
Manage Correlated Data Across Services ?
利用不同的 Services 來存放不同的 Data, 然後在一個統一的 Blog 展示是目前 BSP 系統的標準設計模式. 然而 BSP 對於整體 Data 的管理策略可能還有值得討論的地方.
以無名的例子來說, 進行 Blogging 的使用者可能同時利用他的網路相簿跟網路影音服務, 但基本上該兩項服務的 Data 跟 Blog 本身是分開的, 只是在 Blog 上提供可以存取該 Data 的介面. 有時候使用者如果因為特殊原因要暫時關閉該 Blog, 原則上相關的 Data 應該也無法取得才對.
例如無名的 tiger302 這個 Blog, 因為某些理由被使用者關閉, 因此相關的相簿影音等資料也無法取得. 但是如果你從 無名影音 進行搜尋的話, 事實上還是找的到相關的 Index, 只是連結進去後一樣是無法讀取.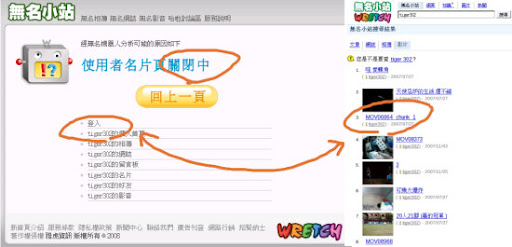
然而, 雖然無法透過尋常的 Blog 或是搜尋介面看到影片資料, 如果有心人在 Blog 開放時留下影片連結的話, 居然是可以直接看到理應被禁止存取的影片 Data, 例如同樣是 tiger302 上傳的這隻影片 :
顯然地, 無名是利用禁止某些 Service 被執行, 來達到禁止 Data 被取得, 但是這樣作就會產生上面的這種漏網之魚 -- 也就是某些公開的 Service 還是可以取得該資料.
同樣的情況在其他的 BSP 上也可能出現, 如果 BSP 沒辦法讓使用者把相關的資料都綁在一起作管理的話, 就可能出現文章被禁止存取了, 圖片跟相關影片卻還是可以被取得的情況. 然而, 以使用者的角度來說, 文章就包含了圖片跟影片, 而非只有文字而已. 因此相關 Data 都應該被禁止存取.
在無名的例子中對於此問題還算好解決, 只要 BSP 願意多花點心思調整一下 Data Model 或是 Access Model, 提供給使用者在發表文章時作選擇即可. 然而當這個問題是跨服務 (Across Services) 時就會複雜許多.
在幾年前的台灣 BBS 也存在類似的問題. 當時全台灣大大小小的 BBS 可能有上千個, 透過 Mailing List 原本的機制, 彼此轉信變成一種風潮. 但是轉信的看板之間卻出現一種問題, 當有使用者錯發文章, 或是不恰當的文章要被刪除時, 只有原本的發信站做了刪除, 其他收信站還需要該站或看板的管理者再做一次判斷. 造成垃圾文章需要花費大量的人力管理刪除. 後來的 BBS 發展出 control.cancel 協定, 只要支援該協定, 可以透過轉信機制自動刪除在發信站已被刪除的垃圾文章.
但這要在不同的 Services 之間, 支援共同的 Protocol 似乎難度大的許多, 況且允許的動作也不是簡單的刪除而已.
Pixnet 出包的第七天
從 8/19 晚上 Pixnet 停機更換新架構, 進行資料轉移, 預計 8/20 重新上線, 但因為資料轉移所需時間預估錯誤, 因此僅部份功能可以使用, 直到 8/21 仍舊一片混亂, 管理後台無法正常使用, 文章編輯有問題, 無法進行迴嚮, 部份資料疑似遺失, 使用者的部份草稿文章會被公佈 ( 這點我覺得很嚴重 ), 還有其他一堆問題等等.
iThome 也進行了相關的報導 : Pixnet 改版出包 恐重演無名用戶出走潮 .
Ptt Blog 版發起的回報活動, 可以看到究竟已被發現了多少 Bugs :
雖然說期間每天都有公告說明進度狀況, 但是顯然整個新架構所導致的問題百出.
- [公告] 8/20 目前站上狀況報告
- [公告] 8/21 目前網站狀況報告
- [公告] 8/22 本日重點修正進度
- [公告] 8/23 目前網站狀況報告
- [公告] 8/24 網站現況說明
- [公告] 8/25 重點事項說明與修正進度報告
- [公告] 8/26 網站狀況說明
不是要幸災樂禍, 不過這真是一個好的 Case Study, 真希望有機會可以知道整個內部的來龍去脈. 從這個 Case 可以想到的幾個延伸問題 :
- 除了 Testing 的問題以外, 是否 Pixnet 工程師也沒有考慮過會出問題的可能, 新系統沒有任何 Backward Compatibility 考量, 導致現在不是 Pixnet 不想回復舊版, 而是根本回不去 ? Online Software/Service 的 Backward Compatibility 有哪些東西要考量 ?
- 個人資料被 BSP 或 Web Applications 綁架的議題, 在無名及 Pixnet 相繼出問題之後, 是否會浮上檯面呢 ?
- 提供服務的 BSP 或 Web Applications 背後的工程師素質顯然也相當重要, 但是一般使用者基本上不會去注意這點--直到出大問題之前, 這種情況是否會有所改變 ? 如何評估 BSP 的安全可信度 ( Security Reliability ) ?
- 我們會有定期的防空演習, 是否提供服務的軟體公司應該進行類似的演習 ? ( 可能是由內部的 QA 小組製造狀況, 或是有專門的外部公司介入, 就跟 CMMI 驗證一樣, 這跟單純的 Software V&V 不同 )
這是誰的問題 ?
前幾天重新在找一些 CloudAV 相關的文章資料時, 意外注意到一個讓我想不透的搜尋結果.
當我之前的文章 Will the AntiVirus Cloud Works ? 寫完後不久(8/10), 如果使用 CloudAV 進行查詢, 是可以在 Google 上找到的, 而且如果只鎖定繁體中文網頁, 基本上相關的網頁不多, 只有四個網頁分布於三個網站.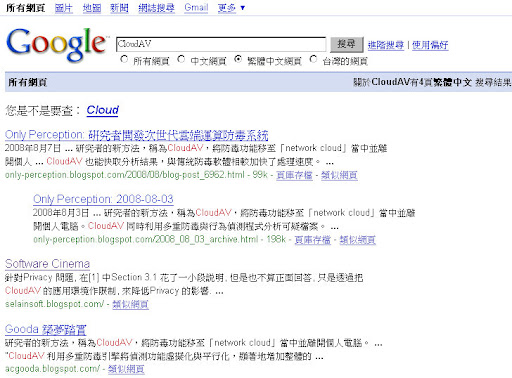
但是就在我再度查詢的那天(約兩天之後, 8/12), 當再次查詢時, Will the AntiVirus Cloud Works ?的文章卻不會在 Google 上出現了.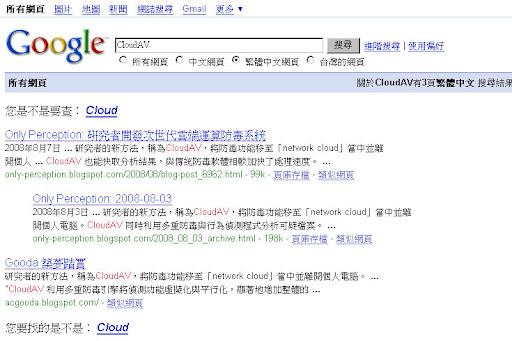
為此我特意把原本的文章發表時間做了修改, 改成比較新的時間(8/12)重新發表一次, 大約過了半小時, 於是文章又重新出現了. 結果就跟第一張圖一樣.
然而在過了一天後的今天(8/13), 文章又從查詢結果裡消失了, 而且這次連另外一個網站也消失了, 只剩下 Only Perception 的網站文章可以被查到.
如果使用 AntiVirus Cloud 作為關鍵字組也會是一樣的情況.
