在一起比意義不大. 比較重要的是, Managers / Developers 是否可以在適當地時候得到該使用哪種 Paradigms 最有利的建議. 以這篇來說, 如果可以鎖定目前最常使用 Agile Paradigm 的開發情境, 再歸類此情境下最常被採用的 Architecture Design 類型, 再來作討論會比較有意義.
3. M. Basdavanos and A. Chatzigeorgiou, ''Placement of Entities in Object-Oriented Systems by Means of Single-Objective Genetic Algorithm,'' pp.70-75
這篇讓我想到五年前在實驗室的一個沒有完成的計畫. 該計畫的其中一個觀念就是把 Use Cases 當作 Capabilities 的集合來分析, 所有的 Objects 事實上是 Capabilities 的 Distribution. 這樣做的目的很抱歉無法在這裡說明...畢竟這是個不知道什麼時候會活起來的計畫. 不過可以理解在這篇裡面嘗試把所有的東西都打散, 不要依照直覺與經驗式的去找出 Objects 的想法. 但是在此之前的前端分析方法 Papers 中沒有明說...我覺得這對這篇 Paper 的 Justification 還挺重要的. 另外值得注意的是 Second Author 是 Alexander Chatzigeorgiou, 他跟 Nikolaos Tsantalis 的幾個 Works 真是令人印象深刻, 也讓我對這篇的下一步充滿期待阿...
4. M. Gebhart, M. Baumgartner, and S. Abeck, ''Supporting Service Design Decisions,'' pp.76-81
這篇左看右看總覺得, 跟 OO 的某部份分析方法好像阿(笑), 只不過一些關鍵字, 像是 Class, Coupling, Metrics, 沒有被拿出來, 也沒有被 Formalize 就是了. 我想, Service-Oriented Computing 跟 Functional Paradigm 以及 OO Paradigm 之間的關係, 應該在未來的兩年內就會很明朗了, IEEE TSE 上已經開始有 Paper 表明立場了...
5. H. Kaindl, J. Falb, S. Melbinger, and T. Bruckmayer, "An Approach to Method-Tool Coupling for Software Development," pp.101-106
因為這個方向, 實驗室也有一個延續性的計畫方向在做, 不便評論太多, 但是這個題目很實用也很有趣. 簡單來說, 現在的 Software Process/Paradigms 越來越多, 裡面要做的事情越來越細也越明確, 但是又不是每個細項都要在每一次的 SDLC 中被作到. 另一方面, 不管是 Commercial 或 FLOSS 的"工具"也越來越多, 同時各項工具目的用途有重疊也有相異, 有些共享標準有些沒有. 好的工具很重要, 如何知道根據工作選與使用好的工具更加重要... 大概就是這樣的問題.
6. M. Y. Santos and R. J. Machado, "On the Derivation of Class Diagrams from Use Cases and Logical Software Architectures,,," pp.107-113
從 Use Case Diagram 到 Class Diagram 的自動生成也是一個老問題了, 近幾年來幾乎沒有什麼新的東西出現, 主要還是這技術本身有 Accuracy, Reliability 的問題在, 連帶影響 Efficiency & Effectiveness... 太小的系統用處不大, 太大的系統又沒人敢/有必要用. 不過這篇 Paper 倒是提供了另外一個角度的思考: 如果在 Transformation 過程中, 加入了 Domain-Specific 的 Constraints 進去, 是否會讓這個技術有 "轉換" 之外的價值產生 ?
7. K. Popovic, Z. Hocenski, and G. Martinovic, "Do the Software Architects get the Need Support for the Job They Perform ? pp.123-128
這篇我只對最後一個整理出的 "What Architects Do and What They Need" 表格有興趣. 要我自己整理可能都要花個幾天想想.
8. S. Gunther, M. Haupt, and M. Splieth, "Agile Engineering for Internal Domain-Specific Languages with Dynamic Programming Languages," pp.162-168
我覺得這篇還不錯, 從務實的的角度把 "大家其實都是這樣作 DSL 的", 以及 "這樣作 DSL 比較會有人用" 給整理出來. 其實 Domain-Specific Language 可以說無時無刻都存在, 只是透過 Formalization / Standardization, 以 Language 的角度作整理, 才能有效地利用/重利用. 而建立於既有的 Programming Languages 之上, 可以省去建立 Compiler 的麻煩, 同時如果跟自家產品用同一種 PL 就有更多 Traceability Management 上的好處. 不過現有的 Dynamic Programming Languages 在被利用來建立 DSL 的侷限性, 例如適用的 Domains 等等, 似乎還是一個未知的問題 ?
9. S. C. de B. Sampaio, E. A. Barros, G. S. de A. Junior, M. Jose, C. e Silva, and S. R. de L. Meira, "A Review of Productivity Factors and Strategies on Software Development," pp.196-204
就只是關於 Productivity Factors 以及 Productivity Improvement Strategies 的整理. 可參考用.
10. M. Breu, R. Breu, and S. Low, "Living on the MoVE: Towards an Architecture for a Living Models Infrastructure," pp.290-295
我只能說, 有夢最美阿... 基本上有統一的 MetaModel. 以及不斷被建立的 Adapters 當然是很理想. 問題是一個不需要時常被更新的 MetaModel, 勢必造成不同 Models 之間的實質差異性會很大, 這樣的話能夠透過 Adapter 去解析與管理不同 Models 的能力就變低. 退一步來說, 在 Programming Languages 的轉換問題上, 也曾經造成一陣子的風潮, 但是現在幾乎沒有看到人在談了, 取而代之的是從根本建立一個共通的中介碼, 然後不同的 Programming Languages 則是根據用途變成不同 "Interfaces" 的感覺. 但是連在 Programming Languages 階段的改變, 實質效益跟使用度/接受度都還沒有明顯的功效之前, 我覺得一下子拉到 System Modeling 的層級還太早.
11. N. M. Carod and A. Cechich, "Cognitive Profiles in Understanding and Prioritizing Requirements: A Case Study," pp.341-346
雖然我認為如 Paper 內所提到, 此篇的 Study 結果也很難被用來佐證在其他 Context 下, 此方法的有效性, 但是 "感覺應該會有效" 卻是很直覺. 要想看到比較大規模的 Case Studies 也許還要等好一陣子, 畢竟這個想法的相關工具跟實驗應用的商業公司數量感覺都還不算多. 同時如何建立 Cognitive Profiles 在不同的應用情境下似乎又是一個不同的問題. 或許把此想法跟 Visual Software Requirements 結合會有意外的發展...
12. G. Grambow and R. Oberhauser, "Towards Automated Context-Aware Software Quality Management," pp.347-352
這篇 Paper 在 Abstract 以及 Solution Approach 一開始所描述的其實是一個 Too Good to Be True 的理想, 貌似我在碩一快結束時提的碩士論文題目也是類似的想法, 而且還包含更多 SDLC 的東西在 Context-Aware 的概念下, 所以我完全可以理解這篇作者的 "偉大願景" :p 很遺憾理想跟事實總是有相當落差... 從 GQM 出發我不認為是個好選擇, 因為 GQM 相當倚賴經驗法則去建立 Model, 要想全自動化需要先建立相當程度的假定 (Assumptions), 而這又會讓 GQM 變得不好用. 從這篇所引用的 Agent-based GQM Papers 全都是出自不太有名的會議論文也可略窺一二.
