
幾個有趣的 Authentication & Authorization 機制
這幾天在做一些 Survey 時, 看到幾個有趣的 Authentication & Authorization 機制.
* Some images/pictures bellow are extracted from the papers. Please let me know if there is any legel right violation.
1. Graphical Password
P. Dunphy, A. P. Heiner, and N. Asokan, “A Closer Look at Recognition-based Graphical Passwords on Mobile Devices,” Proceedings of the 6th Symposium on Usable Privacy and Security, July 2010.
這篇 Paper 提到了事實上 PIN 機制備使用率偏低的情況 (畢竟忘記密碼而不能想打電話就打很麻煩, 要處理更麻煩), 同時就算有設密碼, 也可能是很簡單的 0000, 1111 這種 (我就這樣 @@).
作者們提出利用現在手機上的儲存的私人照片, 讓使用者自行選定某張照片, 或是某個 Combination 作為密碼, 取代原本的數字或字母組合. 其中也探討及引用了人對於影像記憶的能力, 怎樣自動選擇容易被記住的影像, 以及私人照片對於旁邊不經意偷看的人不容易記得等等.
不過我覺得這方法還有一些討論的空間, 像是 (1) 私人照片怎樣可以自動避免出現太過侵犯隱私的, 例如只篩選出旅遊照, (2) 影像組的順序本身往往有 Semantic Meaninig, 是否還有利用空間等等.
2. Eye Tracking
A. D. Luca, M. Denzel, and H. Hussmann, “Look Into My Eyes! Can You Guess My Password?,” Proceedings of the 5th Symposium on Usable Privacy and Security, July 2009.
這篇是整合 Eye Tracking 技術到 Authentication & Authorization 中, 利用你的眼睛注視定點的移動順序, 作為 Password 來通過 Authentication. 主要的優點是, 許多側錄或是旁邊偷看的攻擊方式幾乎就都行不通了.![]()
雖然有趣, 但是實際應用上還有很長的路要走, 要有相當的軟硬體支援才行, 無形中也限制可應用的情境.
3. Changed Context
V. Hourdin, J. Y. Tigli, S. Lavirotte, G. Rey, and M. Riveill, “Context-Sensitive Authorization in Interaction Patterns,” Proceedings of the 6th International Conference on Mobile Technology, Application Systems, Sept. 2009.
此篇利用 Observing Interaction Behaviors 作為 Contextual Information, 來判斷已經過了 Authentication 的使用者, 是否在 Valid Session 中, 被 (偷) 換成其他的真實使用者. 換句話說, 是作為輔助性的機制, 去避免使用者因為任何情況被置換了...比如說忘記 logout 之類的.
不過我覺得這篇 Paper 裡沒有舉出比較具體應用的例子是比較可惜的地方. 因為這方法不一定在任何 Cases 下都會很好用, 因此哪些類型的系統適合, 就變成很重要的資訊.
4. Mode Switch based on Context
J. Seifert, A. D. Luca, B. Conradi, and H. Hussmann, “TreasurePhone: Context-Sensitive User Data Protection on Mobile Phones,” Proceedings of the 8th International Conference on Pervasive Computing, pp. 130–137, May 2010.
現在的高階手機通常可安裝相當多的應用程式, 自然也有相當多的 Data 儲存在裡面. 有不同的 Data 種類, 包含工作, 理財, 家庭, 朋友等等... TreasurePhone 的概念是, 不同的 Data 應該要只允許在相對應的情境下可以被取用. 譬如說工作相關的 Data 就應該只有在工作的情境下可以被取用, 這樣就可以避免被家人或是朋友看到.
作者們把該取用情境稱為 Sphere, 而 TreasurePhone 即根據目前的 Sphere 來決定應該設定為哪種工作模式.
5. Distorted Pictures
E. Hayashi, N. Christin, R. Dhamija, and A. Perrig, “Use Your Illusion: Secure Authentication Usable Anywhere,” Proceedings of the 5th Symposium on Usable Privacy and Security, July 2008.