如果說是因為搜尋結果量多, 導致被過濾掉或是排到後幾頁去, 我可以理解文章會從搜尋結果中消失, 或是移到後幾頁去, 但是當搜尋結果極少時 ? 而且是才 post 沒幾天的文章, 也出現了這樣的情況 ?
我真的很好奇為什麼會這樣 @@
Bookmark Mindmap
前幾天在 RWW 上有一篇文章, 介紹了可以幫助 Bookmark Favorite Images 的三個 Sites : 3 Cool Sites to Bookmark Your Favorite Images on the Web. 昨天在看到一篇與 Cloud Computing 相關的文章, 並把他利用回應的方式附加到我之前的文章時, 忽然想到, 往往我們在 Web 上會看到跟之前一些想法相關的資料, 包含文章圖片影像動畫等等 -- 姑且稱為 Web Materials 好了 -- 是否可以有很容易的方法來蒐集組織他們呢 ? 之前用過 Google Notebook, 在蒐集上是很方便, 但是後端的組織就比較弱. 這種類似的系統由於缺乏比較系統化的組織工具, 因此容易出現蒐集了一堆, 後續處理反而麻煩的情況.
之前用過 Google Notebook, 在蒐集上是很方便, 但是後端的組織就比較弱. 這種類似的系統由於缺乏比較系統化的組織工具, 因此容易出現蒐集了一堆, 後續處理反而麻煩的情況.
如果我們把自己的 Blog 視為表達紀錄自己知識的媒介, 那麼其實可以把這種組織的行為以 Blog 文章為中心作連結, 等同於以 "Adding" 的方式連結別人的知識到自己的知識上, 同時這是屬於個人式的知識累積. 很直覺的會想到利用 MindMap 來作整理. 借用 FreeMind 作個假想圖 :
利用 "Bookmark MindMap" 在 Google 做了一下搜尋, 發現有一些類似的 Tools, 例如有人替 Del.icio.us 作了 Delicious Mind Map Maker, 可以吃進你的 Del.icio.us 資料, 製作出 MindMap 來.
另外 DeliciousMind 也同樣是幫助把 Del.icio.us 上的資料以 MindMap 形式作整理與呈現的工具, 他利用了 FeeeMind. ( 這裡有額外的介紹跟 Examples )
不過這些都跟我想要的還是有一段距離. 我認為一張 MindMap 應該是以一篇 Post 為中心, 而往外擴展關係, 然而整個網站未必要是多張獨立的 MindMap, 這樣會讓 Blogger 整理到死. 相對的, 一個 Blog 本身是 Personal Knowledge Web, 而以單一 Post 為中心可以得到一個以上的 MindMaps. 這也跟之前 Library 2.0 的討論有相關之處.
Something about Library 2.0 (1) : Digital Library
Library 2.0 的議題在國內外已經有數年的討論了. 關於命名當然跟 Web 2.0 有關, 但是整體概念的演進早在 Web 2.0 被 Tim O'Reilly 拋出之前.
我現在有在訂閱的幾個 Bloggers 也持續的關注此議題, 不過大多是以圖書館員, 或是圖書館界人士的角度. 正巧我之前跟老師的討論中整理了一些關於 Library 的想法, 是從 Architecture Evolution 的角度整理的, 順手搬到 Blog 上, 從不同的角度看 Library 2.0
跟其他的 XXX 2.0 一樣, Library 2.0 絕對不是獨立的技術跟概念, 而是同一個趨勢在不同領域的展現, 透過搬移其他領域的成功經驗, 以及解決其他領域一樣遇到的問題, 才有可能讓 Library 2.0 的理想獲得成功. ( 當然, 還要主事者不腦殘 = = )
1. The Definition
引用 Wikipedia 上對於 Library 的部分敘述 :
A library is a collection of information, sources, resources and services, organized for use, and maintained by a public body, an institution, or a private individual. In the more traditional sense, it means a collection of books. This collection and services are used by people who choose not to — or cannot afford to — purchase an extensive collection themselves, who need material no individual can reasonably be expected to have, or who require professional assistance with their research.
從這段敘述中可以推想出幾個關於 Library 的特性, 我認為也適用於 Library 2.0 :
- Library 內的東西可以有很多種, 而非只有 book 而已
- Library 內的東西必須經過特定的整理以方便使用
- Library 的 maintainer 可以是單一個人, 一小團體, 一個機構, 甚至是大眾, 並沒有特別限制
- Library 的大小並沒有特別的限制
- Library 的使用者數量也沒有特別的限制
2. The Conventional Solution
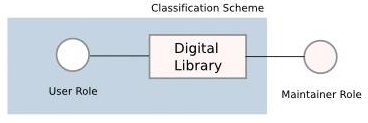
目前常見的 Library 所採取的做法是, 由 Maintainer Role 負責為 Library 內的各種 contents, 例如 books, 事先以特定的分類方式作分類, 然後 User Role 必需去學習這樣的分類方式, 以便有效率地進行搜尋以取得想要的 contents.
在此做法下, Maintainer Role, Library, 以及 User Role 之間的關係像是這樣的 :
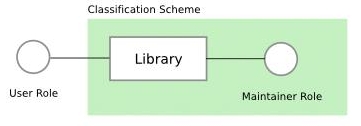
Maintainer Role 除了要負責維持 Library 的 functionality 運作之外, 同時也負責設計及實施 classification scheme, 而 User Role 是在 Maintainer Role 所決定的 Classification Scheme 下所使用 Library.
這樣的 solution 基本上是可以運作並實現 Library 的功能, 但是這樣的 solution 並不夠好 :
在此 solution 底下, User Role 被迫必須接受並使用 Maintainer Role 的觀點, 而難以較有效率且符合自身需要的方式來重新分類 Library 內的 contents
對 Maintainer Role 來說, 也因為此 solution 而限制了他們可以嘗試的 classification scheme. 因為大多數 Users 會希望到各個不同 Library 可以以自己習慣的方式作 contents 找尋的動作, 而不是每到不同的 Library 就需要面對不同的 classification scheme. 因此 Maintainer Role 其實只能被限制在數種主流的 classification scheme 中
我認為之所以會產生這些 imperfect 問題的原因, 其實跟過去基於人力所能負擔的 effort 有限, 以及 Library 是實體的 ( Physical ) 有關, 例如圖書館.
由於過去主要以人力進行管理與維護, 因此如果 classification scheme 不由 Maintainer Role 所掌控, 並強迫 User Role 依照統一的 scheme 使用, 則為了應付不同 Users 的需求, Library Maintainer 必須花費相當巨量的 efforts 來提供服務, 但如此一來 cost 也相對大量增加, 這將與 Library 概念的初衷之一, 減少整體社會接觸知識所需要的 cost, 產生相違背的情況.
3. The Digital Solution
在 Computer 被發明並普及化後, 其實我們應該回頭去思考, 是否可以利用 computer 的 computation power, 重新去改進過去限於人力考量, 所無法圓滿解決的 Library 問題.
利用 computer 的特點在於, (1) computer 具有較為低廉的 computation power, (2) 基於 computer, 許多 Library contents 得以數位化 ( digital ) 的形式存在, 以及被取用. 底下稱呼利用 computer 來解決的做法為 digital solution.
鑑於 application context 的不同, 我認為 digital solution 可以分為下面兩者, 兩者的差別在於 Library 內所管理的 contents 是否具有實體而定.
Semi-Digital Library : 其內的 contents 仍然具有實體, 因此我們不可能使用不固定的 classification scheme 來管理這些 contents, 在實體世界中必然要選擇一種 scheme 來管理這些實體 contents. 但是對於 User Role 在進行搜尋來說, 由於可以把這些實體 contents 以虛擬的物件 ( Virtual Object ) 來表示, 因此在 User Role 端可以保有自己的classification scheme, 透過 computer 進行管理, 不需要花費 Maintainer Role 的 effort. 因此在此 solution 下, Maintainer Role 的責任略小, 只負責實體 contents 的管理, 以及 Semi-Digital Library functionality 的正常運作.