13. C. L. Reis and J. M. Pacheco, "Minimizing CO2 Emissions in a Computing World," pp.395-399
跟內文無關, 只因為最後一頁的那張圖 (話說, 內文也沒直接引用到這張圖阿... = =). 這圖很有意思, 最近有個題目的關係, 正在重新思考 Distributed Computing, Grid Computing, 到 Cloud Computing 之間的關係, 跟演進的理由. 這張圖在某個角度上還蠻符合我目前的想法. 這三個名詞都是指不一樣的東西, 雖然核心技術會感覺很像, 但是本來 CS 很多技術都是舊的, 只是當 User & Context 改變了, 想要達到的 Perception 也改變了, 導致最終提供的 Services 也改變了, 此時 Challenges 也不一樣了. 當然, 達到的效果也完全不同.
覺得比較有意思的, 扣掉自家實驗室的, 大概是這些篇, 因為按照順序看下來, 基本上頁數也是照順序. 在 page 399 之後的覺得有些跟 SE 關係其實較遠了, 有些非常技術性, 就是穩定地建立一個演算法來加強或解決某個具體的問題之類的, 可衍生的想法較少, 就都不記了.
"Implicit" Software Engineering Journals
因為一些投稿的問題, 最近這週花時間把成大電通所的期刊點數清單掃過一次, 除卻清單本身錯誤百出之外, 倒是發現一些看起來不是直接跟 Software Engineering 相關, 但是其 Aim & Scope 有提到 Software Engineering 研究其實也可以投稿的期刊.
一般 Software Engineering 領域比較常見相關的 IEEE TSE, ACM TOSEM, SIGSOFT Soft. Eng. Notes, IEEE Softw., Comm. of ACM, ASE, JSS, IST, SP&E, Journal of Softw. Maintenance and Evolution, Software Quality Journal, Empirical Software Engineering 之外, 間接相關的也有 IEEE ToSC, IEEE TKDE 等等.
然後再扣除一些需要付費的 Journals (每頁付費或是 Free-of-Charge 的頁數過少), 例如 IJSEKE 以及 Intl. Journal of Computer Applications in Technology 之類的, 目前找到的還有以下幾個:
1. Journal of Information Technology (JIT)
因為此期刊我在成大無法取得所有全文瀏覽, 就 Sample Articles 來看, 此期刊偏向 Management 議題(特別是對於人的), 對於一般 Software Engineering Group 來說, 可能適合的主題包含: (1) Software, Middleware, Framework, Software Visualization Designed for Management (2) The Management of Customers, Stakeholders or Development Groups (3) Social Network Analysis in Software Domain
2. International Journal of Computer Applications in Technology (IJCAT)
就 Sample Articles 來看, IJCAT 在 Software Engineering 領域似乎沒有特別的偏好. 包含 Software Process, Design Models, Architecture Design, AOP 等等主題都有. 但是比較特別的是, 在內容上比較沒有看到 Tool Screenshot 形式的實物說明圖. 都是以示意圖, 範例圖或是架構圖居多. 另外也較少看到冗長的數據及驗證分析.
3. The Computer Journal
此期刊收納的 Computer-related 主題相當廣. 在 Software Engineering 領域的文章在 2001~2007 年不多, 但是 2007 年以後變多, 跟 Software Engineering 相關的文章數量占了 2001 ~ 2010 July 的近 80% 的量. 其中類別如上所述, 較少看見 Empirical Study, Quality Evaluation, Stakeholder Management, Requirement Analysis 等等的主題. 但是也或許是因為目前此期刊在 Software Engineering 領域收納的文章還不夠多所致...
4. Advanced in Engineering Software
此期刊著重在工程領域的軟體創新, 但是也有些許論文屬於上述的類別, 講述 OO 在協助解決特定領域的軟體開發問題. 通常 Paper 內會含有重要的分析設計等等... 實驗室若有在對外合作的計畫中, 例如醫療, 智慧家庭或其他具有工程特性的領域, 有利用 OO 進行開發, 可以考慮投稿到此
5. Journal of Research and Practice in Information Technology (formerly Australian Computer Journal)
雖然說在 Aim and Scope 裡也明列了 Software Engineering, 但是事實上自 2005 年之後, 嚴格來說只有 4 篇跟 SE 有直接相關, 且分散在不同的主題. 好消息是對於 SE 的主題沒有偏好, 壞消息是 SE 的直接相關論文實在太少, 況且是在澳洲有自己的 SE Conference 情況之下...
雖然這些 Journals 在一般 Softwar Engineering Community 裡不太會被人提起, 但是從這些期刊原本關注的範圍來看他們各自對 Software Engineering Papers 的偏好以及投稿狀況, 也別有意思. 以上僅限於成大電通所列出點數之部份, 不包含其他學校可能額外列入之 Journals.
To Have More "Replaceable" Distro. is Good
剛剛才看到 Mageia 的消息, 忽然驚覺自己的想法也有些轉變.
在幾年以前, 雖然覺得難度很高, 但是基本上我算是 "統一 Linux 版本" 的隱性支持者. 姑且不論要用什麼方式統一, 例如有單一組織發行標準版, 或是針對 Distro. 架構訂出標準等等. 希望就此解決使用者會感覺混亂, 沒有單一品牌, 不易推廣等等問題.
但是上個月初, 因為一些誤會, 導致剛安裝好的 Mandriva 2010.1 RC 被我砍掉重裝了. 因為還有工作要完成, 沒有辦法等我慢慢釐清問題, 很不安地先備份資料後選擇重裝 Mandriva 2010.1 Stable. 因為我以前使用的習慣不是很好, 導致每次更新或重新安裝新版本, 在回復過去的工作環境上都需要六個小時或以上的時間.
但是這次因為距離上次更換為 Mandriva 2010.1 RC 的時間尚短 (不到幾個月), 大部分資料都只存在 /home 裡面, 額外的 Library 也幾乎都是用 Package Manager 安裝的. 因此在重新安裝之後, 再次透過 Package Manager 勾選所有我需要的 Package, 安裝後會動取用 /home 裡面的 Configurations & Profiles, 在一個小時內我就完成了整個安裝 + 幾乎整個環境回復.
這次的經驗是很好的, 因為我花了很少的時間得到了更新而穩定的系統, 同時我的資料以及各種 Configurations & Profiles 都沒有失去.
這個完全從使用者角度來看的經驗, 或許反映出是否有統一的版本或架構其實並非重點...
生物多樣性 -- 版本多樣性很重要, 但是對於使用者來說, 前提是不會因為版本多樣性而造成額外的負擔, 即便是版本多樣性可以帶來任何 Distro. Makers 所宣稱的好處.
所以什麼 "Domain-Specific", "More Stable", "The Plan of Company"... 一堆理由或許都敵不過 "Replaceable" 的重要性.
滿足 "Replaceable" 使用者就可以自由地轉換 Distro., 哪怕你的團隊就只發行一個版本的 Distro. , 只要他對於轉換提供某種程度以上的保證, 使用者就可以放心的使用, 不用挑什麼 "穩定長久地發展" 等等...