這篇也很有趣, 應該要跟 P. Dunphy et al. 那篇一起聯想. Authentication by Distorted Pictures 的概念其實就是: "熟悉的人不需要獲得全部的資訊就可以拼湊出正確的資訊". 舉例來說, "pasword" 雖然少了一個 s, 但是看的人直覺就知道是 "password".
所以可以進一步確保, 只有知道原本該照片的 Semantic Meaning 的使用者可以準確答出. Paper 裡面也有討論到在 Distorted 後, 可能產生 Sementic Meaning 混淆的情況, 像是黑白外殼的電池跟熊貓.
6. Musical Password
M. Gibson, K. Renaud, K. Renaud, and C. Maple, “Musipass: Authenticating Me Softly with “My” Song,” Proceedings of the New Security Paradigms Workshop, pp. 85–100, Sept. 2009.
列出這篇單純是覺得有趣. 作者們想要用 Music 取代以字母跟數字為主的密碼. 進行 Authentication 時, 是透過輸入一組旋律的方式來進行驗證.
不過我個人是認為, Musical Password 示好想法, 但是依照這個方向跟設定是錯的. 因為缺點太多. 雖然有些缺點在 Paper 內有想利用一些方式解決, 例如 Training, 但是比起傳統的 PIN 跟 Image-based 方法實在沒有太多優勢, 作者自己也在 Paper 裡面承認這點.
7. Context Sensor Data
A. Nosseir, R. Connor, C. Revie, and S. Terzis, “Question-Based Authentication Using Context Data,” Proceedings of the 4th Nordic Conference on Human-Computer Interaction, pp. 429–432, Oct. 2006.
這篇跟我 Master Thesis 有關, 但是當時真沒想到還有這樣的應用 @@
這篇的作者們利用一般人生活環境中可能有的 Context Sensors, 所回報的 Data, 自動產生 Quesitons, 用來作 Authentication 使用. 比如說, 你今天幾點離開的家門, 幾點泡的咖啡, 泡了幾人份等等... 不是很親密且持續觀察你行為的其他人, 很難正確地做出回答.
不過呢, 我認為這個系統有個致命的缺點... 一旦攻擊者知道你在用這個系統, 就完了 = = , 因為答案就在你的生活中...
Pixnet 出包的第七天
從 8/19 晚上 Pixnet 停機更換新架構, 進行資料轉移, 預計 8/20 重新上線, 但因為資料轉移所需時間預估錯誤, 因此僅部份功能可以使用, 直到 8/21 仍舊一片混亂, 管理後台無法正常使用, 文章編輯有問題, 無法進行迴嚮, 部份資料疑似遺失, 使用者的部份草稿文章會被公佈 ( 這點我覺得很嚴重 ), 還有其他一堆問題等等.
iThome 也進行了相關的報導 : Pixnet 改版出包 恐重演無名用戶出走潮 .
Ptt Blog 版發起的回報活動, 可以看到究竟已被發現了多少 Bugs :
雖然說期間每天都有公告說明進度狀況, 但是顯然整個新架構所導致的問題百出.
- [公告] 8/20 目前站上狀況報告
- [公告] 8/21 目前網站狀況報告
- [公告] 8/22 本日重點修正進度
- [公告] 8/23 目前網站狀況報告
- [公告] 8/24 網站現況說明
- [公告] 8/25 重點事項說明與修正進度報告
- [公告] 8/26 網站狀況說明
不是要幸災樂禍, 不過這真是一個好的 Case Study, 真希望有機會可以知道整個內部的來龍去脈. 從這個 Case 可以想到的幾個延伸問題 :
- 除了 Testing 的問題以外, 是否 Pixnet 工程師也沒有考慮過會出問題的可能, 新系統沒有任何 Backward Compatibility 考量, 導致現在不是 Pixnet 不想回復舊版, 而是根本回不去 ? Online Software/Service 的 Backward Compatibility 有哪些東西要考量 ?
- 個人資料被 BSP 或 Web Applications 綁架的議題, 在無名及 Pixnet 相繼出問題之後, 是否會浮上檯面呢 ?
- 提供服務的 BSP 或 Web Applications 背後的工程師素質顯然也相當重要, 但是一般使用者基本上不會去注意這點--直到出大問題之前, 這種情況是否會有所改變 ? 如何評估 BSP 的安全可信度 ( Security Reliability ) ?
