
OpenFoundry Attack (三) Downloads versus Lifespan
延續 OpenFoundry Attack (二) , 把 Project Downloads 與 Project Lifespan 來比對看看.
Project Lifespan 指的是一個 Project 自創造出來到目前為止 ( 2010-04-20 ) 的時間, 在此以天數 (Days) 作為計量單位.
由於在 OpenFoundry 中, Downloads 數量有顯著量級差距, 因此全部一起看反而看不出甚麼. 以下分為幾個不同的 Scales 來看.
首先是 Downloads 在 0 ~ 100 之間的 Projects. 在此不包含 Downloads 為 0 的 Projects, 在圖上會佔據 Y = 0 的軸線, 意義不大.
較明顯的是 Lifespan 在一年半到兩年之間的 Projects 比較集中一點, 這跟 OpenFoundry Attack (一) 中提到 2008 年 10 月前後的大量註冊 Projects 自然有相關. 但是從 Downloads 的角度來看, 其實並沒有特別的傾向, 算是還蠻平均的. 而從其他 Lifespan 的角度來看, 其實在 Downloads 的表現上也是很平均, 並沒有說 Lifespan 長的 Projects ( 也就是比較老的 Projects ) 就比較容易有高的 Downloads 數量.
事實上同樣的情況放到其他 Scales 也是類似.
底下是 Downloads 在 0 ~ 500 之間的 Projects 分佈. 請忽略左下角那團, 那在上圖中已經說明過了. 其他部份也是均勻分佈.
Downloads 在 0 ~ 1000 之間的 Projects 分佈.
Downloads 在 0 ~ 5000 之間的 Projects 分佈.
Downloads 在 0 ~ 10000 之間的 Projects 分佈.
Downloads 在 10000 以上的 Projects 數量相對少很多, 代表性低就不看了. 基本上結論是, 在 OpenFoundry 上, 目前看來 Lifespan 跟 Downloads 的關聯性並不高.
OpenFoundry Attack (二) Project Downloads
接續前篇 OpenFoundry Attack (一) 的 Data Crawlng 設定, 對於 Project 績效最容易理解的指標 : Downloads 數量作統計, 數據如下表.
其中 Intervals 為下載數量間隔, 第一個 0 為特殊的間隔, 代表下載數量為 0 的計畫數量, 而 的間隔為下載數量大於等於 1 次, 小於 50 次的意思, 其餘的間隔依此類推. 最後一個 50,000,000 ~ 的間隔代表下載數量在五千萬次以上的計畫數量.
| Intervals | Downloads |
| 0 | 695 |
| 1~ 50 | 133 |
| 50 ~ 100 | 60 |
| 100 ~ 500 | 132 |
| 500 ~ 1000 | 48 |
| 1000 ~ 5000 | 69 |
| 5000 ~ 10,000 | 18 |
| 10,000 ~ 50,000 | 23 |
| 50,000 ~ 100,000 | 6 |
| 100,000 ~ 500,000 | 12 |
| 500,000 ~ 1,000,000 | 2 |
| 1,000,000 ~ 5,000,000 | 1 |
| 5,000,000 ~ 10,000,000 | 1 |
| 10,000,000 ~ 50,000,000 | 0 |
| 50,000,000 ~ | 1 |
其中下載次數為 0 的計畫共有 695 個, 佔所有此調查中所查看計畫總數的 57.87 % , 而除此之外, 算是很正常地在 1 ~ 5000 次下載的計畫佔餘下的大多數.