人都是不可靠的, Distro. 發展團隊也是. Mageia 也不能保證 Mandriva 的使用者改用他們的 Distro. 就不會在兩三年後被迫改回用 Mandriva 或是其他的 Distro. 以得到比較新版的整合. 相對來說, 如果 Mageia 可以跟我保證, 在某個時間點, 我可以知道轉移其他 Distro. 的 "Replaceability" 有多少, 會是更有意義的保證.
神速的 Justin.tv 守門員
 剛剛在看 Justin.tv 某台播電影, 邊看邊在找電影資訊, 因為 up 主沒放, 然後聊天室也沒人知道. 不過我認得男主角, 很顯然男主角是年輕時的 Tim Robbins, 而且就拍攝手法跟造型來推測, 應該是 The Shawshank Redemption 之前的作品. 這樣一推測其實就很好找了, 沒點幾下就找到是 Jacob's Ladder
剛剛在看 Justin.tv 某台播電影, 邊看邊在找電影資訊, 因為 up 主沒放, 然後聊天室也沒人知道. 不過我認得男主角, 很顯然男主角是年輕時的 Tim Robbins, 而且就拍攝手法跟造型來推測, 應該是 The Shawshank Redemption 之前的作品. 這樣一推測其實就很好找了, 沒點幾下就找到是 Jacob's Ladder
正想把訊息貼到聊天室的時候, BAN !!
該頻道被 Justin.tv 管理員 ban 掉了...理由應該是因為一分鐘前出現了很短的女性露點畫面 (男主角老婆). Justin.tv 對色情管制還蠻嚴格的.
不過如此神速, 加上該頻道當時人不多, 而且畫面是電影中的合理出現, 讓我不禁懷疑是因為有人檢舉嗎 ? 還是 Justin.tv 本身會對頻道內容有自動檢測的背景程式在運作 ?
就我所知的確 Justin.tv 有監測員以及回報的管道, 但是如此多的頻道, 又只是一閃而過的畫面, 在考量由人管理時, 需要聯繫上管理員以及作 double check 的時間, 怎樣也不可能在一分鐘左右就決定 ban 掉頻道, 效率未免太好...
合理的懷疑是 Justin.tv 有整合截圖跟分析色情畫面的演算法, 作即時的監測. 如果是這樣的話還蠻厲害的...
Picasa 3 Web Connection Failed (Login Failed) on Linux
因為重新安裝了新版的 Mandriva, 自然 Picasa 也要重裝 ... 時間過得很快, 沒想到已經有 Picasa 3 beta 了, 鑑於個人對於 Picasa 2 for Linux 的諸多不滿, 自然想試試看 Picasa 3 ...
結果還是一樣, 到底為什麼 Picasa 要設計成一啟動就不受控制地 Scan 我的所有大大小小資料夾呢 ? 而且介面對於 zh-TW 的支援還是很有問題阿...
正向上傳去澎湖的一些照片的時候, 又遇到 Web Connection Failed 的問題, 訊息大致是像這樣:
Login failed
HttpOpenRequest failed (12157) -
https://www.google.com/accounts/ClientAuth [13]
.........
找了一下 Google, 補上 openssl-devel 的安裝即可解決. 在 Mandriva 2010.1 下的話, 相對就是 libopenssl-devel package
不過感到奇怪的是, 因為原本 openssl 已經有安裝了, 為什麼 Picasa 還是需要 devel package 呢 ? 如果只是需要 libssl.so 的話, 在 openssl/libopenssl package 裡面應該就已經有了.
難不成在進行 Web Connection 時, Picasa 會作某些 Compilation 動作 ?
不過如果仔細去看 /home/user/.google/picasa/3.0/ , 會發現有以下的錯誤訊息:
fixme:wininet:InternetSetOptionW Option INTERNET_OPTION_CONNECT_TIMEOUT (10000): STUB
fixme:wininet:InternetSetOptionW INTERNET_OPTION_SEND/RECEIVE_TIMEOUT 10000
fixme:wininet:InternetSetOptionW INTERNET_OPTION_SEND/RECEIVE_TIMEOUT 10000
err:wininet:NETCON_init trying to use a SSL connection, but couldn't load libssl.so. Expect trouble.
從最後一個訊息看起來是因為找不到 libssl.so , 因此再回頭去看 Mandriva 2010.1 在 libopenssl 以及 libopenssl-devel 裡面的檔案安裝配置, 會發現 :
libopenssl 安裝完只有 /usr/lib/libssl.so.1.0.0
而 libopenssl-devel 安裝完會建立 /usr/lib/libssl.so -> /usr/lib/libssl.so.1.0.0 ( Konsole 配色 XD )
這樣 Picasa 才能夠找到 /usr/lib/libssl.so 而成功進行 Web Connection.
所以... 應該是可以不用安裝 openssl-devel package, 只要自己在 /usr/lib 裡面建立 softlink 到正確的 libssl.so 檔案位置就好... 不過這只是個人猜測, 懶得移除再嘗試一次了 :p
Boot and No Screens Found [Solved ... ?]
Unfortunately... after a weekend power blackout, my Philips 200WB monitor could not display anymore in X system.
The booting message on the monitor displays fine, it just got into "SLEEP" mode when the X starts to running, and nothing shows up thereafter.
Changed the runlevel to 3, and logined in command line to check the log, the kdm.log only says: No Screens Found.
The log message may be correct, but it seems odd to me since I could see all the booting messages before the X starts to run...
If you google the message "No Screens Found" plus the keywords linux, mandriva, startx, or whatever, you might found many speculations and possible solutions, such as the corrupted xorg.conf, inconsistent package upgrading, driver problems...
I had no idea what's going on, but I did make some X system upgrades before the blackout, so I guessed maybe one of the speculations is my problem. Therefore I tried these solutions as people suggested on the web:
1. depmod -a & startx to see if it works
2. XFdrake --experts to re-configure the xorg.conf ( actually this works the same as drakconf on Display configuration )
3. Remove the original xorg.conf, use xorgconfig to generate new xorg.conf
4. Set the device and the monitor to generic options
5. Re-install the X system
6. Re-install the Mandriva ... ( Yes I did that !!! Fortunately I made the system and data partitions a clear cut, so the re-installation is quite easy )
And all of these solutions did not work, my monitor still SLEEPED ZZZzzzzzzz after the X starts to run.
Somehow I started to think : Will it be the problem of the monitor itself ?
So I changed the monitor with another Mozo LCD with D-Sub connection. Hell, my desktop is back ~!!
After a cross check, I finally figured out that the problem is on the DVI+ connection of my original Philips monitor. The connection is a DVI-D single link. The end of the link in the monitor side is not locked, and being a little loose.
I check some DVI information on the web, but I really can not figure out how it works and how this would happen. I guess there might be two causes: (1) because of the loose link, the video adapter can not acquire the correct monitor EDID, or (2) because of the loose link, some video signal (TMDS) can not transmit correctly.
Anyway, after I re-connected the DVI-D link and locked it well, the monitor functions correctly as usual :)
So, if anybody has the same problem as me, maybe you can consider check the DVI link before try any complicated solution :p
Supporting SQL in DBMS
最近因為研究上的需要, 回頭在翻一些基礎的 Database, 猛然發現很多重要的觀念, 當初唸書時都理所當然地輕帶過去, 沒有去深入思考其在軟體設計上的意義.