- 我們會有定期的防空演習, 是否提供服務的軟體公司應該進行類似的演習 ? ( 可能是由內部的 QA 小組製造狀況, 或是有專門的外部公司介入, 就跟 CMMI 驗證一樣, 這跟單純的 Software V&V 不同 )
Will CloudAV, the AntiVirus Cloud Works ?
( 修改一下發表時間以及Title 進行實驗 )
根據 Computer World 的一篇報導 : Researchers look to cloud computing to fight malware, 密西根大學的幾位學者 ( Jon Oberheide, Evan Cooke, and Farnam Jahanian ) 嘗試利用不同的 AntiVirus Softwares 利用 Cloud Computing 概念結合來防範 malware, 所打著的算盤當然是截長補短, 讓 virus 或是 malware 需要克服更多的難關. 這跟趨勢最近在講的 Cloud Computing 應用 ( 前幾期的財訊在訪問趨勢某人時有提到比較多, 不過內容同樣不甚具體 ), 應該是不同的方向.
這項計畫稱為 CloudAV ( 應該是 Cloud AntiVirus 之意吧 ? ), 相關網站在這, 同時有電子論文可以抓取. ( 以下圖片均取用自 [1] ) 基本上可疑的 File 會傳送到 ClondAV 所提供的 Network Service 作檢驗, 這跟早期的網路掃毒類似.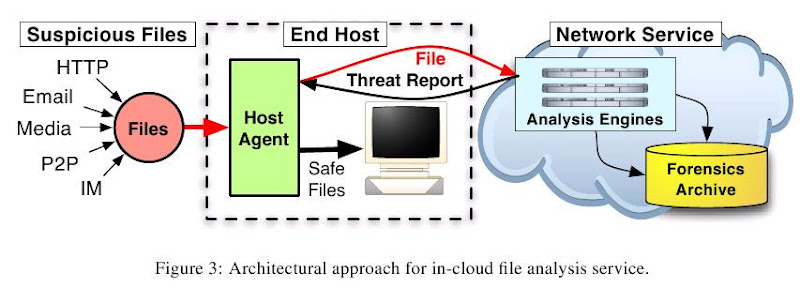 看起來最終的決定是採用類似 Voting 的機制, 透過許多 AntiVirus 的結果, 決定是否該 File 是有問題的.
看起來最終的決定是採用類似 Voting 的機制, 透過許多 AntiVirus 的結果, 決定是否該 File 是有問題的. 我在去年修 Embedded Middleware 作 Final Project 時有提過類似但不相同的想法 ( 我要集合的不是 AntiVirus Softwares ), 最終是卡在系統本身的 Security 問題, 以及 Privacy 問題. 針對 Privacy 問題, 在 [1] 中 Section 3.1 花了一小段說明, 但是也不算正面回答, 只是透過把 CloudAV 的應用環境作限制, 來降低 Privacy 的影響.
我在去年修 Embedded Middleware 作 Final Project 時有提過類似但不相同的想法 ( 我要集合的不是 AntiVirus Softwares ), 最終是卡在系統本身的 Security 問題, 以及 Privacy 問題. 針對 Privacy 問題, 在 [1] 中 Section 3.1 花了一小段說明, 但是也不算正面回答, 只是透過把 CloudAV 的應用環境作限制, 來降低 Privacy 的影響.
除了 Privacy 之外, 對於 CloudAV 是否能成功, 我還有另一個商業上的疑慮, 雖然 Paper [1] 內有談論了實驗本身所使用的 Software 的 License 問題, 但是在商業應用上不知道是否防毒軟體大廠會同意這樣的使用方式, 或是願意加入這樣的服務團體. 這裡就牽涉到商業利益的問題, 也可能給防毒效益不好的公司帶來更大的壓力.
不過, 往好的方面想, CloudAV 可以克服以往我們幾乎無法在一套系統內裝設兩套防毒軟體的效能問題, 以及 Mobile Device 不方便把資源用來跑 AntiVirus Software 的問題, 同時又能帶來更好更可靠的服務, 只要防毒軟體大廠願意進行類似的合作, 那麼就良性競爭以及防毒技術的進步來說應該是正面的. 這樣的 AntiVirus Cloud 似乎也跟我之前認為 Cloud Computing 會帶來軟體產業的二次分工相關.