換成長條圖可以比較容易看出比例差距. ( 圖中的 maximum 就是下載數量大於五千萬次 )
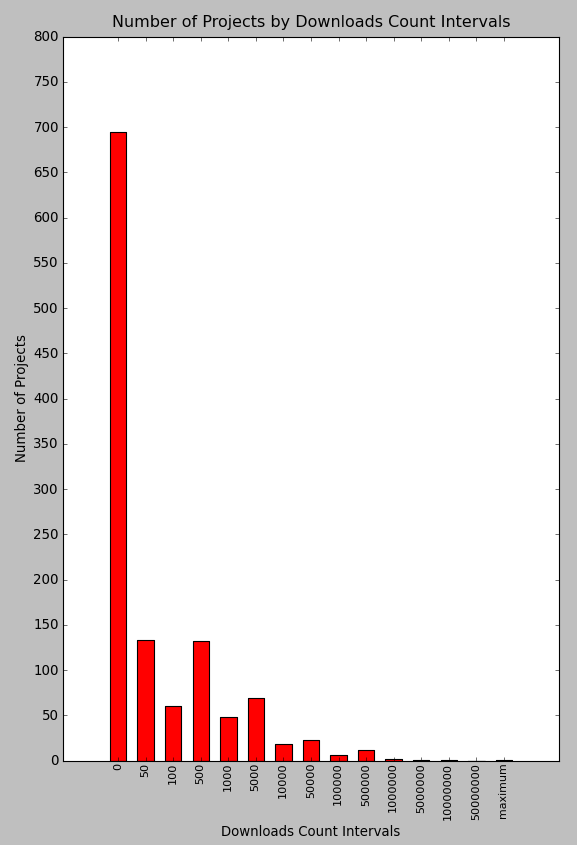
當然對於下此數量在五十萬次以上的少數 Projects 難免讓人好奇, 這些 Projects 分別是 可攜應用程式套件中文化 ( 508,946 次 ), Wow! USB VirusKiller 可攜式儲存設備防毒軟體 ( 734,802 次 ), 新同文堂 ( 1,149,864 次 ), Wow! USB Protector 可攜式儲存設備防毒偵測 ( 8,389,615 次 ), 以及 PCMan 驚人的 104,258,467 次, 這數字即便在 Sourceforge.net 都很驚人. 另外兩個名列前茅的 USB 防毒相關計畫都是中研院同一個研發小組的成果, 所以計畫名稱基本上很類似.
另外隨手附上 Sourceforge.net 在 2006 年左右的圖表, 詳細蒐集日期不太確定, 應該是 9 or 10 月左右. 當時共觀察 58794 個 Projects, 其中下載數量為 0 的有 20751 個 Projects, 約佔 35.29 %

這兩個圖表中, 感覺 Downloads 在 500, 5000, 以及 50000 次似乎有形成三個門檻的趨勢. 不過還需要再觀察, 以及設法跟 Project Lifetime 作交叉比對就是.
OpenFoundry Attack (一) : Project Creation Statistics
因為現在好像沒用 OpenFoundry 的話國科會計畫會比較難過了的樣子, 既然這樣就來研究一下.
不知道系列會寫多長, 也許到終於被禁止 crawling data 為止 ? 系列命名採自 Korea MBC Battle.net Attack -- 其實沒什麼意義, 純粹好玩又想不到要取甚麼.
資料蒐集日 : 2010-04-20
至資料蒐集日為止, OpenFoundry 上共有 1219 個專案, 但是專案編號事實上是從 1 ~ 1470, 換句話說其中有些專案已經因為某些原因被移除了 ( Deactivated ), 被移除的專案共有 241 個左右, 例如編號 14 的專案.
自然資料蒐集就只有針對活動中的 1219 個專案. 而同時由於未知的原因, 我的 Crawling Tool 只能抓下其中 1201 個專案的資料, 不過數量已經相當接近了, 因此餘下的 18 個就當作沒看到 ( 其實是懶得一個一個去找 XD )
把這 1201 個專案依照其 Creation Date ( 以 Month 為單位作收納 ) 來整理, 可以得到下面的分佈長條圖.
很自然地會注意到幾個特別的分佈. 由於 Blogger 的顯示限制, 點選上圖可以看到比較清楚的 X 軸年月份標籤.
其中在 2004 ~ 2006, 以 4 ~ 6 月為中心的 Project Creation 數目明顯比周圍的月份來的高, 2007 年整年相對普通, 而 2008 及 2009 年則是變成 9 ~ 10 月份有相對高檔, 特別是 2008 年 10 月份一舉超過單月 70 個新開設計畫.
基本上一年之中 1 ~ 3 月新計畫的開設量少是可以理解的, 因為剛過完新年, 接近農曆年, 然後馬上又是四月初的春假, 這三個月正好是減溫到加溫中. 不過其他月份在 2008 以及 2009 年的反差實在有點大就是了. 話說這兩年的 10 月究竟有甚麼特別的呢 ?