例如昨天忽然就想到 SQL 在不同 DBMS 上的問題. 當然我知道 SQL/ANSI-SQL 已經算是 RDBMS 領域的標準語言, 但是, 是否各家 RDBMS 需要自己實做對於 SQL 的所有支援, 或是有某幾種 SQL 處理引擎或元件是可以直接被不同的 RDBMS 採用的 ?
修過 Database 基礎課程以及 Database Tuning 課程, 卻沒有想過這個問題...
回頭翻了手上的 Database System Concept 帆船本第四版, 在介紹 SQL 時完全是以使用以及對比前一章的 Data Definition Language 角度來寫, 自然沒有提到 Database Architecture 的事情. 其他地方我也沒翻到, 直到最後面的 Case Studies 在 SQL Server 的部份才略為說到一點 Query Processing 的東西. D. Shasha et al. 的 Database Tuning 則是在第四章一開始, 以及第五章一開始有提到, 特別是 ODBC 的部份, 不過顯然我當初這地方是很直覺地帶過去了 = =
對照網路上找得到的 SQL Server Architecture 參考圖 ( from http://sqlbaba.wordpress.com/ )
再來個 MySQL 5.5 的架構圖
答案我想應該就跟很符合邏輯的猜測一樣, 在效能調校及商業機密考量下, 主要的 Vendors 應該都還是自行實做 SQL 處理的部份.
SE 的研究工作是你想的這樣嗎 ?
今天在意外之中看到了 Mr. Jamie 的這篇 創業不是你想的那樣. 話說我有好一陣子沒有在 follow 這些創投相關的 Blogs 了...
Anyway, 撇開創業一事不論, 從 SE 研究的角度看他列出的這幾點中, 倒是有幾點相當有感觸.
最重要的是堅持, 由很多很多小事情組成, 從最簡單的產品開始, 根本不用去想競爭對手
幾個月前老師找我去談, 直說了我還欠我的學位最後一項東西, 那就是堅持. 對於自己手上工作直到最後有價值產出的堅持. 我們永遠可以有很多的 Ideas, 但是拿幫你拿下學位的是對於其中一兩個 Ideas 所付出的堅持.
從 SEKE 2010 回來之後, 也不斷地在思考 VESTA 為什麼推出去評價兩極, 只得到 Short Paper 的結果, 怎樣的包裝才是對的 ? 最終我得到的答案卻是啟發自一個四年前曾經被 Reject 的 Paper. 如果當初有持續把該 Paper 修改完成, 或許我會早一年發現到正確推出 VESTA 的方式.
眼頭的這個暑假, 是明年初能否有好結果的關鍵期, 不過自七月中回 Lab. 後, 故態復萌地對幾個手上撰寫中的 Journal Papers 三心兩意. 雖然老師早就告誡過我, 先從付出最少 Effort 就可以簡單完成的開始, 似乎我總是沒放在心中...
四年了快邁入第五年 (加上 Master 就不只啦), 回頭看看, SE 的研究工作真的跟我剛進 Lab. 時想像得不一樣, Funny & Creativity 只是研究工作中的一部分罷了...
Notes on SEKE 2010 (二)
Sessions
我三天來其實聽了不少 Sessions, 三天總計參加了 14 個 Sessions, 不過有深刻印象的 Presentations 不多, 或許是因為 SE + KE 其實範圍很大, 但是 Conference 的題目大部分都是比較小而明確的, 除非對兩個領域中的所有主題都很熟, 否則有的很難快速理解, 加以並非每個講者的 Presentation 技巧都很好... 另外 SEKE 的 Presenter 缺席狀況比我預計的要嚴重一些, 也許是因為簽證問題, 幾乎我去聽的每個 Session 都至少有一位 Presenter 缺席.
不過有少數的 Presentation 還是可以學到不少東西. 例如第一天的 Software Engineering with Computational Intelligence and Machine Learning Session 中, Prof. Taghi Khoshgoftaar 的 Presentation 就很精彩. 雖然因為內容牽涉到我不懂的背景知識, 在短時間內很難判斷論文內容貢獻度, 但是 Prof. Taghi Khoshgoftaar 的演講風格極具 "攻擊性", 對於自己的論文內容以及貢獻有極強的自信, 甚至直說整個會議只有他 Group 的 Papers 是真正結合 SE & KE 在做研究的. 是國內會議以及學者演講少見的報告風格. 之前就聽我的指導教授說過, 好的 Conference 中會出現很多 Presentation 是講者跟聽眾之間的 "戰爭", 這算是第一次見識到了 :p , 有機會遇到應該要去聽聽.
我自己第二天是在 Software Maintenance and Evolution Session 進行 Presentation, 內容算是很順利, 在 Session 結束後 Session Chair Dr. Ned Chapin 也給我一些 Presentation 上的建議. 網路上找得到 Dr. Ned Chapin 個人資料不多, 也沒有比較明顯的照片, 本來以為 Dr. Ned Chapin 會是有點頑固的老學究, 但是卻是出乎意料地親切的一位老先生. 我發現 Dr. Ned Chapin 對於像我這種學生進行 Presentation 都會在私下給予建議, 另外他在講者要開始說之前會作簡要介紹, 提醒大家 Paper 在 Proceeding 中的頁面, 最後的提問往往也很切中要處, 是我在這次 SEKE 中遇到主持最好的 Session Chair. 因為 Dr. Ned Chapin 也算是 Software Maintenance 領域 Conference 的常客, 作這方面的國內學者應該有相當機會遇到他.
Dressing
在服裝上, 我發現 SEKE 會議大多數參與者其實沒有傾向穿著整齊的西裝或女性套裝, 就我看到有穿整套西裝/套裝或是類西裝的學者人數大約不到 30% 吧. 許多人都只是穿了襯衫, 也不一定有打領帶. 因此若前往參加而不便攜帶西裝或套裝者, 準備整齊適合辦公場所的服飾應該就可以. 我自己是三天都穿了整齊的西裝啦, 不過也沒有遭受什麼異樣的眼光 XD
第一天的晚宴跟第二天的渡輪晚餐在穿著上大家也是都跟白天差不多, 所以基本上就是放輕鬆穿就好~
Hotel Sofitel and Around
Sofitel 的一般房間價位加上稅是每夜 200 美元出頭, 不過因為他們給 SEKE 的優惠, 所以我大概每夜花了 3000 NTD 左右, 差不多跟台灣同等級的旅館價位相仿. 不過我在台灣也極少住這種價位的 ( 窮學生 = = ).
房間我覺得算是很大, 寢具都很軟且舒服, 住起來相當舒適.
Sofitel 所在的位置比我想的還要偏僻一些, 位在一些軟體公司的附近 (像是 EA, Oracle, Sony Ericsson 等等 ), 可以事先準備 Google Map 列印紙本, 或是跟櫃台要簡易地圖. 基本上我出去玩幾乎都會跟旅館要看看地圖, 有時候旅館自家畫的地圖會很有趣.
Sofitel 有提供地圖, 但不是複雜街道圖, 因為附近道路其實也很單純. 出了旅館, 除非有開車, 否則步行的話主要只有兩個方向可去.