References
[1] Jon Oberheide, Evan Cooke, and Farnam Jahanian, "CloudAV: N-Version Antivirus in the Network Cloud," Proc. of the 17th USENIX Security Symposium, July 2008
FileZilla 對密碼採用明碼紀錄 !?
在嘗試修改 FileZilla 的一些 Configuration 時意外發現, FileZilla 在紀錄最近一次的連線時, 居然是採用明碼來紀錄 Password = =
FileZilla 為了方便重新連線到剛剛斷線的 FTP Server, 或是快速進行常用的連線, 會把最近一次的連線資料紀錄在 $HOME/.filezilla/filezilla.xml 的最後面, 在 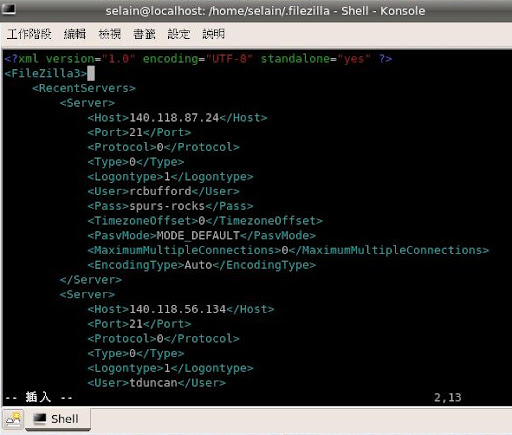 對於 FileZilla 使用來說當然問題不大, 因為只要你能夠用該帳號啟動 FileZilla, 就能夠透過 FileZilla 進行前幾次的快速連線, 看不看的到密碼差別不大. 但是以使用者的角度來說, 因為 filezilla.xml 以及 recentservers.xml 這兩個檔案都是一般閱讀權限, 因此只要使用該帳號執行的程式都有相當的機會去讀取這兩個檔案, 這時候用明碼跟編碼差別就很大了.
對於 FileZilla 使用來說當然問題不大, 因為只要你能夠用該帳號啟動 FileZilla, 就能夠透過 FileZilla 進行前幾次的快速連線, 看不看的到密碼差別不大. 但是以使用者的角度來說, 因為 filezilla.xml 以及 recentservers.xml 這兩個檔案都是一般閱讀權限, 因此只要使用該帳號執行的程式都有相當的機會去讀取這兩個檔案, 這時候用明碼跟編碼差別就很大了.
不知道 FileZilla 選擇用明碼的理由是甚麼 ? 多想兩秒鐘, 其實你可以編一下碼的.
Emailcash 的獎勵郵件漏洞
(請勿利用本篇文章內容進行任何違法行為)
在 Emailcash 的獎勵郵件中, 通常會在廣告最後附上一個連結位址, 透過 Browser 連結到該位址, 就會自動在你的帳號中加入一定數量的獎勵點數, 期間不需要你的帳號登入的動作. 連結位址長的像是這樣 :
http://www.emailcash.com.tw/edmrating/main2.asp?uid=seLain
&aid=2F99D6CA-7A7C-474C-8BE6-8C80DAAD309C
位址中的 uid 參數用來說明要加入點數的帳號, 而 aid 則是辨認該封獎勵郵件的特殊編號.
獎勵郵件編號的產生演算法雖然不清楚, 但是透過偷偷修改編號, 重新送出連結可以得知, 系統是透過編號去確認該封獎勵郵件的存在以及時效.
而進一步偷偷修改 uid ( 修改成其他真實存在的帳號 K ), 不改變 aid, 再重新送出連結要求時, 會發現連結會被判定是有效的, 即便該帳號 K 並非你所有, Emailcash 還是會認定有效, 並且給予該 uid 紀錄帳號獎勵點數.