本來還想做一張 Creation Date 對上 Last File Update 的時間關係, 不過做到一半驚覺 OpenFoundry 有未來檔案的問題. 例如 Simple PHP Blog 正體中文與補強計畫 的最新檔案日期是 2019-11-17, 另外也有 2030 年的, 這樣讓時間可靠性產生很大的問題, 所以還是摸摸鼻子算了.
How Matplotlib and NetworkX Work Together : A Case Study on Figure Instances
最初是因為以下的 Code 讓我對這個問題有興趣. 這段簡單的程式碼 Matplotlib 以及 NetworkX 來合作畫圖. 其中 NetworkX 負責 Graph Model 的建立, 而 Matplotlib 則負責 Figure 繪圖的部份.
最後繪出的圖, 如同程式碼所指定的位置, 畫出三個圓點.
而我覺得程式碼有趣的地方在於, 細看程式碼, matplotlib.pyplot 只有在 line 6, 以及 line 20 被使用, 期間 line 9 到 line 18 都是 networkx 的運作.
而, 在此 Script 中, networkx 跟 matplotlib.pyplot 表面上是沒有任何互動的, 沒有任何 Message Passing 或是 Object Communication 出現. 如果單單依照此 Script 中的 Program Logic 作 Program Slicing, 或許就會被乾脆地切成兩個 Program Slices 了.
不過想當然爾, 既然最後可以順利地畫出圖來, 這兩部份的程式碼肯定在背後有進行某種 Communication, 否則不可能在 networkx 中建好 Graph Model, 在 matplotlib.pyplot 中就知道要畫出甚麼樣的 Figure.
經過漫長的 Code Tracing, 大致上可以把 Dependency Graph 整理如下圖 :
其中比較關鍵的是 Matplotlib 在 Figure Management 上, 允許同時間有數個 Figure Instances 存在, 而目前要畫在哪個 Figure Instance 上, 則視乎目前哪個 Figure 被設定為 Activated.
在 plt.figure() 中 ( 事實上為 matplotlib.pyplot.figure() ), 可以透過參數 num ( 可參考 Online Document, 即 Figure Instance Identity ) 指定要 activate 那一個 Figure Instance, 如果 Instance 不存在, 則會產生一個新的 Instance.
而在綠色的流程中 ( 即程式碼 line 9 到 line 18 ), networkx 在 nx.draw_networkx_nodes 進行中會透過 matplotlib.pylab.gca 取得目前為 Activated 的 Figure Instance 其 ax object ( 座標軸物件 ), 之後透過 ax 把要畫出來的 nodes 加進去.
最後 plt.show() 透過 matplotlib.backend_gtk 把圖畫出來.
這 Matplotlib 中的 Figure Instance 取用機制大體上是為什麼原本的 Code Script 中, 在乍看之下 networkx 跟 matplotlib.pyplot 沒有 Communication, 但是還是可以把圖畫出來的主要原因.
Consultant Community Service
RWW Report : Get Quick Impressions of Your Latest Product Iteration with Concept Feedback
又是一個從一個極端到另外一個極端的權衡.
現在的 Web 環境, 讓我們可以很容易地, 無花費地把任何想法, 計畫, 設計, 產品, 介紹給任何人, 然後收取任何的多元意見. 缺點就是過程可能會極度沒有效率, 也沒有保證性的正面結果, ex. Yahoo Knowledge+
當然, 花錢找顧問公司則是完全相對的作法, 是最有效率, 也可以得到保證性結果的作法. 缺點是顧問費用是一定要給的, 即便結果你不是那麼滿意.
ConceptFeedback 取了個中間的位置, 透過 "仲介" 具備一定水準的 Consultant Community, 來給予付費的顧問服務. 這之間自然就會有許多付費模型可以選擇. ConceptFeedback 是允許使用者選取三個 Best Advices 來給予實質的 Money Reward. 不過想來應該會允許使用者提高或增加 Reward 的數量, 畢竟如果是有價值的產品, 利用 ConceptFeedback 作為一個蒐集意見的平台也是值得的. 另外 ConceptFeedback 應該也有一些防止 Cheating 的機制才是.