Digital Library : 其內的 contents 完全是 digital contents, 因此完全可以使用 computer 進行儲存以及其他管理. 因此在 classification 部分, Maintainer Role 完全不需要介入, Maintainer Role 將只需要負擔維持 Digital Library 的 functionality 正常運作的責任即可. 而 classification scheme 將完全基於 User Role 運作.
上述的 Semi-Digital Library 以及 Digital Library 兩個 solutions 之共同特點在於, 利用 computer, 將 classification scheme 的調整以及決定, 曝露 ( expose ) 給 User Role. 進而 classification scheme 有機會具備 personalization 的特性. 而回頭去看 conventional solution 中的 imperfect 部分, 將可以藉由此種方式被滿足.
4. Personal Small Library
另外在此想特別針對較小的 Library 討論其應用 digital solution 之後的改變.
在 1999 年日本偶像劇場有一部戲劇叫做 Lipstick, 其內有一句台詞大概是這樣說 :
許多小型的 Libraries 事實上具有特殊的用途, 可能是學者或是作家私人的參考資料庫, 或是一個實驗室共用的圖書研究資料蒐藏, 一個機構的歷史文件彙整等等. 因此裡面所放置的 contents相當程度反映了 Maintainer Role 或是 User Role groups 的相關訊息, 極有可能這些 contents 本身就具有一定的相關度, 而此相關度反映在使用該 Library 的 users 身上. 同時這樣的小型圖書館有一個極大的特點, 在於 User Role 的使用方式以及用途有極高的相似度, 使得嘗試統整所有使用者的 classification scheme, 以及 logic, 來為彼此的搜尋提供幫助, 具有很高的可行性以及實用性.
如果有一個夠小的公共圖書館, 是由一個人單獨維護管理 ( 包含選書以及整理 ), 則透過仔細觀察這個圖書館裡的書, 你將能夠窺視管理者的個人思維.
然而這在 conventional solution 中較難以實現, 理由是各 Users 的使用觀點事實上會隨著時間而有所變動, 進而牽動整個 group 的整體共通觀點改變, 換句話說這樣的改變是動態地, 隨時發生的, 且是藉由許多 Users 的意見交錯協調條而達到一個穩定的狀態 ( Stable Status). 在 conventional solution 中, 這樣的改變較難以達到, 因為這需要所有 Users 定期舉行會議, 討論大家都可以接受的 classification scheme, 相當地耗費時間.
相對來說, 在 digital solution 中顯然就較為容易做到, 藉由 computer 以及 network 的幫助, Users 的使用模式以及使用邏輯 ( Logic ) 可以被紀錄與分析, 進而彼此影響, 達到一個 group 內共享的觀點. 而且此共享的觀點可以隨著 Users 端的改變而動態地調整. 而在此同時, 各 Users 保持有自己的觀點仍舊是可能的.
而由此觀點而言, Semi-Digital Library 以及 Digital Library 使得 Library 不再只是靜態的 content data 的分類存放以及取用場所, 而是轉變為 group 內 users 的意見彙整平台之一, 透過在 Digital Library 內分享觀點, Digital Library 轉變成為引導 group 前進方向的動態角色之一.
5. Public Large Library
Large Public Library 的情況就與 Small Library 的情況不盡相同. 差異在於 Large Public Library 的使用者通常較多且雜, 使用目的也差異較大, 因此利用 digital solution 可以達到的好處應該會比較偏向 personalization 部分. 然而在統計數據的支持下, 或許可以考慮把 Large Public Library 切割成數個 clusters, 然後將每個 cluster 視為 Small Library 來處理. 在此情況下, 需要每個 cluster 有固定的 Users 才可行.
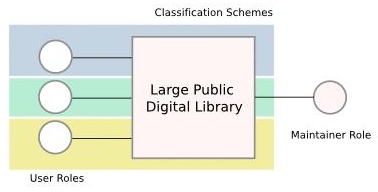
目前在 Web Recommendation System 上已經出現了類似的概念被實現, 例如 Reddit, Mixx 都有讓使用者建立自己的 Community 的能力, 而 Digg 也準備跟進. 當然這只是在 Web 的部份而已.
中央氣象局什時會整合 Google Earth ?
颱風夜寫這篇真是應景阿 ^^
長久以來中央氣象局都只有提供俯瞰的衛星雲圖, 但是 Abstraction Level 太高, 也沒辦法任意變更 Granularity, 說穿了只是往往在颱風來時, 只是看到台灣整個被淹沒而已, 沒辦法調整 Granularity 來看自己居住地區的最近幾小時情況. 雖然也有提供即時影像, 但是一來都是定點, 同時一下子又把視野調到太小, 參考度其實也不高.
我相信中央氣象局手上握有的資料一定比利用衛星雲圖給一般民眾看到的更多, 只是受限於經費以及技術限制, 沒辦法在網頁上提供更先進, 更詳細且好用的 Visualization 介面給訪客.
既然如此, 是否中央氣象局應該考慮採用整合既有的技術, 例如 Google Earth, 作為平台, 附加屬於中央氣象局的有用資訊呢 ?
目前 Google Earth 已經可以讓使用者即時觀察颱風以及颶風等天氣狀態, 並且上面可以看到許多有用的天氣資訊, 如果中央氣象局可以讓資訊部門成立一個小組負責把中文化的資訊整合上去, 我相信只有初期會花比較多心力, 之後就會很輕鬆.
甚至當 Google Earth 的 3D 化成熟之後, 將可以進一步把颱風的面貌用 3D 的圖像顯示, 這樣應該有助於一般民眾對於颱風強度以及危害的認識與警覺性, 而不是僅透過一些聽不懂的數據去了解颱風. ( 以下圖片引用自 Google Earth Community )
 |  |
Travel Plan Digg + SOA Travel Planning
最近要到蘭嶼去玩幾天 (8/1-8/4), 發現行程規劃實在是件有點複雜的事情.
從台灣本島到蘭嶼有搭飛機以及搭船兩種方式. 飛機的話目前只有台東機場有德安航空到蘭嶼的航班, 其他地方沒有.搭船的選擇就比較多了, 台東富岡有, 也可以從屏東後壁.
如果說旅程規劃沒有任何彈性, 事情就簡單許多, 但是選擇也相對變少. 比如說就是要從台北到蘭嶼, 然後日期就是 8/1 到 8/4, 那麼大約只剩下台北搭火車夜車到台東, 一早坐飛機到蘭嶼, 不過這樣的旅程很累 ; 或是 8/1 早上搭火車, 但是這樣到蘭嶼的時間就變成下午了.
而如果旅程規劃有很多彈性, 像是我們的規劃, 可以接受先到台東住一兩天, 然後從容地搭飛機到蘭嶼 ; 甚至可以接受先到台南待一天, 然後從台南搭火車到台東 (大約只要三個半小時), 這樣比台北到台東快上不少, 旅程也比較不會累. 其他像是先到花蓮, 再到台東等等, 都在可以接受的範圍. 這時候再考量旅館, 交通, 食物等等相關事項, 整個規劃作業瞬間就變的很複雜.
在 Web Service 與 SOA 的研究中常見以 Traveling 作為 Service & Workflow 的 Example. 常見以 Time 為根據作行程的銜接, 以及基本的條件設定, 然後加上一些進階條件的選擇, 像是不搭船, 以及 Quality 的要求等等. 這樣 SOA 的 Solution 事實上存在很多複雜度, 除了上面說的以外, 像是 Service 的狀態要能由 Service Provider 更新, 確保 Service Abailability 以及 Quality 等等.
但是若單純以 Bottom-Up 的方式去產生可能的 Workflow, 固然可以得到最多的可能性, 但是畢竟使用者要的通常只有一兩個, 因此中間就需要透過使用者的參與來降低可能的選擇數目, 這又變成了 User Interaction 的問題.
也許因為這樣的複雜度, 許多國內的旅遊服務都只停留在 Information Portal 或是 Service Portal 的階段而已, 而不是真正的 Service Provision Forge.