第一個是出旅館後往左邊沿著路一直走, 這時候右手邊是 EA, 沿著路走大約 12 ~ 13 分鐘, 會遇到一個較大的十字路口, 直走過去會遇見一個小的 Market 區域, 有超市跟一些賣吃的, 墨西哥捲, Pizza, Starbucks, 中式餐館, 漢堡潛艇堡店等等.
檢視較大的地圖
最裡面的 Amici's Pizza 店我覺得很好吃, 墨西哥捲那家的 Fish Burrito 也好吃, 中式餐館聽說附近蠻有名的, 不過我沒去嘗試 :p , 價錢都還好, 看你吃什麼, 含軟性飲料大約都在 7 ~ 20 美元一餐. 下面是 Fish Burrito, Pizza 還在等北大的王立杰寄給我, 當時去吃時相機沒電了 :p
第二個方向是出旅館後往右走, 直走到底會遇到 T 字型路口, 過了馬路馬上會看到 Oracle Campus, 相當地漂亮. 之後往左邊走, 有高架橋道路可以遇過 Free Way, 之後再直走會遇到一些吃的店家以及 Cleaners, 包含溫蒂漢堡.
檢視較大的地圖
在溫蒂漢堡路口往右前方看就是 CalTrain 的 Belton Station. 這條路大約 30 ~ 40 分鐘. 另外一個走法是出旅館後直走再右轉, 也是會接到高架道路, 大約可以少走 5 分鐘左右.
Sofitel 鄰近 Redwood Shores Lagoon, 因此早上傍晚都可以直接從旅館吧台附近的玻璃門出去到 Lagoon 走走. 推薦早上六點多帶著熱咖啡穿禦寒衣物沿著 Lagoon 走一小段再走回來, 雖然有點冷但是十分舒服.
CalTrain 系統往北可以接上舊金山 BART 到舊金山市區, 往南可以到 Palo Alto / Stanford, San Antonio, San Jose ...等等, 採用分區計價, 月台上有自動售票機, 上車後才會有列車人員檢查車票, 感覺人力相當精簡. 會議期間利用 CalTrain 到了 RedWood City, San Carlos, Palo Alto / Standford, 以及接上 BART 到 Berkley 逛了逛, 雖然車票比起台灣不算便宜, 但是還蠻方便的. 其他部份屬於旅遊參觀性質, Google 上應該可以找到相當多資料, 就不寫了~
Notes on SEKE 2010 (一)
六月底到 San Francisco 參加 SEKE 2010, 在各方面都學到不少 :)
今年在 Redwood City, San Francisco Bay 的 Hotel Sofitel 舉行, 2006 年後 SEKE 都是在 Boston 跟 Hotel Sofitel 輪流舉辦, 不過下一屆 SEKE 2011 據說會在 Miami Beach 舉辦, 因此 2012 是否會再回 Hotel Sofitel 就不知道了.
把一些會議的東西雜記下來, 順便當作申請國科會補助的報告, 也許往後台灣跟我一樣首次參加的同學們也用得著.

關於會議內容或 Keynote 等等或有疏漏, 如果同樣今年有參加的朋友歡迎協助更正或補齊.
在 Keynote 的部份, 前兩天參加的人數都還算挺多的, 應該都在 60 人以上, 第三天稍微掉了, 但應該還是有 40 人左右. 在三個 Keynote 的內容部份, 其實我覺得並沒有聽到太多新的觀念或思考, 但是有機會看看一些重要人物的風采, 以及底下的教授們怎樣針對內容提問也是有趣.

Keynote I
日的 Keynote I 邀請到 Google 的副總裁 (Vice President of Research and Special Initiatives ) Alfred Spector 進行演講, 講題為 Prodigious Data, Logic, Processing, and Usage.
Alfred Spector 副總裁首先由會議主旨的 Software Engineering & Knowledge Engineering 兩個領域的結合切入到 E-Science 這個主題, 而其所指稱的主要是針對極大量資料的處理, 以及從中獲得知識的科學問題, 特別是在社會現象研究的領域. 過去在科學領域缺乏適當的工具及平台來即時獲得足夠大量的資料進行此類的科學活動. 然而 Google 以高市占率的搜尋引擎, 結合使用者與網路, 並在系統後端保存此龐大的社會資料, 使得此方向的研究充滿可能性. Alfred Spector 副總裁並提到, 如果我們能夠得到真正足夠大量的資料, 我們將有可能直接就資料來解釋某些現象發生的原因, 進而即時做出決策判斷. 人們將可以從系統 (搜尋引擎或是 E-Science 系統) 得到知識, 而得到的知識促使人們產生更多的資料給系統, 系統藉此推論出更多的知識 ( People learn from the System, and the System learns from the Data. )

在這樣的願景下, 其實還有諸多難題需要直接結合 Software Engineering & Knowledge Engineering 兩個領域進行研究. 例如最受關心的隱私權問題 ( Privacy Issue ), 目前尚缺乏真正具影響力的研究成果. 另外極大的系統規模必然會使得一些關於規模的議題更加重要, 例如目前 iPhone 上有超過 22000 項應用軟體可以選擇, 其中最少也會有一項軟體在實際運作時, 產生對於資料的安全性問題. 而在系統內, 透過各種方法所搜集的大量資料, 又要如何被重新用來預測可行的決策, 回答各種可能的問題等等, 都有待進一步的研究.
Keynote II
次日的 keynote Speech 由 IBM 聖荷西 Almaden 研究中心的副總裁 Josephine Cheng 針對建立更聰明的世界 ( Smarter World ) 與各大學的合作為主體作演講. Josephine Cheng 副總裁主要透過 IBM 目前在世界各地所進行的各種計畫以及其成效為主題, 以計畫帶動演講內容. 比較令人訝異的是, IBM 的各項計畫並非以電腦系統為主體, 而是以各種社會面向為出發, 從 Socio-Technical System 的角度在經營計畫, 並從中找出可以利用電腦系統來輔助計畫進行的方式. 因此從 Josephine Cheng 副總裁的介紹之中, 其實內容涵蓋了許多看似跟電腦系統無關, 或是跟綠能環境無關的計畫主題. 但若深入細想, 會發現 IBM 在此議題上的主張其實並不是一味地要求節省能源, 而是在進行各項先端的未來研究, 或是大型社會計畫的過程中, 儘量做到節省能源.

在 Josephine Cheng 副總裁的演講中列舉了以下幾項計畫:
- IBM 正與許多國家的政府合作, 在推動以 RFID 系統標記農產品, 藉此掌控所有農產品從生產後到運輸及倉儲系統, 直到銷售為止的過程. IBM 的願景是希望透過這樣的系統可以減少運輸及倉儲階層的剝削, 同時讓農產品的生產過程更加透明化.
- 在認知科學運算 ( Cognitive Computing ) 以及腦神經模擬科學的部分. IBM 目前已經在簡單動物的腦模擬上取得相當成果. 問題是當這樣的醫療計畫需要進展到更複雜的動物腦模擬時, 需要極大量的電腦主機以及 CPU 同時進行模擬, 此時會形成相當巨大的腦模擬系統. 這樣的系統在耗能上對於研究人員以及社會資源會是相當大的負擔. 因此在持續此研究的方向同時, 必須要兼顧到怎樣可以製作較為節省能源, 同時又適用於腦模擬科學的 CPU 以及系統, 就是一個重要的問題. 同樣的問題也會發生在未來可能的資料中心 ( Data Center ) 或是雲端系統 ( Cloud System ).