其實除了 Consultant 的實質功能之外, ConceptFeedback 整合了相當多過去的概念, 例如網路商業廣告 ( 還記得上一個網路泡沫之前, 滿天飛的 "邊上網看廣告邊賺錢" 嗎 ), 知識分享社群, 網路問卷調查服務, 網路拍賣平台 ( 管理與貨物提供者的責任分離 ) 等等.
但相對來說, 就跟網路拍賣平台一樣, 可能會面臨容易出現強力競爭者的情形. 不知道 ConceptFeedback 或是其他的競爭者, 要用甚麼樣的策略來勝出 ? 跟有實力的 Consultants 具體簽約 ? 或是在 Profiling 上有過人之處 ?
Online Web Service Monitoring based on Constraints from Requirements
The idea behind Wang et al.'s paper "An Online Monitoring Approach for Web Service Requirements" [1] is simple and useful. The challenges their study faced is to ensure the behavior of Web services consistent with their requirements. To achieve that, a monitoring approach is taken. They built a monitoring model including five specific system event types. Further, a monitoring framework is also built to providing probes, agents, and analysis components based on the monitoring model. In short, this study contributes an external behavior monitoring approach to ensure the Web service behavior to be consistent with requirements.
Extended Questions and Remarks:
- Is the same chanllenge ever discussed in conventional software development, ex. CBSD ?
- What's the trade-off applying this approach in practice ? ( required extra human resource, development and maintenance effot, and so on )
- Can some constraints mentioned in this study be validated using Web service testing tools in development phases ?
- The security issues behind this approach : Who can be the administrator and What services can be monitored ?
References
[1] Q. Wang, J. Shao, F. Deng, Y. Liu, M. Li, J. Han, and H. Mei, "An Online Monitoring Approach for Web Service Requirements," IEEE Transactions on Service Computing, vol.2, no.4, pp.338-351, Oct./Dec. 2009
Operating NS3 with Python
最近可能會要很奇怪地使用 NS2 來作一些 Simulation, 雖然還不是很確定需不需要使用, 最近趁空未雨綢繆一下.
但, 說真的 NS2 雖然大量地被 Network Research 人員使用, 也有很多已高度開發的模組, 但是一來我需要的使用方式其實不是模擬傳統的 Network, 二來不熟悉的大量程式碼真是看不下去. 所以其實我早早就把目標鎖定在 NS3.
NS3 的基本中文介紹在 morechr 的 blog 很早就寫了, 不過一年半來中文的資料也沒增加多少, 想來 NS2 就足夠現在的研究人員使用了吧, 況且 NS3 的重點擺在完全地利用 Script 來操控, 許多需要利用到 Pointer 的模組應該短時間內也很難轉移. NS3 架構概圖 ( 取自 NS3 Official Site ) :
但是對我來說, NS3 看起來似乎比 NS2 易用多了. 主要的操作介面已經提供 Python Binding, 也有實驗性的 PyViz 模組. 光是安裝時一個 $> python build.py 就感覺很爽快 : p
在 Tutorial 上, 我覺得 NS3 官方的 Tutorials 跟 Overview 投影片都很難讓我這初次接觸的人看懂, 倒是 G. Carneiro 的這份投影片(PDF 檔案) 我覺得做的不錯, 搭配 NS3 的 example/tutorial/first.py 程式碼, 一下子就可以了解個大概.
PyViz 模組最近的 ChangeLog 看的不是很明白, 照 changeset 5973 的訊息, 應該是已經 merge 到 NS 3.7.1 了才是. 但是實際下載 NS 3.7.1 看起來是沒有包含 PyViz 的, 所以或許他的意思是在 http://code.nsnam.org/gjc/ns-3.7-pyviz/ 底下 merge 了 NS 3.7.1 , 一番嘗試最後還是使用 Mercurial 複製了一份 http://code.nsnam.org/gjc/ns-3.7-pyviz/ 下來. ( 請跟 ns-allinone 分開 )
在 PyViz 的網站說明中, 提到要再跟最新的 NS3 作 merge 的動作. 不過因為 clone 下來的 ns-3.7-pyviz 已經被開發人員進行過 merge 了, 就不需要再做一次.