我認為類似的應用應該考慮利用 Top-Down 以及 User Community 來夾出可能的選擇, 進而大幅降低一般使用者的負擔, 同時確保規劃結果的品質與可行性.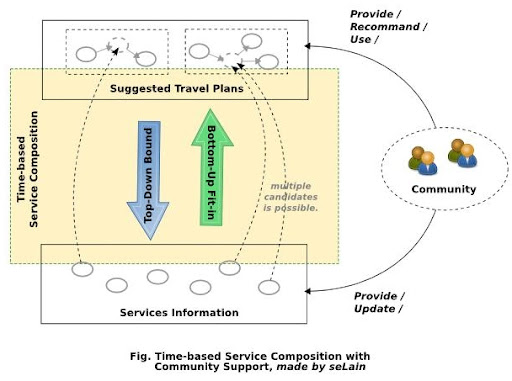
方法就是利用現成的 Travel Plan 作為 Incomplete Workflow 去套可得的 Services. 可以想像一個類似 Digg 的 Travel Plan 推薦子系統, 由一個 Community 維護. Community 成員可以貢獻自己的 Travel Plan, 作為基本的 Template, 而其他成員是以一個 Travel Plan 為單位進行推薦以及參考. 而反過來, Community 也能夠提供 Single Service 的資訊, 有利於一般 Service 資訊的更新與正確性.
當然, 免不了地 User Interface 依舊會是關鍵, 必須要能夠盡量降低使用者輸入以及推薦 Travel Plan 的 Effort, 才能夠在使用者可以得到的幫助與付出之間取得平衡. 另外必須有 Formal Travel Model, 而不是向許多旅遊網站只是讓使用者以 Natural Language + Free Style 分享旅遊心得. 既然要從使用者端取得資訊來再利用, 就應該有系統地蒐集以及使用.
不用把資訊的取得想的太複雜, 也不要期望旅途中相關的商家旅館會時時更新訊息, 單純依靠 Community 的力量來建構這樣的環境, 有效地在資訊進來之前就先篩選, 同時也讓回給使用者的規劃有最高的有效性.
Defining Operational Scalability
Wayne Fenton, Director of Architecture at eBay Inc., 在 JAOO 2007 上給了一個 Talk : Operational Scalability in the Next Generation Web World (連結內有側錄影片 + Slides), 雖然影片長達 48 分鐘, 不過內容其實很簡短, 雖然提到很多次 eBay, 但是其實內容是獨立的, 有認真上 Fault Tolerance 的人應該都很容易聽懂內容, 因為都是基本的概念.
事實上我沒有真的找到對於 Operational Scalability 較為嚴格的定義, 看看幾個從不同網頁 Copy 下來的 :
From SOA Magazine [1] :
Operational scalability is the ability of a service-oriented solution architecture to establish and maintain highly efficient and adaptive, cost effective day-to-day operations as the solution grows and scales with time. It is also represents the ability of the architecture itself to be efficiently re-factored to accommodate change and dynamic business requirements.
From Rajith’s Column [2] :
Operational scalability is a software problem and you need to think about operational concerns right from the beginning. Pay attention to,與 Rajith 類似的說法在 CoverPages 的一篇 Sybase 新聞中也可以看到, 不過搞不太清楚算是甚麼, 比較像是文宣, 就不納入參考.
- Logging metrics, Monitoring.
- Controlling/updating/tuning live apps without disrupting traffic.
Leticia Duboc 的 PhD Work [3][4] 認為 Scalability 基本上不容易也不適合有一個通用的定義, 需要視乎不同的系統以及面對不同的 Stakeholder 而異. 因此他們也建立了一個 Scalability Framework, 在不同的情況下去 Initiate 此 Framework, 定義不同的 Scaling Dimensions, Independent Variable, Dependent Variable, 以及 Evaluation Standard ( Scalability Claim ).
We define scalability as a quality of software systems characterized by the causal impact that scaling aspects of the system environment and design have on certain measured system qualities as these aspects are varied over expected operational ranges.(以下圖片引用自 [4])
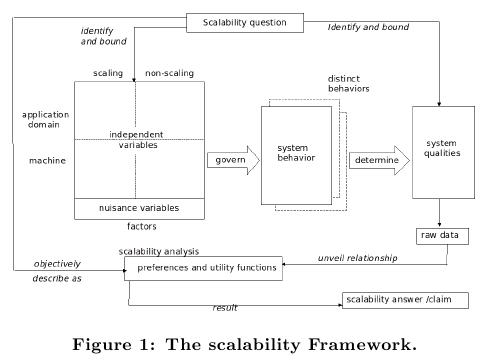
這樣我差不多可以稍稍做出結論. 基本上可以說有 Operational Scalability 這東西, 也可以說沒有. 在 [1][2] 中基本上是在特定的觀點下, 面對特定的 Stakeholder 去定義 Operational Scalability, 而其中 [1] 又更偏向一般性的 Scalability 敘述. 而在 Wayne Fenton 的 Talk 中事實上提到了許多不同的 Stakeholders, 不僅僅是一般的 Customers 而已. 因此他的 Operational Scalability 與其說是以 Stakeholders 作區分, 不如說是以 Operational Reliable Service 為中心思想, 並且放在Community 多變的 Web Service Context 下作說明.
Operational 指的是 Service 本身是必須持續運作的, 你幾乎不能考慮停止這項 Service, 必須隨時 Ready for Use, 概念同於古老的 Non-Stop System 概念. 而 Reliable 指的是 Service 可能會更新 Features, 但是不能夠因為新的 Features 而造成不可逆的改變. 這兩項在新時代的 Web Service 上更顯關鍵. 我們很容易有了想法, 很快的成立網站提供服務, 但是隨之而來的使用者人潮跟對於新功能的需求非常難以預料, 這跟過去 Software 面對的情況有顯著不同, Community 的形成之快是超乎預料的, 但是 Community 的衰落之快也同樣難以預期.
而 Operational Scalability 在此情況下, 我認為其實就是針對 Community Change 的 System Scalability.
References
[1] Ted Barbusinski, "SOA Engineering Focal Points," The SOA Magazine, Issue XIX, June 2008
[2] Rajith Attapattu, "Scaling your system - What I learnt from Dan Pritchett’s (eBay) talk"
[3] Leticia Duboc, David S. Rosenblum, and Tony Wicks, "A Framework for Modelling and Analysis of Software Systems Scalability," Proceedings of the 28th international conference on Software engineering, pp. 949 - 952, 2006 ( Syposium Presentation )
[4] Leticia Duboc, David S. Rosenblum, and Tony Wicks, "A Framework for Characterization and Analysis of Software Systems Scalability," in Proceeding of the The 6th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, ESEC/FSE '07
Beyond Single-Page Web Search Results, and ... What's The Next ? Community Page Ranking ?
本週實驗室會議由學長報告了 [1] 這篇 Paper. 其實之前我旁聽實驗室另外一個 Project 的進度會議時就已經大略看過這篇了, 不過本週趁機重新看一次, 反而有些新的想法 -- 可見得有些 Paper 時不時要多看幾次.
這篇 Paper 的基本概念很簡單, 解決的問題很小 ( 或者該說精準 ) 但很實在.
目前的 Web Search Engine 基本上是以 Single Web Page 作為單位進行關鍵字比對, 然後把符合或部份符合的 Pages 傳回, 通常會依照符合的程度進行排序 (Ranking). 不同的 Search Engine 可能會有額外的 Ranking Factors, 像是 Google 有自己著名的 Page Ranking 演算法, 另外考量商業廣告因素, 關鍵字出現頻率等等, 可以對於排序演算法再做調整.
但不管怎樣作排序跟 Page Ranking, 以 Single Web Page 為單位就會出現, 用了多重關鍵字進行搜尋, 但是沒有任何一個 Page 完全符合關鍵字組的情況. 使用者必須由列出的 Pages 之中, 瀏覽排前面數名的 Pages, 才有可能得到真正想要的資訊. 這大致符合我們的使用經驗.