- 在水資源的利用方面, IBM 也意識到許多產業事實上在產品製作過程中消耗大量的水資源. 因此 IBM 也在協助建立更加節省水資源的製作系統, 以及強化在製作過程中的水資源重用 ( Reuse )
- 另外 IBM 也與 Stanford University 合作, 在塑膠保特瓶的回收流程上進行改進. 基本精神是: 改變遊戲規則. 換句話說, 他們所研發的新流程跳脫往常的回收及集體重製思考模式, 而是嘗試把瓶子分解為可直接重新組裝的基本元件, 進而加速重製流程, 降低過程中的化學流程使用, 降低水使用量以及污染量, 同時也可以降低成本.

Daniel E. Cook 教授在演講中主要整理出三個主要的挑戰點:
The challenges and difficulties in finding emergent behaviors and potential faults in parallel computing hardware, such as race condition. 程式語言及編寫環境是否可以協助發覺異常行為以及可能因硬體運作因素而產生的潛在威脅
The difficulties of testing design. 第一點同時也導致軟體開發者會面臨如何設計好的軟體測試策略以及測試方案 ( Test Cases )
Code understanding problem of the parallel code will restrict programmers in writing code parallelly. 針對多核環境所編寫的程式碼可能會相當不利於程式碼理解 ( Code Understanding ) 以及檢討 ( Code Review ), 此點同時也會影響軟體開發者撰寫多核程式的意願
Application Issues of QR Train Ticket
Technology news in Taiwan today :一張車票教你逛巿集
且先別說 QR Code 本身已經是相當 Well-known 的技術, 將之運用於車票上來推廣或便利觀光基本上只是重新實做的問題 (甚至連重新實做都談不上, 如果直接跟日本買技術或是討用部份 OSS 的資源來改的話...)
看了新聞內容直覺遠東的這想法在實用上會有很大的障礙.新聞內容提到 :
方便旅客迅速找到想要的資訊,出門不必再帶地圖或導覽手冊。比賽時評審特地要我們實際上網試試,同學鄭大為說,3G手機上網很夯,但依流量計價動輒得花數十元、上百元,好玩卻很傷荷包,但QR Code直接連到指定的網頁,一次只花2~3元,省很多!
這樣問題就來了. 有別於在日本是各店家自己在海報上, 或是宣傳單上印上可以連到自家網頁或是 Coupon 的 QR Code, 印在車票上對於所有店家來說具有單一性以及排他性, 更白話地說, 請問車票上該如何決定要印上那一家的 QR Code ? 或是哪家網站的 QR Code ? 總不能把這問題交給廣告費多寡來決定吧 ?
如果說要由交通局統一製作一個可信賴的導覽網站, 則又面臨該網站的製作及更新維護費用, 同時瀏覽該往站未必可以達成節省流向以及網路花費的問題, 因為要看的資訊量還是變多了.
而在車票上同時印出多個 QR Code, 一來車票本身沒有這麼大的空間, 二來這也跟新聞內容提到可以節省瀏覽的時間以及花費又相抵觸了.
這樣想來, 在應用上似乎有著重重障礙要克服...
2010 開放原始碼創新應用開發大賽
今天收到 2010 開放原始碼創新應用開發大賽的訊息通知,今年還蠻想參加看看的.
不過網頁中對於參賽作品的定位其實有很大的問題, 到底比賽目的是要促進國內自由軟體社群的 "量" 還是 "質" 呢 ?
常說自由軟體, 但實質上包含了 Free/Libre/Open Source Software (也就是一般說的 FLOSS), 這之間的意涵是不一樣的. 從競賽主軸以及對於作品的規定, 完全看不出來主辦單位對於參賽作品有明確的定位.
到底是希望可以在台灣 FLOSS 社群激發更多 "Free Applications", 或是創造更多有潛力的 "Open Source Software" 呢 ? 這兩個目標所需要的評量要件應該要有很大的差異性.
前者應該著重在對於使用市場的分析, 介面設計, 作品穩定度, 甚至是利用 Immature Releases 來評估團隊的市場預估以及經營能力. 要作就應該做出大受歡迎的 Free Applications, 而不是持續讓 "絕大部分的 Free Software 都很難用也沒什用" 這樣的印象繼續擴大.
後者的評量其實應該著重在作品架構設計 (Software Architecture Design) 上, 以及社群角色遷移程序 (Community Role Immigration Process) 的設計上. 完成度跟穩定度反而比重可以降低. 因為後者的重點在於 "讓社群中有興趣的成員可以很容易加入開發", 而不是要求把產品做的很完美.
從去年的獲獎來看這比賽似乎是很偏向前者.
而即便是 "應用" 也有小眾與大眾之分, 主辦單位跟評審們會一視同仁嗎 ?
Learn-By-Study versus Learn-By-Programming
剛剛有大一的學生到實驗室問計概助教一個教科書上的問題.該學生對於書上寫了:
要注意 Escape Character 的使用... 例如 "\1234" 會被視為 "\123" 與 "4" (懶得去抄英文原文, 直接用中文寫)
感到很奇怪, 不懂是什麼意思, 為什麼不是 "\1" 與 "234" ?
我覺得會注意到這個問題代表該位學生很認真地在看書, 想我自己剛學 Programming 時根本也沒注意過這個問題. 但是我覺得該位學生的提問方式, 其實曝露出了她在唸書時的習慣, 很可能是延續唸一般科目的方式, 只在書本上思考跟學習.
事實上, 在她已經會基本的 C Programming 情況下, 一個簡單的程式可以為這個問題帶來解答的線索.
這個簡單的程式在一般的系統中應該會給出 S4 的列印結果. 再多試一下改成這樣 :
會給出 T4 的列印結果.
從這兩個簡單的程式, "\1234" 會被視為 "\123" 與 "4" 是一個學生自己就可以驗證的事實, 因此真正的好問題應該是,
"\123" 是什麼 ? 為什麼系統會認得它 ? 為什麼會印出 S ? 為什麼它不在我學過的 "\n", "\t" 等等特殊字元裡面 ?
從而該位學生或許有辦法根據以上修改過的問題, 進一步分辨 Control Characters 以及 Printing Characters, 以及更深入了解 ASCII Code Table, 最終得到 "\123" 會被印出 S 是因為 123 是 S 在 ASCII 中的 Octal Representation 之猜測.
當然, 不能期待剛接觸 C Programming 幾個月的學生可以獨立得到最後的結論, 但至少在看書之外, 動手去找尋原因, 嘗試, 猜測以修正問題, 對於 Programming Learning 是很重要的.
Knotify4 Crashes Mandriva Sound System
又是 Mandriva 2010.1 RC 上的問題. 在我的系統一段時間沒操作之後, Knotify4 會開始不斷地運作, 大約佔據 6% 的 CPU, 每隔兩秒出現提醒音效, 然後完全阻斷整個音效系統, 連帶 Audacious 或是 AmaroK 會當掉. 即便重新開啟 Audacious, 也是會在播放時, 每隔一秒強迫重放該首 (應該是因為 Sound System 被佔據, 更準確地說是使用 ALSA 系統會這樣)
查了一些討論, 似乎 MDV 2009 版本開始就有類似的問題, 有回報修好, 但是在後續的 KDE 4 版本還是有人遇到同樣的問題.