使用 PyViz 還需要額外安裝許多模組, 除了基本的 Graphviz 之外, 還有 PyViz 頁面中提到的 pygraphviz, kiwi ... 等等. Ubuntu 的使用者安裝似乎比較方便, 可憐的 Mandriva 使用者 ( 而且還是 MDV 2008 = = ) 就直接乖乖自己安裝吧.
其中
- pygraphviz 可以利用 easy_install 從 pypi 安裝,
- python-kiwi 直接從 Package Manager 找出來裝 ( 不要直接找 Kiwi 來裝, 不一樣的東西 <= 犯錯的笨蛋 ), python-kiwi / Kiwi framework 是連接 GTK+ 的套件
- PyGoocanvas 也沒辦法從 pypi 安裝, 但是手動安裝要補充的套件太多, 相當麻煩, 最後我選擇從 MDV Package Manager 裝比較舊版本 0.9.0 的套件 ( 目前最新為 0.14 ), 反正這是 GTK+ 跟 GooCanvas 的 Binding Package, 從 Package Manager 裝可能還比較安全
- python-gnome2 也是從 Package Manager 裝, 但是在 MDV 裡面似乎是叫做 gnome-python 套件
- python-gnomedesktop 我猜測是等同於 MDV 裡的 gnome-python-desktop 套件
- python-rsvg 在 MDV 底下真的找不到東西裝了, 猜測是裝在 pycairo 裡, 這之前透過 Package Manager 裝過了
- 最後記得到 pybindgen 抓取 1.14.0 版本 ( ns-3.7-pyviz 需求 ), 解壓縮到 ns-3.7-pyviz 底下
接著在 ns-3.7-pyviz 底下執行 :
$> ./waf configure --with-pybindgen=./pybindgen-1.14.0
$> ./waf --pyrun examples/flowmon/wifi-olsr-flowmon.py
首次執行因為要重新 build 整個 ns-3.7-pyviz 所以要跑一段時間. 最後還是出現幾個小問題,
- 缺少 libgraphviz.so.4 , 因為我的 MDV 2008 裡面只有裝 libgraphviz3 , 所以又更新了 libgraphviz4 .
- 找不到 gnomedesktop module, 此模組不知道為什麼被藏在 gnome-python-applet 套件裡, 同樣從 Package Manager 裝上
再重新跑一次:
$> ./waf --pyrun examples/flowmon/wifi-olsr-flowmon.py
這樣一番折騰 ( 所謂的 Dependency Hell 阿 ) 終於把 PyViz 跑起來了.

左下角有一個 Advanced 延伸調整選單可以展開, 右下角有 Snapshot, Shell, 以及 Simulate 命令. Snaphot 可以擷取目前截圖存成 PDF 檔案, Shell 可以開啟動態 Manipulation Command Line, 在 PyViz 的說明中有提到. Simulate 就是開始進行 Simulation 的命令.
以下是進行中的畫面, 懶得錄下來放到 Youtube, 截圖就好 XD

可以調整 Zoom 以及速度, 方便檢視 Simulation 可能出錯的地方.

初步的嘗試大概到此為止, 花了不少時間跟功夫, 不過至少有成功執行. 通常這樣的嘗試超過一半的機會最後是不了了之的 : p
Continuous Game Content Provision
今天看到 Nintendo 跟 Google 合作的遊戲安藤ケンサク, 雖然看不太懂遊戲的進行方式, 但是從少量 blogs 跟 forums 的簡短說明, 大致上可以知道跟 Search Engine 的 Search Keywords 有關, 利用 Google 在 Search Engine 上所累積的統計資料來產生新型態的 Q/A 遊戲, 最大的特點是問題的答案可能會隨著時間改變 -- 因為 Google Search Engine 所累積的資料也在變動中.
緊接著又在 JustineTV 看到人家在玩暴雨殺機 ( Heavy Rain ), OMG, 我真的脫離新遊戲太久 這遊戲的畫面真棒, 運鏡跟電影拍攝手法好像. 剛好看到玩家操縱的角色在房間裡探索, 看起來應該是遊戲初期, 中間有一度打開電視, 看到跟案件劇情相關的新聞報導, 然後把電視關掉.