Paper [1] 的想法則是, 把原本 Single Web Page 的情況, 進步到 Multiple Web Pages -- 既然我們本來就會需要瀏覽多個 Pages 來得到我們想要的東西, 為什麼不在 Search 時就直接給我 Multiple Pages 的比對結果呢 ?
( 下圖修改組合自 [1] 內容的截圖 )
因此 Paper [1] 把 Multiple Pages 結合起來成為一個 Composed Page 作為搜尋結果. 但是 Multiple Pages 也不能亂選, 否則可能造成內容事實上差距很大, 不相干的東西被包裝在一起, 因此考量了 Pages 之間應該會有 Hyperlink 的關係. 同時 Composed Page 內也要避免因為 Pages 太多不好快速瀏覽, 因此針對一個 Page, 也提供了 Query-Specific Summarize 的演算法, 藉由把一個 Page 的文字內容作切段, 以 Query 用的關鍵字組為依據, 利用 Text Information Retrieval 的方法, 以及 LSI 技術, 建立一個 Page Graph, 然後計算出具代表性的部份作為 Summary. 而多個 Pages 在 Summarize 過後進一步把 Summary 結合成為 Composed Page. 詳細的演算法在 [1] 中有說明.
從 User Query 的觀點來說, Paper [1] 注意到越來越多使用者傾向使用關鍵字組作為 Search Context 的 Abstraction, 並期望找到的資訊可以填到 Search Context 中. 而過去 Single Web Page 的作法使得使用者要自己負責彙整 Single Web Pages, 透過 Hyperlink 去找尋 ( Explore ) 更廣的資料, 然後歸納出一個有用的 Page Set 出來. 而此篇 Paper 稍微前進了一步, 在可以幫忙進行事前整理的範圍內, 先把相關的 Pages ( 可能橫跨 Websites ) 做了整理, 同時以 Summarize 過後的內容結合成一個 Composed Page, 來逼近 User 的 Search Context.
從 Single Web Page Ranking 到 Multiple Web Page Ranking ( Summarized, Composed Page ), 下一個階段會是甚麼呢 ?
Community Page Ranking 或許有機會. 不管是 Single Web Page Ranking 或是 Multiple Web Page Ranking, 基本上如果你輸入的是一樣的關鍵字組, 結果應該是一樣的, 換句話說對於所有使用者來說是一視同仁的. 這也是因為我們無法事先預測可能的使用情況 ( Search Context ), 因此只好這樣作. 但是如果可以鎖定一個 Community, 透過 Community Member 就可能定義出屬於該 Community 的可預測 Search Contexts, 這時候要更進一步對於 Pages 作事前組織就是有可能的事情. 同樣的 Pages Set 在 Travel Community 與 Local City Community, 使用同樣的關鍵字組, 可能會是得到不一樣的 Composed Page.
感覺 Google 已經開始透過 Knol 希望逐漸建立可信賴的 Knowledge Group 了, 或許將來與 Community 在 Knowledge Search 方面會有更加深入的互動.
References
[1] R. Varadarajan, V. Hristidis, and Tao Li, "Beyond Single-Page Web Search Results," IEEE Transactions on Knowledge and Data Engineering, vol.20, no.3, pp.411 - 424, March 2008
利用 Twiddla 遠距討論 Design Diagram
Twiddla 是一個免費的電子白板服務, 之前為了跟在美國的學長討論 Paper 上的 Architecture 圖, 其實在 Survey 時有注意到, 但是當時以為只是普通的畫圖用電子白板, 鑑於畫起 Design Diagram 實在太累, 加上動作過快會讓網頁上的 JavaScript 陷入暴走狀態, 把整個 Browser 鎖死, 因此後來沒考慮使用 Twiddla.
今天看到 Library Views 圖書館觀點 的一篇介紹文章, 才發現原來 Twiddla 可以開啟特定的網頁網址, 在上面進行文字或畫圖註解討論. 這樣一來問題就好處理多了, 可以先把要討論的 Design Diagram 放到一個可以取用的 Web Server 下, 然後再利用 Twiddla 去開該檔案的網址, 就可以當作底圖進行討論, 畫註解等等.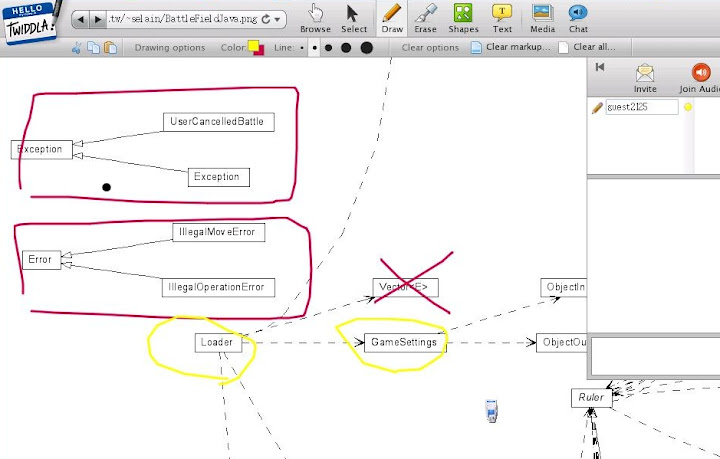
在技術面上, Twiddla 有利用 Scribd 的 iPaper 的服務, 把許多不同的檔案格式轉成 Flash, 因此可能可以直接開啟, 然後在上面討論. 嘗試了幾個不同的常用 File Format, 像是 Python Source Code 會被當作普通的純文字檔轉成 Flash, Block 會亂掉, 沒辦法好好看 Code. 而 PDF File 可以開, 但是非常 lag, 相對來說 OpenOffice 檔案倒是還好.
這樣 Twiddla 加上 SkyPe 以及各種 IM Software, 基本上就可以是窮人版的 Web Meeting Solution 摟 :)
My Activity, My Life Calendar, My Swurl: Operating the Lifestream
跟隨著 RWW 文章 Swurl: Your Lifestream, Made Beautiful 的腳步去試用了Swurl -- another Lifestreaming Service.
基本功能上其實沒有甚麼好說的, 跟 FriendFeed-like 的 Services 雷同, 甚至可以說現階段功能上不如 FriendFeed 來的好. 但是我喜歡他的 Visualization, 雖然概念簡單, 但是很強大.
Swurl 並非像 FriendFeed 一樣只是把蒐集來的資訊依新舊排列, 而是再多提供了一個類似 Calendar 的整理方式, 以時間軸, 只紀錄有活動天數, 形成一個 Life Calendar Matrix. ( 以下借用 RWW 文章的圖, 我的只有文字不太好看 :p )
Visualization 的目的一般是為了把 Invisible Information 變成 Visible.
在 Swurl 的 Life Calendar 上, 提供了一個介於統計式每日每週文章照片數量, 到 Blog 式落落長文章串之間, 折衷的摘要總覽介面. 輔以 Calendar 的 Metaphor, 我們會很自然地把相近日期的事件連結起來, 於是過去一天, 一週, 一月, 一年, 很快地就可以在你的腦海中流逝而過. 在每天每天每週每週 Blog 文章跟照片, 多媒體資料之間, 其實我們都遺漏 / 篩選掉了很多細節, 心情的轉換...... 這些東西我們沒辦法, 也不可能一一記錄下來, 但是透過 Life Calendar, 就像整理舊相簿一樣, 時間可以在手上流過, 本來一點一點的文章照片, 就可以銜接變成一整串記憶之流.
我想 Swurl, 以及他的相似 / 後繼者,會逐漸揭露一個方向 : 把Lifestream 的焦點從紀錄, 開始轉移到操作上. 就像編輯家庭錄影帶, 透過不同的操作, 我們可以再次提供不同的觀點, 不同的交集, 不同的思考, 以及不同的懷念 -- 為什麼我又會想到羅賓威廉斯的迴光報告 ( The Final Cut, 2004 ) 呢 ?
btw, My Swurl : http://selain.swurl.com/
Zero-Day Copy ?