因此可以得到兩個結論 :
- uid 可以自由變動, 只要你知道哪些 uid 是真實存在的
- aid 隨著不同的獎勵郵件而有不同, 但是同一封獎勵郵件對於不同帳號寄出的實體電子郵件使用同樣的 aid
- 透過有意識地蒐集真實存在的帳號, 可以簡單地建立一個自動看獎勵郵件的系統. 只需要從一個帳號取得 aid, 就可以幫所有的帳號得到獎勵點數, 而不需要真實使用者的介入. 這對於 Emailcash 原本的廣告目的來說是完全違背的. 大量真實帳號的取得有很多種方式, 像是從首頁的每日得獎名單, 從真實的使用者身上蒐集, Emailcash 論壇, 或自己申請等等. 甚至是使用暴力法或辭典法去嘗試所有可能的帳號. 不管何者都會造成 Emailcash 的安全威脅.
- Emailcash 原本可能透過所建立的 User Profiles, 針對不同的族群發送不同的獎勵郵件. 而如果在使用者送出獎勵郵件連結之後, Emailcash 的 Server 端沒有針對該使用者帳號是否為原本應該收到該封廣告信的族群作檢查的話 ( 例如上面的帳號 K 可能原本不該會收到我所收到的這封獎勵郵件 ), 那麼透過修改 uid 重新送出連結, 就會使得非預設廣告族群的帳號獲得額外的利益. 這種情況大量發生的話 Emailcash 官方也會很難處理, 因為此額外利益如果其來源缺乏 Traceability 就很難一一追溯取消, 同時也不容易追究責任, 因為進行此行為的未必是這些獲得利益的帳號擁有者, 就跟上一點說的情形一樣
從 EmailCash 樂透得獎資料回推常規樂透活動人數
今天才發現原來 EmailCash 在首頁左下方會公佈該日的得獎人數以及送出點數.
忽然想到從這個數據去回推實際上在 EmailCash 的樂透活動上, 平均的常規活動人數.
先用一些假設來簡化問題 :
- 假設所有人猜測數字沒有特別的偏好, 因此每個數字的被猜測機會均等
- 忽略有些人可以將五次猜測機會都用在同一個數字上, 假設每個人一次都會猜五個不同的數字 (也就是先不管實際的送出點數)
再來討論點數問題. 在上面的圖中, 公佈的是 85 人中獎, 但是送出的點數卻是 43500 點. 由於一個數字會送出 500 點, 即便 85 人都是不同人, 85 x 500 = 43500 顯然也不是唯一解. 這個需要去細看該日的得獎名單. 如果從人數 85 的連結點進去看, 會發現真正的中獎數字數量是 87 個, 換句話說其中有兩個人一次猜測了重複的數字(或是一個人猜測了三個重複的數字), 因此實際送出的是 87 x 500 = 43500 這就沒錯了. 但從而也知道如果要精準估算, 假設 1. 跟假設 2. 是不實際的, 需要被進一步轉變成變數模型進行計算.
再下去就要假設不同數字的被喜好程度, 以及參與者的猜測模型, 會變得很複雜 = = , 但是基本上是可以算出來的, 有些參數可以透過對於歷史資料的分析取得, 像是該日參與者中會重複猜測同樣數字的比例, 例如今日就是 2/85 = 2.35 %, 甚至可以進一步推算會猜測兩個重複三個不重複的機率, 還有特定 ID 使用者的行為模型 ( 這個就需要更為大量的資料 ).
這樣一來就可以預估像是 EmailCash 這樣的公司, 隨著參與人數成長, 預期該月的樂透支出等等......從某個角度看, 這也算是一種 Information Leaking 吧 ? ( 前提當然是所公佈的資料是可信的摟 )
Context Aware 應用 : 風力發電和鳥類安全
剛剛看到這篇新聞 : 風力發電和鳥類安全, 在報導風力發電引起的鳥類生態問題, 以及一些構想中的解決之道. 風力發電所需要建造的高塔以及風力推動的葉片會改變空中的正常氣流, 影響鳥類的飛行, 尤其對於候鳥的干擾可能造成大量的鳥類死亡意外. 針對這個問題, 其中有個 solution 引起我的注意, 為免新聞連結失效, 節錄內容如下 :
羅賓斯說,較先進的技術也能限制傷害。他說,風力發電機的葉片上可以裝上感應器。羅賓斯說:「如果一隻鳥或者一隻蝙蝠撞上那個葉片,會引起足夠的震動,使得葉片能夠暫時改變角度,避免其他飛鳥撞擊,直到當時的這種緊急情況過去。」改變葉片的角度可以使得風在葉片上的施力降到最小, 從而降低葉片的轉速, 加上固有摩擦力以及煞車系統, 應該可以在意外發生時, 甚至是意外發生之前停下風車運轉.