這在一般追線索的解謎遊戲中常常看到類似的橋段, 但是今天我卻忍不住再想, 如果再打開電視一次會怎樣 ?
遊戲的 NPC 或裝置 ( 包含電視 ), 通常都是有固定集合的對話或是資料, 為了避免太死板, 又會循環或亂數出現這些對話. 但從安藤ケンサク的例子, 是否我們可以開始考慮跳脫這樣的限制, 讓遊戲更加跟已經有的 Online Data 作結合 ?
例如上面的開電視, 如果遊戲本身把該電視跟 Youtube 或其他 Onlive Vedio Service 作結合, 就可能在重開時看到其他的新聞, 這樣似乎也會很有趣 :)
Cloud Computing Bibliography for Software Engineering
All bibliography articles were made available online before 2010-04-10.
This survey covers only representative Conferences and Journals in software engineering and cloud computing domain. All articles were retrieved by keyword "cloud computing". Surprisingly, literature directly related to "cloud computing" and "software engineering" is still rare.
J. Cappos et al. developed a cloud computing education environment "Seattle" [1][14] (Thanks to Ivan). Unfortunately I did not find further information about "Seattle". On the other hand, Eucalyptus is used in E. Caron et al. work [11]. Maybe Eucalyptus will be a good start for cloud computing practice for those who have no resources accessing Amazon S3/EC2, or limited by Google GAE.
E. M. Maximilien et al. [2][3] revealed a part of IBM's directions to the cloud computing. The idea to build cloud-agnostic middleware is definitely not new. Is not Hardware-Server-PHP-MySQL-PHPWebsite similar to this solution ? Of course the scale is totally different, but the middleware idea is basically the same.
Some considerable statement can be found in ACM roundtable series on cloud computing [6]. For example, G. Ramleth, CIO of Bechtel, said : "This is not a technology game but a change-management game."
L.-J. Zhang et al. tried to pull cloud computing back to connect with service-oriented computing / SOA [7]. Some other related work can be found in International Conference on Cloud Computing ( IEEEXplorer link here ).
Althoug the data service is one of the ealiest applications in service-oriented computing and cloud computing, there seems still much to do in this field [8][9]. Same as the study of cloud computing in the end user living environment [4][12]. Is that cloud computing the game of IT companies ? Or the users will be forced to involve in the cloud computing ? To this issue, A. Lenk et al. [13] organized the cloud stack and adds an extra layer : Human-as-a-Service (HuaaS) which is not general mentioned in other studies. Unfortunately, no further discussion is made.
Bibliography
[1] J. Cappos, I. Beschastnikh, A. Krishnamurthy, and T. Anderson, "Seattle: A Platform for Educational Cloud Computing," SIGCSE, pp.111-115, Mar. 2009
[2] E. M. Maximilien, A. Ranadahu, R. Engehausen, and L. C. Anderson, "Toward Cloud-Agnostic Middlewares," OOPSLA, pp.619-625, 2009
[3] E. M. Maximilien, A. Ranadahu, R. Engehausen, and L. C. Anderson, "IBM Altocumulus: Across-Cloud Middleware and Platform," OOPSLA, pp.805-806, 2009