剛剛又看到一個複製網站 說你這行 (ShowUrJob) , 很顯然想法是來自於 Glassdoor.com . 透過 Community Member 的群體力量, 讓許多公司的薪資跟待遇透明化.
在 Software Security 領域有 Zero-Day Attack, 在 Internet Venue 領域也要有 Zero-Day Copy 了嗎 :p
不過我並不是想嘲笑 Zero-Day Copy 的行為, 相反地, 這類網站能獲得成功也相當不錯, 沒有人會嫌可以用的服務太少, 不是嗎 ?
Zero-Day Copy 的可行性我認為與 Localization 關係極大, Glassdoor.com 對於非英語系的國家還沒有那麼大的 Community, 而缺乏 Community 就缺乏資訊. 如果有相似的網站可以快速複製實現類似的功能以及制度, 藉著語言以及文化優勢搶在開拓者 ( 如 Glassdoor.com ) 之前嘗試建立夠大的 Community, 成功的可能性並不低.
在 Zero-Day Copy 中, 最難得到的 Idea 來自於別人, 要搶佔的 Resource 本來就在 Community 中, 而中間快速複製才會是重點. 因此在 Zero-Day Copy Company 中, 最重要的角色可能會是兩種人 : Reverse Engineer 以及 Project Manager. ( 為什麼我會想到 Pay Check 這部電影 :p )
這裡的 Reverse Engineer 包含不只軟體技術上的 Reverse Engineer, 還包含可以從 Social 角度進行 Reverse Engineering, 分析開拓者成功因素跟行為模式的 Reverse Engineer. 換句話說, 需要的是一個 Socio-Technical System Reverse Engineering Team.
Project Manager 就不用說了, 能夠在合理的時間跟成本下領報開發團隊完成 Software Development 的 Manager 是每家軟體公司都想要的人.
也許將來 ( 或是現在就有 ? ) 會出現專門支持 Zero-Day Copy 的創投公司也說不定. 平常就養一堆技術高超的資訊人食客, 在 DEMO 展之類看到有價值的外國網站就馬上進行 Zero-Day Copy 工程, 反正現在軟體服務專利幾乎是沒有辦法申請的狀態. 有這種公司也是蠻有趣的, 跟我有點合得來 :p
Evri, The First Try
昨天 Sign Up, 今天就收到 Invitation 摟 :)
不過目前開放的試用內容其實讓人有點失望. 首先是內容其實跟之前在 Evri Blog 上看到的圖片差不多, 再來是 UI 操作上沒有我想像中的那麼具有 Revolution.
目前有 Most Popular People, Most Popular Places, 以及 Most Popular Things 可以選擇. 但是任何一個項目都還沒有辦法讓你自己指定 Search Keywords. 換句話說我想 Search Evri 是沒辦法的, 只能選擇他 Popular 列表上對象. 這個正式開放後應該會可以進行 Keyword Search, 不然可能一整個月 Popular List 都不會變阿 = =
左邊是 Most Popular 列表, 右邊是最近的 Rising & Falling 列表, 中央是 Evri 所謂的 "Data Graph". 下方則是關於主題的文章列表, 但是決定出現文章順序的演算法未知.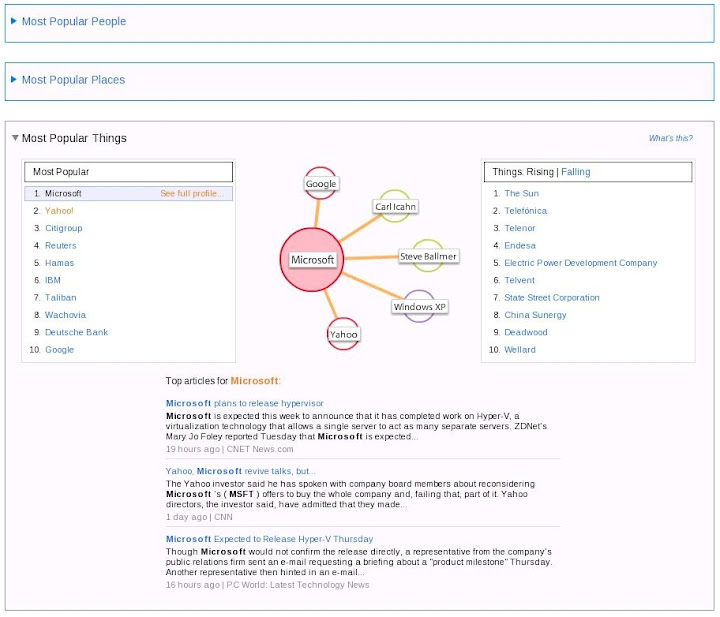 點選主題旁邊的 See Full Profile 可以看到關於主題的更詳細資訊頁面. 左下方的 "What's happening with ... " Section 有點意思, 基本上利用 Keywords 作為 Indexing, 對於相關的 Information 做了樹狀分類, 因此可以快速地選擇關鍵方向瀏覽該方向的 Information.
點選主題旁邊的 See Full Profile 可以看到關於主題的更詳細資訊頁面. 左下方的 "What's happening with ... " Section 有點意思, 基本上利用 Keywords 作為 Indexing, 對於相關的 Information 做了樹狀分類, 因此可以快速地選擇關鍵方向瀏覽該方向的 Information.
右下方則是針對主題所建立的 Profile. 不過 Profile Template 應該需要知道對像是 People, Place, Company 之類的才有辦法建吧, 一般雜亂的 Things 要怎麼建 Profile ? 因為 Evri 給的 Demo 裡面在 Things 部份幾乎都是 Company, 不知道未來這部份會如何處理.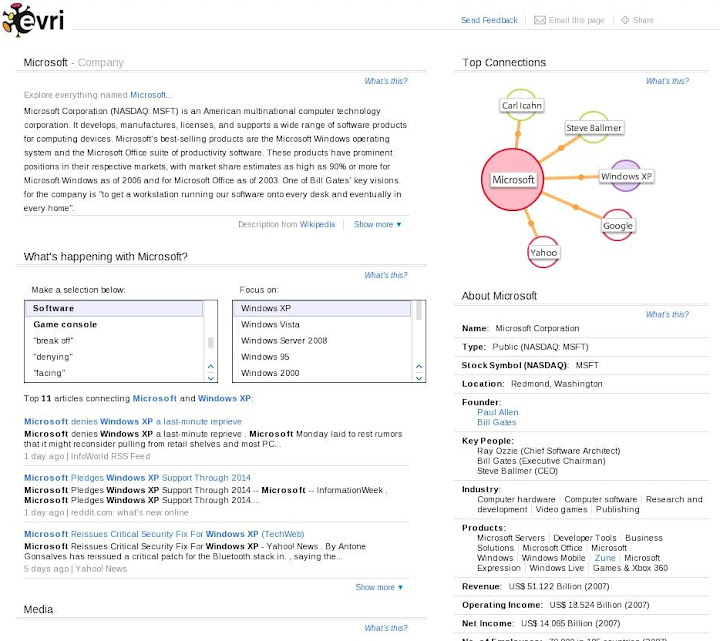
至於所謂的 "Data Graph" 或是上圖的 Top Collection 部份, 實際的作用沒有想像中的大. 基本上就是利用視覺化的方式告訴你哪些其他主題與你目前所觀看的主題相關度最大, 但是並沒有實際的搜尋導引作用, 你無法透過此 Data Graph 來快速切換主題, 而是必須透過左下方的文章內的關鍵字連結來切換主題. 會這樣設計應該也是有理由的. 可能的原因是點選 Data Graph 內的其他連結點是用來更新下面的相關文章到特定個關聯方向, 而不是一下子就切換到其他主題去.
好吧, 我想大概就是這樣了, 我應該沒漏掉什麼東西, 整體來說並沒有太多令人驚艷的設計, 這使得我不是很看好 Evri ="= , 除非正式開放之後出現其他的爆點摟. 以目前 Evri 的能力來說, 我認為 Google 想要的話大概一週 ~ 兩週就可以完成同樣的 Beta 服務網站, 甚至資料量會遠勝 Evri. 因此不管 Evri 是否能打響第一炮, 都很難令人對其前景樂觀, 加上技術難度不高, 要複製很容易, 使得 Evri 想賣個好價錢大概也很困難.