找到唯一明顯有效的解法是放棄系統提醒音效...
作法是 (在繁體中文版) 桌面設定 -> 外觀與感覺 -> 通知 -> 系統通知 -> 播放器設定, 請改為 "沒有音效輸出"
不過這樣的解決方案有點討厭就是了, 需要系統通知的使用者就要犧牲了 = =
Firefox 3.6 很慢的問題...
剛換了 Mandriva 2010.1 RC 不久, KDE 4 雖然很漂亮 (之前是 MDK 2008, KDE 3.5), 但比較討厭的是 Kwin 在我現在的機器上效能表現不佳, 不知道是否與顯示卡有關, 還沒有時間深究. 另外一點是內建的 Firefox 3.6.3 在開啟頁面以及切換頁面時, 超 級 慢 ~~
今天早上終於受不了, Google 了幾個頁面, 沒想到一下子就找到解決方案啦 :)
問題點在於 Firefox 的 network.dns.disableIPv6 這個設定, 根據 mozillaZine 上的說明, 這個設定在 MacOS X 上是 default True, 而在其他的系統上是 default False. 換句話說, 在我的系統上是預設會去作 IPv6 的 DNS Lookup.
但是這行為在台灣是無意義的, 因為目前台灣的 ISP 大多未更新到 IPv6 的系統 (或是讓 IPv6 與 IPv4 相容), 因此把這個選項設為 False 只會讓效能變慢而已.
在 Firefox 的網址列輸入 about:config 後, 找到 network.dns.disableIPv6 把它改為 True, 開啟頁面以及切換頁面就正常了 :)
International Computer Symposium 2010 上線
International Computer Symposium 2010 悄悄上線了 (其實是我消息不靈通 XD), 沒想到今年是在成大舉辦, 雖然應該是不會投稿, 不過實驗室學弟有上就不用跑遠了.

雖然 NCS/ICS 很多實驗室都不太願意投, 不過怎麼說 NCS/ICS 也是台灣 CS 領域唯一資源最多的會議, 如果台灣想要擁有至少有點小名氣的自家國際會議, 在不去搶既有會議主辦權的情況下, 個人認為從 ICS 改造是最快的辦法.
所以基本上我覺得 ICS 好好辦還是挺重要的... 就看主掌的教授們怎麼想了.
不過目前的 Chairs 名單未免失衡地太嚴重, 感覺區域性太強. 扣掉掛名的教育部名單跟榮譽主席等等, 8 位 Chairs 全部都是成大的, 而 Workshop Chairs/Co-Charis, 共有 21 位左右, 其中成大佔了 5 位, 國外學者 4 位, 其他除了海洋大學 1 位之外, 全部都是南部的學校... 北部台清交中央全部絕緣... 這是怎樣 ?
筆記: AIO 觸控生活應用程式競賽
由經濟部工業局主辦, 工研院執行的 AIO 觸控生活應用程式競賽 告一段落, DBSE 實驗室的 SIMPLE Touch 最終是獲得第三名 (複賽共 19 隊晉級, 取第一名一隊, 第二名兩隊, 第三名三隊). 雖然頒獎典禮結束後的隔天有不少平面媒體報導, 但是受限於篇幅以及作品賣點問題, 只有 B+ 的蒼蠅王2 得到比較多的說明吧, 網路影片也多集中於各家廠商及經理的說話...
週末趁整理相關投影片分享給實驗室的機會, 把一些有看到的東西, 以參加者的角度也紀錄一下, 其中也包含一些自己的看法. 以下的影片是 SIMPLE Touch 的隊員趁四下無人亂動的, 所以很多操作其實不到位, 加減看就好 XD
1. 蒼蠅王2 (B+ Studio 作品)
蒼蠅王2 是 B+ Studio 先前作品 蒼蠅王 Lord of Flies 的二代作. 第一代的作品在先前的微軟 Windows7 多點觸控程式設計大賽就拿下過第一名, 這次再得到首獎, 真是相當厲害.蒼蠅王2 的遊戲概念很簡單, 把自己的手當作蒼蠅拍來拍死蒼蠅 (不過是用手指, 用手掌可能 AIO 電腦會先垮), 以兩人競爭或過關的方式進行遊戲.作品的 Context 設定清楚, 完成度也極高, 美工很漂亮, 以我看到的參賽作品來說, 是兼具高吸引力以及高完成度的作品, 拿下首獎相當合理.
B+ Studio 目前的主要領導者是陳承佑先生, 也兼任 RD (事實上就我所知目前只有一位 RD), 工作室含美工及經理等等目前共只有 4 位人員. 另外值得一提的是決賽時第一次遇到陳承佑先生, 在準備室相當專心地一次又一次, 不厭其煩地反覆準備面試講稿, 相當認真的人 :) 因為我就沒辦法作到這樣, 特別有感觸~
另外強力推薦蒼蠅王的開發手冊, 當初決賽之前, 調查競爭對手時就很喜歡他們的手冊, 可以讓別人很容易理解蒼蠅王的創作脈絡, 是很好的展示及宣傳材料.
2. Digifish Dolphia (琦景科技)
琦景科技在決賽時所用的作品名稱是琦景科技數位魚, 很容易讓人聯想到先前流行的數位桌面水族館之類的東西, 不過現場看到其實不是那麼像玩具的東西.
Digifish Dolphia 是利用高強度的 3DVR 引擎為核心, 繪畫出全 3D 的動物生態 (參賽 Demo 是用海豚以及海底世界為主), 搭配 Multi-Touch 技術讓使用者利用手指動作, 例如轉換視角, 驅趕魚群, 呼叫海豚, 對海豚搔癢等等.
從琦景科技的展出內容來看, 其實我會有點懷疑琦景參賽的主要目的是得到曝光跟商談合作的機會, 特別是前三名可以獲得今年 ComputeX 參展的機會. 所以 Digifish Dolphia 比較像是琦景目前的技術結合 Multi-Touch 之後的一種技術展示, 而不是以一個完整使用情境的方式作包裝.
不過因為前兩名的展出場地在演講廳內, 跟第三名的場地分開, 加上琦景的參展人員看起來是經理級以上的業界前輩, 整場就我看到時幾乎都是跟商業人仕洽談, 完全沒機會講到話, 只有一開始跟陳恆大哥來看了一下我們的 Demo, 也就無從問起~
3. Kidd Touch Fun - 3D Blocks Learning Game (智品科技)
智品科技的網站需要安裝 Silverlight 才能看到, 不過我的 Mandriva 要看到比較麻煩...況且我也不太想裝...
智品的 3D Blocks Learning Game 主要概念就是虛擬化的積木系統, 把積木的物理特性 (主要是重心的移動與積木的堆疊) 設定在虛擬的積木上, 讓小朋友們利用 Multi-Touch 去移動或丟擲積木, 積木於是會與現實世界中的真實積木有一樣的行為. 我記得 Lego 幾年前好像有類似的計畫,但是後來決定還是先朝實體積木的電子化發展, 相關資料找不太到了.
相似的概念在前兩年 IEEE Software 有一篇 paper, 討論把玩具汽車的物理行為嵌入到虛擬玩具汽車中, 例如只要放到斜坡上就會自動下滑, 平地上就不會之類的.