[4] C. Ragusa, F. Longo, and A. Puliafito, "Experiencing with the Cloud over gLite," Proceedings of the 2009 ICSE Workshop on Software Engineering Challenges of Cloud Computing, pp.53-60, 2009
[5] J. S. Rellermeyer, M. Duller, and G. Alonso, "Engineering the Cloud from Software Modules," Proceedings of the 2009 ICSE Workshop on Software Engineering Challenges of Cloud Computing, pp.32-37, 2009
[6] M. Creeger, "CTO Roundtable: Cloud Computing," CACM, vol.52, no.8, pp.50-56, Aug. 2009
[7] L.-J. Zhang and Q. Zhou, "CCOA: Cloud Computing Open Architecture," ICWS, pp.607-616, 2009
[8] M. Vrable, S. Savage, and G. M. Voelker, "Cumulus: Filesystem Backup to the Cloud," ACM Transactions on Storage, vol.5, no.4, article 14, Dec. 2009
[9] R. Agrawal et al. "The Clarement Report on Database Research," CACM, vol.52, no.6, pp.56-65, June 2009
[11] E. Caron, F. Desprez, and D. Loureiro, "Cloud Computing Resource Management through a Grid Middleware: A Case Study with DIET and Eucalyptus", International Conference on Cloud Computing, pp.151-154, 2009
[12] K. Kumar and Y.-H. Lu, "Cloud Computing for Mobile Users: Can Offloading Computation Save Energy ?" IEEE Computer, preprint, Mar 2010
[13] A. Lenk, M. Klems, J. Nimis. S. Tai, and T. Sandholm, "What's Inside the Cloud ? An Architectural Map of the Cloud Landscape," Proceedings of the 2009 ICSE Workshop on Software Engineering Challenges of Cloud Computing, pp.23-31, 2009
[14] Seattle, https://seattle.cs.washington.edu/html/
CCE Posters
大約兩個禮拜前我幫成大電通所做的兩張海報終於印好公開展示了 :)
這海報是要把成果展示給高中生看的 ( 話說為什麼要作這種事阿 = = ) 當初我申請入學的時候怎就沒有這等待遇... 現在既有交通車, 還有午餐點心, 還有教授解說...
Here's the original design of the two posters : 左邊黑色那張是用 SE4PP/SIMPLE 為主設計的 ( Head-First 風格 XD ), 右邊那張是林輝堂老師 NSDA 實驗室的天使之眼, 加上詹寶珠老師 SMILE 實驗室提供的部份計畫材料完成的. 其他 Lab. 沒提供材料就沒辦法摟~
左邊黑色那張是用 SE4PP/SIMPLE 為主設計的 ( Head-First 風格 XD ), 右邊那張是林輝堂老師 NSDA 實驗室的天使之眼, 加上詹寶珠老師 SMILE 實驗室提供的部份計畫材料完成的. 其他 Lab. 沒提供材料就沒辦法摟~
本來覺得藍黃底色配色很普通有點擔心, 但是其實出來的效果還不錯. 左邊那張被實驗室的 DC 照醜了, 其實做出來的質感搭配木框很不錯, 右邊的漸層效果也很不錯, 唯一的缺點是 NSDA 的 Logo 可能因為輸出軟體跟 Inkscape 在解讀透明圖層上有點差異, 結果變成了色塊了, 不然那邊應該也是漸層的.
左邊那張被實驗室的 DC 照醜了, 其實做出來的質感搭配木框很不錯, 右邊的漸層效果也很不錯, 唯一的缺點是 NSDA 的 Logo 可能因為輸出軟體跟 Inkscape 在解讀透明圖層上有點差異, 結果變成了色塊了, 不然那邊應該也是漸層的.
兩張一起照, 這張看起來好點 : 稍微看了一下其他組的, 覺得還是自己做的這兩張好, 其他很都多都只是貼圖跟文字資料, 還有只有精神標語的, 以及錯別字錯很大的 XD
稍微看了一下其他組的, 覺得還是自己做的這兩張好, 其他很都多都只是貼圖跟文字資料, 還有只有精神標語的, 以及錯別字錯很大的 XD
海報製作除了 DBSE 實驗室自家材料以及兩個實驗室支援的材料, 純粹使用 Inkscape, GIMP, cwTeX 字體, OpenClipArt 素材加以修改, 十分感謝 :)
A Very Very Short CSCST 2010 Review
前幾個禮拜, 3/27, 3/28 到圓山參加 CSCST 2010, 簡短作個紀錄. ( 聽說第一天 Prof. Jane 跟金仲達教授的 Panel 戰很大 -- 當然不是這兩位戰啦, 沒跟到真是可惜 : p )
因為時間還有我的新西裝修改不及等因素, 第一天只有到最後的 Cloud Computing Panel, 值得記下東西不多. 老師在 Cloud Computing Panel 的總結在 Lab. 會議就已經聽過了, 其他除了台大劉邦峰教授相當 "中肯" 的 "擔憂" 之外, 大多聽起來並無新意, 只是把就有的研究方向拉上 Cloud Computing, 除非有更深切的動機, 這樣作的意義其實不大.