希望 Evri 能讓我看走眼摟 ~ 這樣事情會比較有趣 :)
Evri : Yet Another Semantic Search Engine ?
上個月 Evri -- 號稱是嶄新的 Content-based Search Engine -- 在 6th D Conference 上有了 Demo. ( 以下圖片引用自 D6, evri session photos )
在 RWW 的介紹文章 Evri Beta Launches: Search Less - Understand More 下, Falafulu Fisi 給的回應其實還蠻中肯的 :
{kind=link}
...... there is nothing new here. The technique they used has been around for a long time and it is called, Latent Semantic Indexing (LSI) ...... The only thing that matters in the domain of search if one can show that his/her system has higher recall capability than his/her competitor or similar system out there......
的確以目前可得的資訊看起來, Evri 也是基於對 Content 進行 LSI 或其他 Semantic Web Analysis 來建構整個 Search Topology, 這點從 Evri 的 Hiring 資訊也看得出來. 不過如果我們再更仔細一點去看 Evri 的 Blog ( ㄜ... 雖然文章很少 ), 在 6/24 的 Little Room 文中說道 :
...... And, even with great semantically-aware data, it’s all about the UI. Evri is building a “data graph” that shows interesting and useful connections to explore about things in the outside world-things that aren’t part of your social graph.
我覺得 Evri 光明正大的提到 UI 是件很好的事情 ( 這個 UI 讓我很想試用看看阿 ). 利用 Semantic Web 的 Content-based Search Engine 在這一兩年陸陸續續地出現, 但是有哪個真正吸引了大眾的目光, 有哪個真的足以威脅到 Big Three Search Engine : Google, MS Live Search, Yahoo 的佔有率 ?
以 Business 的角度來說, 或許像 Evri 開始改用 User 的角度來思考, 希望透過更好更易懂的 User Interface 來包裝 Semantic Web 會是一個不錯的嘗試. 不用想要去教會 User 什麼是 Semantic Web, 因為 Semantic Web 本來就存在我們的腦袋跟生活裡, 而是透過 UI Languages, 讓 User 很容易地在 Computer System 上操作 Semantic Web, 補足缺少的資訊區塊.
回頭來看 Evri 的標語 : Search Less, Understand More.

看起來似乎很合理, 不是嗎 ? 我已經 Sign Up 了, Evri 快點公開讓我用用看吧 ~
WikiCafe : Wiki for Video
( 原始報導請參考 ReadWriteWeb 上 Marshall Kirkpatrick 的文章 WikiCafe: MetaCafe Invites Users to Edit Video Metadata )
影音分享網站 MetaCafe 提出了一個有趣的實驗性計畫 : WikiCafe.
顧名思義 MetaCafe 希望把 Wiki System 目前在文字文件的成功模式複製到影像文件上, 不過 WikiCafe 現階段還僅止於把 Vedio Metadata 以及 Commentary 給 Wiki 化, 把 Vedio Tagging 的修改權力從 Vedio 分享者擴張到整個 Community.
首要的考量當然會是 Metadata Quality 的問題, 在 Marshall 的文章中也提到 MetaCafe 的 Community 整體素質比起 YouTube 來的高, 因此計畫成功的可能性也比較高. 不過我懷疑 MetaCafe 的 Community 素質高跟他目前的主要使用者族群有關, 如果 MetaCafe 的使用者族群分佈跟 YouTube 趨近的話, Community 素質是否還能維持就很難說了.
因此管理制度還是很重要的, 即便是 Wikipedia 也免不了面對此問題. 在爭議性高的議題上, 例如中國與台灣主權的問題, Wikipedia 也相當依賴頁面管理者仲裁, 甚至暫停管制該頁面的自由更新. MetaCafe 是否能複製 Wikipedia 的成功, Community 自身的管理制度我想會是成敗關鍵.
而在 Marshall 的文章中也提到另外一個 Versioning 的問題.
純論 Metadata 的 Versioning 問題, 也跟上述的管理制度有關, 同時我想透過 Wiki-like 的方式解決應該沒有甚麼問題. 會有問題的可能是 (1) Vedio 本身的 Versioning 問題, 以及 (2) Vedio 與 Metadata 之間的 Versioning 問題.
Vedio 本身的 Versioning 問題指的是當原作者修改了 Vedio, 甚至是 Community 修改了 Vedio 之後的 Vedio Version Control 問題. MetaCafe 並沒有提到 Vedio 本身被修改的事情, 當誰說不可能呢 ? 我們有 Open Source Software , Open Source Hardware, 還有 Open Disk Spaces (例如 000webhost.com ) , 也許下一個流行的就會是 Open Source Media :p ( 扯遠啦 ~ )
同樣的, Vedio 與 Metadata 之間的 Versioning 問題也來自對於原本 Vedio 所進行的修改. 在 Vedio 經過修改之後, 原本的 Commentary 是否還適用呢 ? 是否所有經過修改的 Vedio 都必須被視為新的 Vedio, 無法跟之前的 Commentary 拉上關係呢 ? 到目前為止好像沒有看到哪家 YouTube-like Website 針對這個問題提供管理服務.
不過解決方法其實已經具雛型了. 在 André Santanche 的 Fluid Web [1] 中其實就說明了類似的模型, 以及對於 Versioning 的解決方案. 如果可以被成功用上的話, 應該可以大幅降低 Versioning 管理的 Cost.
References
[1] A. Santanche and C. B. Medeiros, "A Component Model and Infrastructure for a Fluid Web," IEEE Transactions on Knowledge and Data Engineering, vol. 19, no. 2, pp. 324-341, Feb. 2007
Photo Slideshow Pattern
在看 CNN 新聞的時候, 注意到他的 Photo Slideshow.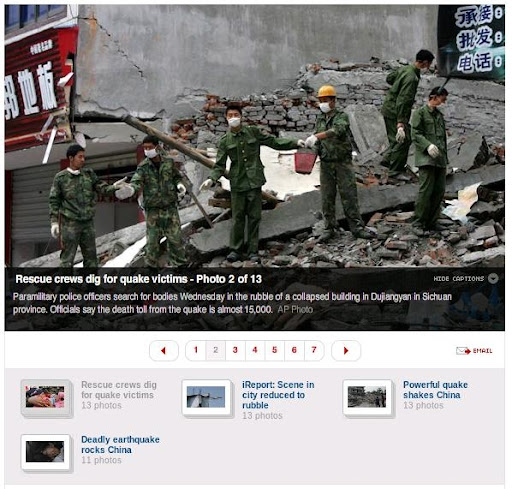
主畫面是選取的照片, 照片下半部是可收起的半透明照片解說, 下面則是 Slide Bar, 最下方則是其他 Group 的照片. 沒什麼特別的地方, 但是隨處 ( Most News Site, Blog, Company Site ... etc ) 可見是否也意味著這已經變成了某種 Web UI Pattern 了 ?
最近想幫系網頁也加上類似的照片集, 同時改變一下版面配置, 目前的公告區佔得太大了, 應該減少文字的比重. 倒是可以參考參考 CNN 的設計.
改變 PHPList 預設語言 (Default Language)
蠻奇怪的, 雖然 PHPList 可以透過頁面上的下拉式選單改變頁面語言, 但是似乎沒有辦法在設定 (Setting) 中直接改變系統預設語言 (Default Language), 必須登入後再透過下拉式選單進行改變. 在 config/config.php 裡面好像也沒有選項可以直接修改.
本來想說, 好吧, 直接把除了中文以外的 Language Module 移除, 只剩下中文讓你選應該可以吧. 結果把 admin/lan/ 裡面的模組都拿掉之後, PHPList 會出錯進不去 = =
雖然沒有實際驗證過, 但是後來去看 admin/languages.php 的內容可以發現, 如果你把 $LANGUAGES array 裡面除了 "zh-tw" 的都註解掉, 也是會出一樣的問題. 這部份我覺得是 PHPList 程式碼沒有寫好, 預設 "en" 英文語系是一定存在的, 因此只要 "en" 被拿掉就會出現錯誤.