# 2010-08-31 補充: 示範影片在 Youtube 上面有:
# 2010-10-09 補充, 另外一個形式的作品
智品的參展人員我從頭到尾都沒有認到 = = , 因為不是去聽演講就是同樣在展出時間, 完全沒機會講到話. 不過稍微玩了一下覺得積木的動作有點不太自然, 可能是為了迎合小孩子的反應跟操作, 所以刻意把積木的移動跟旋轉速度等等都調整的相當慢.
以上是前兩名的作品.
4. All Touch (AHC)
All Touch 的概念主要是嘗試協助傳統 Keyboard/Mouse 應用程式, 在無須更動或修改 User Interface 的情況下, 直接轉換到 Mutli-Touch 的環境. 可想而知 All Touch 就是一個 Adapter 的概念.
但是 All Touch 的解決方案事實上需要面對許多問題, 例如為了迎合所宣稱的 "任何應用程式", All Touch 本身就需要應付可能會相當複雜的操控方式, 而為了方便 All Touch 的使用者, All Touch 的使用者介面如何作到操作方便, 甚至提供編輯器. 再者, 傳統 Keyboard/Mouse 應用程式會想要過渡到 Multi-Touch 環境這件事, 可能是一個過於危險的假設. 到目前為止, 我還沒有看到大量的聲音認為 Multi-Touch 會取代 Keyboard/Mouse 的操作模式. 換句話說, 極有可能這兩種操作模式本身就是有著不同的使用市場, 這時其實傳統的應用程式未必會需要支援 Multi-Touch, 而要轉移的應用程式也未必會想省功夫而不重新設計 User Interface -- 畢竟為了省下 UI 成本而讓使用者操作不便絕對不是一個好決策.
All Touch 沒影片~ 因為拍攝時剛好陳恆大哥不在, 雖然看過一次但是還是沒法複製操作, 只好殘唸只放立牌照片.
代表 AHC Technology 參賽的陳恆大哥 (其實是大叔吧 XD) 是個超級活潑的人, 先前待在資策會, 也聽到一點小內幕, 是在會場跟我們講最多話的人之一, 感謝陳大哥讓我們稍微不緊張一點 :)
5. Smart eVision (聯銓資訊)
聯銓資訊長期來都專注在研發企業決策軟體, 據 VP 說, 已經投入 18 年了. 沒錯, 他們家副總有來 XD
產品本身的資訊在公司網站上就很很清楚了, 沒什麼好多說, 而此次參賽的版本主要是利用 Silverlight 開發介面, 搭配幾種操控的 Multi-Touch 指令, 使得介面的轉換可以在企業主進行 Presentation 時更加方便. 嚴格來說跟 Multi-Touch 的重要相關性不大就是了.
在展出前期跟聯銓的展出人員沒有說到太多話, 只有介紹跟 Demo SIMPLE Touch 給他們看而已. 不過後半的演講時間, 副總似乎跟我們一樣對演講內容沒什麼太大興趣, 在外面溜達, 有機會聊了一下, 特別是聯銓一路來的辛苦, 以及副總對於 Cloud Computing 被台灣企業接受的可能性分析, 收穫良多 :) 沒想到台灣跟美國的情況會差距這麼大
聯銓近來正式在美國設立據點, 總裁本身在美國督軍中, 預祝拓展順利~
其他
以上是除了 SIMPLE Touch 以外的前三名. 其他通過第二階段的隊伍中, 因為決賽時間錯開, 沒有太多機會看到. 有看到的是台大電機的 Electrical Automatic Handicraft, 基本上應該是電子陶藝模擬, 搭配 Multu-Touch 去作形塑的作品, 沒記錯的話應該是獲得佳作. 另外朝陽科技大學的阿公阿媽戰起來, 好像需要用到除了 Mutli-Touch AIO 以外的 Wireless AP, 不過很遺憾沒有機會詳細了解內容, 只是決賽時剛好是我們上一組, 感覺評審室裡面很熱鬧, 有演短劇的感覺 XD
第一次參賽對於很多事情的拿捏都不太有經驗, 包含進度掌控, 比賽進行的重點, 作品展示方法等等, 幸好有老師的指點, 以及先前 Cox 學長幫忙打下 SIMPLE Touch 的基礎, SIMPLE Touch 隊員, DBSE 以及 DCL 同仁的合作, 拿下第三名. 雖然不夠完美, 但總是個開始. 雖然很遺憾因為種種原因要放棄 ComputeX 2010 的展出機會, 但是相對來說其他的機會也正找上門來, SIMPLE Touch 還有很長很需要謹慎的路要走.
最後還是感謝工研院的執行人員, 退出 ComputeX 的展出勢必給你們帶來不小的麻煩, 希望工研院以及其他隊伍展出順利 :)
最後補一張頒獎人及得獎隊伍代表的合照, 左一我記得是智品代表 (記錯請見諒), 左二是 SIMPLE Touch 辛苦的首席解說員倩瑋, 左三是陳恆大哥, 左四是聯銓副總, 右四是琦景代表 (記錯請見諒), 身上有大大的 B+ 的自然是首獎代表陳承佑先生啦 ~ 早知道 SIMPLE Touch 也穿實驗室的紫衣去... 不過可能太搶眼就是了 XD 長官與各廠商經理課長等等請恕我忽略 ~
OpenFoundry Attack (三) Downloads versus Lifespan
延續 OpenFoundry Attack (二) , 把 Project Downloads 與 Project Lifespan 來比對看看.
Project Lifespan 指的是一個 Project 自創造出來到目前為止 ( 2010-04-20 ) 的時間, 在此以天數 (Days) 作為計量單位.
由於在 OpenFoundry 中, Downloads 數量有顯著量級差距, 因此全部一起看反而看不出甚麼. 以下分為幾個不同的 Scales 來看.
首先是 Downloads 在 0 ~ 100 之間的 Projects. 在此不包含 Downloads 為 0 的 Projects, 在圖上會佔據 Y = 0 的軸線, 意義不大.
較明顯的是 Lifespan 在一年半到兩年之間的 Projects 比較集中一點, 這跟 OpenFoundry Attack (一) 中提到 2008 年 10 月前後的大量註冊 Projects 自然有相關. 但是從 Downloads 的角度來看, 其實並沒有特別的傾向, 算是還蠻平均的. 而從其他 Lifespan 的角度來看, 其實在 Downloads 的表現上也是很平均, 並沒有說 Lifespan 長的 Projects ( 也就是比較老的 Projects ) 就比較容易有高的 Downloads 數量.
事實上同樣的情況放到其他 Scales 也是類似.
底下是 Downloads 在 0 ~ 500 之間的 Projects 分佈. 請忽略左下角那團, 那在上圖中已經說明過了. 其他部份也是均勻分佈.
Downloads 在 0 ~ 1000 之間的 Projects 分佈.
Downloads 在 0 ~ 5000 之間的 Projects 分佈.
Downloads 在 0 ~ 10000 之間的 Projects 分佈.
Downloads 在 10000 以上的 Projects 數量相對少很多, 代表性低就不看了. 基本上結論是, 在 OpenFoundry 上, 目前看來 Lifespan 跟 Downloads 的關聯性並不高.