改變葉片的角度,主要的意思是,讓風從葉片上面吹過,而不是推動葉片旋轉。這樣,飛鳥就不會被吸進去了。基本上,這是風力發電機的制動系統。有些人說,甚 至不需要風力發電機上的感應器。他們說,工程師能夠監視雷達和熱成像設備。這就會告訴他們這個地區有沒有任何候鳥群,如果有,就改變葉片的角度。
不管是頁騙上的振動偵測, 或是利用監視雷達和熱成像設備偵測, 基本上這都是一個 context-aware 的應用, 對於風車發電來說, 無法忽視來自於 context 的影響. 同時這也是 system security 的考量.
有趣的 Tag Cloud 設計與 Information Hiding
今天在 Cool Hunter 看到一個有趣的 Tag Cloud 設計, 在利用同樣 Tag 的文章數量來變化 Tag 大小的功能之外, 這個 Tag Cloud 伴隨著兩個 slide bars, 分別是 Year Slide Bar 以及 Days Slide Bar, 藉由調整這兩個 slide bars 的數值, 可以改變 Tag Cloud 的呈現. Year Slide Bar 用來決定要看哪一段時間之前的文章統計, 而 Days Slide Bar 似乎是決定要有幾天的 contents 被列入 Tag Cloud ( 這裡不是很確定 ). 我覺得這揭示了一個很有趣的點是, 透過部分網頁 visualization, 許多原本無意曝露出來的 information, 是否無意中授予了網頁訪客呢 ?
我覺得這揭示了一個很有趣的點是, 透過部分網頁 visualization, 許多原本無意曝露出來的 information, 是否無意中授予了網頁訪客呢 ?
回頭想想 Tag Cloud 的目的, 其實在於提供一個訪客可以快速了解這個 Blog 內容統計的工具, 可以快速瀏覽整個 Blog 的主要內容傾向, 主要文章類別以及比例, 同時可以直接選取該分類, 在 Tag 及分類眾多時會有較大的幫助, 是一個讓 Blog 變得較為 user-friendly 的功能.
而把 Tag Cloud 變為訪客可以自行調整的模式, 在上述的能力中又做了加強, 同時把 Tag Cloud 由目前時間點的一個網站 Snapshot, 變成接續一個時間軸的眾多 Snapshots, 甚至我們可以從中窺知 Blogger 的興趣之演變, 因而把該 Blog 的更多 information 經由 Tag Cloud 的存取而曝露出來. 但是這對於 Blogger 是好是壞就難說了, 要看 Blogger 是否有意識到此點.
Security and Usability Trade-Off in Embedded System Design : 一個台北捷運系統的小例子
上禮拜到台北參加嵌入式軟體聯盟 (ESW) 成果發表會議, 順便回家幾天, 第一次用新的捷運電子硬幣, 覺得很新奇, 之前都只有用悠遊卡, 很久沒有用自動售票機. 在捷運上無聊, 邊玩著電子硬幣, 邊想東想西, 想到了一個可能的 cheating 方式 :
基本上台北捷運的票 (或是電子硬幣) 在購買時是沒有起點終點的分別的, 換句話說電子硬幣代表的只是一種代用貨幣, 每個電子硬幣有獨特 ID 作為辨識, 但是沒有使用者身份辨識的功能.