因為懶得去 trace languages.php 的內容, 隨便改了裡面程式碼的幾個 "en" 設定改成 "zh-tw" 都不見效果, 乾脆採取暴力法 :p
在 languages.php 的 $LANGUAGES array 宣告後不遠處, 可以看到一個 if {} 正在設定頁面的相關 language 設定, 因此搶在這之前把 $_POST['setlanguage'] 的內容改掉變成 "zh-tw" 即可, 是故加上一行 $_POST['setlanguage'] = 'zh-tw'; 如下 :
這樣一來登入頁面時的預設語言就會自動切換成繁體中文了, 而原本透過下拉式選單切換其他語言的功能當然不受影響.
要改成其他的預設語言也可以利用同樣的方式, 不過缺點就是所有使用者都會被強迫修改就是了. 希望之後 PHPList 可以讓管理者以及一般使用者設定自己習慣的語言環境阿.
Portals : Towards An Application Framework for Interoperability
M. A. Smith 在此篇文章 [1] 中先花了一點篇幅討論 Portal 的定義, 而最終作者所給予 Portal 的定義為 :
An Infrastructure providing secure, customizable, personalizable, integrated access to dynamic content from a variety of sources, in a variety of source formats, wherever it is needed.
基於上述的定義, 作者認為與 Internet OSI Model 其實有相近之處, 故在此篇中是以 Layered Architecture 來建立標題中所述的 Portal Application Framework. 共有七層 Layers, 分為三個 Groups, 分別為 Process Interface Layers ,Resource Discovery Layers, 以及 Network Interface Layers. 下圖有各層的簡要 Description, 更詳細的內容可以看 Paper [1].
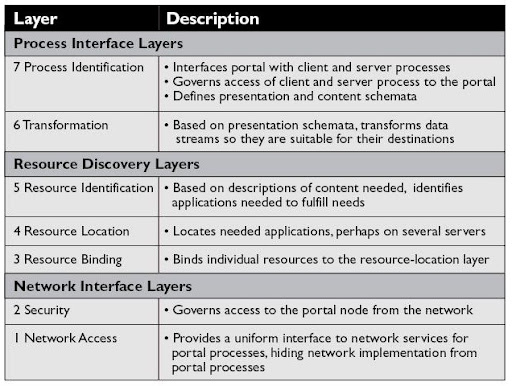
但我認為在文章中, 也許限於篇幅, 並沒有深入討論在此 Layered Architecture 之上, 各 Layers 之間透過由 Layers 建構起來的 Abstraction, 得以直接進行 Communication 的行為. 例如 Resource Identification Layer 如何跟另外一個 Resource Identification Layer 進行溝通. 這應該是 Internet OSI Model最重要的特徵之一. 缺乏此敘述, 將會使得各個 Layers 看起來只像是一個 Functional Blocks, 這樣就跟一般的 Block Diagram 沒什麼兩樣了.
同時在 Layers 與 Layers 之間的 Communication 說明也是缺乏. 另外一個問題是, 基於這樣的 Application Framework 所建立的 Portal, 在進行 Deployment 時會有哪些選擇呢 ? 我們在 Network 上有各式的 Routers 或是 AP, 負責了 OSI Model 中數層的工作, 是否對於 Web Portal 而言, 也是會出現類似的概念呢 ? 也許這些問題要到最近幾年的 Conference Papers 裡去找了吧, Magazine 的文章向來比較難以說到細節.
另外也很值得想像的一點是, 既然把此 Layered Architecture 與 OSI Model 對比, 我們是否也可以很合理地想像, 這會變成 Web OS 對應於 Internet Service/Resource 管理使用的一個 Module 呢 ?
References
[1] M. A. Smith, "Portals : Towards An Application Framework for Interoperability," Communications of the ACM, vol.47, no.10, October, 2004
在 MoinMoin 內加上 Google Aanlytics
查到兩個作法, 第一個是直接把 Analytics Code 嵌入的作法, 底下以新版的 Google Analytics 嵌入碼為例 (注意嵌入程式碼是用前後各三個雙引號包起來), 把嵌入程式碼指定給 page_footer2 這個變數 :
把以上的 code 寫在 wikiconfig.py 內即可. 當然需要重新跑 moin.py
page_footer2 是頁面 Theme 調整可以使用的變數值, 其他可以使用的變數值可以在 HelpOnConfiguration 看到相關的說明.
另外一個作法是直接利用 MoinMoin 內建的 Google Analytics 支援, 這個比較簡單, 只要直接在 wikiconfig,py 中寫下你的 Google Analytics code numbers (連結內請搜尋 Google Analytics, 約在頁面 3/4 的地方) 就好 :
MoinMoin 會接手其他部份的 Google Analytics 程式碼產生. 不過新舊版就要看你的 MoinMoin 版本而定.
MoinMoin 暴力法重設使用者帳號密碼
今天因為實驗室的 MoinMoin 有使用者忘記密碼, 但是透過 MoinMoin 自動寄回 encryption 過後的密碼串雖然可以登入, 但是看不到明碼還是不太方便, 要進行修改密碼時卻發生 exception, 因此想透過管理者權限修改使用者密碼. ( 其實後來發現是該使用者檔案的權限不知為何被設成 -rw-r-----, 一般的使用者權限是 -rw-rw----, 使得該使用者要重設密碼時, MoinMoin 的修改被系統擋了下來, 因此發生 exception. )
不過當時我沒有注意到這個原因, 直覺地想說利用 admin 去改應該很輕鬆, 結果找來找去, 不知道怎樣直接修改使用者密碼, MoinMoin 的使用者裡面只有詳細的說了 ACL 頁面存取設定, 其他使用者帳號的管理似乎沒有提供好用的介面.
一時衝動, 想說那我直接去改使用者 data 好了 XD
結果費了一番功夫, 不過也多知道了 MoinMoin 對於使用者資料方面是怎樣處理. 在 MoinMoin 下, 使用者資量是放在 instance/data/users (instance 要看當時創造 Wiki instance 時採用甚麼命名) 裡面, 透過特定的編碼方式形成以一連數字命名的檔案. 檔案名稱應該跟創造帳號時間有關, 但是詳細計算演算法未知.
而個別使用者得資料, 除了密碼之外, 其實是以明碼的方式, 紀錄在檔案中. 換句話說, 使用 cat 就可以輕鬆看到使用者資料, 而利用 vi 就可以進行編輯. 但是有一點很奇怪的是, 使用 vi 編輯時, 原本已經在檔案中的內容沒有辦法使用 backspace 刪掉, 只能新增內容進去.
另外注意的一點是, 密碼的 SHA 運算似乎跟帳號以及其他因素有關, 因此即便兩個帳號使用同樣的密碼, 得到的 encryption code 是不一樣的. 也因此我本來想把自己的帳號設定成某個 password, 再把 SHA encryption code 複製到密碼有問題的帳號這個想法最終是失敗.
最後採取的作法是, 修改密碼有問題帳號的 mail address ( 因為無法直接修改, 因此先利用 # 註解掉原來的, 然後加上新的一行 ), 讓我可以在自己的電腦上收到問題帳號的目前 encrypted password, 然後利用此 encrypted password 登入, 再進行密碼修改. 之後就是上面說的, 發現其實不能 reset password 是使用者檔案權限的問題, 所以修改權限後就 ok 了.
而修改後, MoinMoin 不是只有更新使用者檔案內的該項 properties 而已, 而是會將整個使用者檔案重寫, 因此前面註解起來的部份會被抹除.
簡單來說我就是繞了一大圈, 解了一些本來只要調整檔案權限就可以解的問題就是了 Orz
不過從機制看起來, MoinMoin 的使用者資料在系統管理內要很小心作權限控制, 一般使用者應該是連進行閱讀都必須被禁止才是.