於是假設以下的情況 (如下圖), 現在有 A, B, C, D 四站在同一條路線上, A 站到 B 站需要 20 元, A 站到 C 站需要 25 元, 而 D 站到 C 站需要 20 元, D 站到 B 站需要 25 元. 現在有某甲要從 A 站到 C 站, 某乙要從 D 站到 B 站, 他們各自需要花 25 元, 捷運公司總收入為 50 元.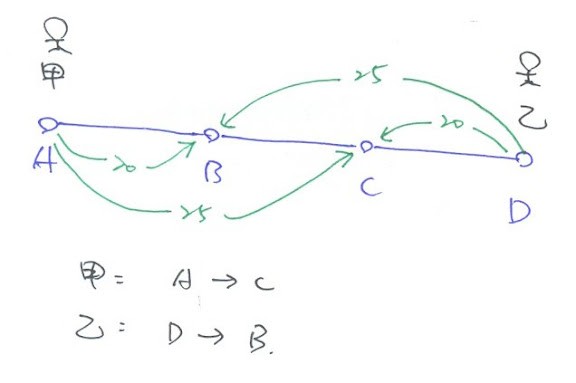 是否他們可以花更少的錢到達他們的目的地呢 ?
是否他們可以花更少的錢到達他們的目的地呢 ?
考慮以下的策略
- 甲在 A 站花 20 元買電子硬幣 EC-01 , 乙在 B 站花 20 元買電子硬幣 EC-02 ( EC-01 以及 EC-02 為電子硬幣 ID )
- 甲坐到 B 站先下車, 乙同樣坐到 B 站下車
- 甲乙交換電子硬幣, 此後甲持有 EC-02, 乙持有 EC-01
- 乙直接在 B 站使用 EC-01 出站
- 甲繼續坐到 C 站使用 EC-02 出站
當然要對付這樣的問題, 台北捷運可以在電子硬幣上加上起點終點站的資訊, 但是這樣一來在自動售票, 以及出入站的補票程序就會複雜許多, 想當然而就會導致 usability 以及 performance 的降低, 對於乘客流動量大的部份大站來說, 這是個無法承受的問題.
因此我想捷運公司當初在規劃時 MRT 系統時, 在這部份應該是假設不會有人為了省這一點錢很麻煩的作這種事, 畢竟要找到兩個人以上作這種配合也不容易, 況且全線價差也不超過 30 元, 在時間計算上怎樣也不划算, 所以就允許此 security threat 存在, 這是在與 usability 以及 performance 權衡下的結果. 當然, 最終還是為了整個系統營運的利益考量, 允許這個 security threat 的存在對於系統利益在台北捷運的 context 下才是最好的選擇.
相對來說, 如果今天不是發生在乘客流動量如此大的地方, 就很可能會採用含有起點終點資訊的電子硬幣. 此時對於 usability 以及 performance 的衝擊就會小許多.
Attacking wretch.cc with DDOS
之前看到 runtime@ptt.cc 發布的連連看服務 ( Wretch Relation Map, 不確定此連結會活多久), 其實跟我之前的 Author Net 是一樣的東西. 其實之前也有想過對無名做這種事情, 只是對我實在沒什用處, 加上還要提供 Server 實在太麻煩了, 如果是我應該會寫 client 端程式, 然後發佈出去. 但是這個要考量的就多了, 例如會不會因此變相形成對於無名的 DDOS 攻擊, 到時候帳算到我頭上就不好了.
不過這樣的 DDOS 攻擊蠻弱的就是了, 只要無名改一下 friends link 的呈現馬上就無效了. 但是他也很難就改成無法直接取得的方式, 否則要不就是 usability 降低, 要不就是 perfomance 降低.
真 好奇像是這種 popular site, 怎樣面對合理服務要求的大量 requests, 即便 request 量幾乎等同於 DDOS attack. 當然利用各種 queue algorithm 是一種解法, 但是對於付費者來說, 要跟一般使用者等待相同的時間嗎 ? 提供 service 的 site 怎樣區別一般使用者跟付費使用者 ( 在可以進行 login 動作之前 ), 有可能在 socket connection 建立時就辨認嗎 ? 利用 cookie 是否可靠 ? 但是 cookie 的使用僅在使用者經常使用固定電腦實際較為有效而已.
什麼樣的 services 應該是 open (例如 friends list 察看), 什麼樣的應該是 protected, 這之間跟 site usability 的 trade-off 又是如何, 真是個有趣的問題.