第二天一早的 Software Technology for Green Environment Panel 也差不多, 主要提到的 Smart Traffic Control System, Algorithm Improvement, Multi-Core Processors, Cloud Computing 是都可以跟 Green Environment 扯上關係啦, 但是我個人覺得 Green Environment 不等於 Energy Saving 以及 Environment Protection, 而且應該跟日常生活更加緊密的結合才對. 舉例來說好了, 垃圾分類之所以難達成, 很大的原因是因為人都很懶, 丟在一起比較方便, 這也是事實. 現在垃圾分類的政策是要求使用者要分類, 也就是要改變原本大家都丟在一起的行為 ( Behavior ).
Rule 101 : DO NOT TRY TO CHANGE THE USER BAHAVIOR IN THE BEGINNING
為什麼就沒人想結合控制跟影像辨識, 在合理的花費下研究自動的垃圾分類機制. 或許機制無法完美, 但是清潔人員要花的功夫就更少, 這樣不是也不錯 ?
另外對岸一位女教授 ( 抱歉因為 Panelists 沒有在 Program 上列出名單, 當場記不得 ) 稍微提到 :
Will the environment protection and weather concern become the “new” non-functional requirement ( constraint ) ?
其實這兩種 "Forces" 一直都在 Requirement Engineering 中, 只是份量不重, 因此我認為更適切的問題是, 是否這兩種 "Forces" 會被更加嚴格地要求並在 Spec. 中變得更加重要 ? 不過這個話題在這樣的 Panel 自然只是一閃而過沒有被深入討論.
第二場的 Panel 主題是 Software Tool and Environments. 主持人是對岸的董淵教授.
董教授一開始的開場很有意思, 提到 Environments 的雙關性 ( 特地加了複數形 "s" ), 不過基本上整場 Panel 都只在討論 Programmer 所認知的 "Environment" 而已, 真是多虧了董教授一開始有意思的開場. 前半段討論的一些事項在我看來非常的瑣碎, 而且不如說更偏向 "Software Running Environment" 的討論, 直到清大的白曉穎教授提到工具的量與質, 還有是否我們需要如此多工具, 有如此多工具但是 Software Development Process 還是充滿了困難等問題時才有趣一些.
後面我自己的 Regular Presentation, 以及後來額外聽了一場 Presentation, 都覺得沒什麼特別可以提得, 有些甚至只是前幾年已經提過了的東西.
Game-based Competitive Learning
News from GamePro : Game design professor beta tests a new grading system ( Prof. Lee Sheldon's project )
It's not a noval idea, but always an interesting practice.
我還記得唸大學時, 聽過成大資工的密碼學課程, 期末的 Final Project 是要各組設計一套 Public Key/Private Key 機制, 然後互相嘗試攻擊, 被攻破的組別會被扣除一定分數, 相對來說攻破其他組則會加一定分數, 當時就覺得這樣作很有趣. 類似的概念我最早接觸到應該是國小時看 MacGyver, 其中有一集是大學生各自設計獨特的門鎖, 也是要設法突破對方的設計. 我們 Lab. 也早在幾年前就開始嘗試 Game-based Programming Learning 給大一學生.
多元的上課跟訓練方式絕對是好事, 但是難免會受到設計品質跟評量標準一致性的限制. 但是話說回來, 出了學校, 哪裡還有一致的評量標準呢...
不過換個角度來想, 如果不要把眼光侷限在傳統學校內, 而是放到更加專業的公司訓練課程, 或許很有發展空間. 許多公司的工作其實充滿大量的 routine work, 有遠見的老闆會設法保持員工的活力, 如果有專門的課程訓練公司, 可以為不同種類的公司及團體設計特殊, 有趣的學習課程, 而不是像目前許多應付了事的電腦職訓課程, 或許意外地有商機 ?
Johnny Mnemonic Again
看到這個 Do Crew (RWW 連結) , 一定要再提一次經典的 Johnny Mnemonic 啊. 當初基諾李維的操控, 過了 15 年之後, 連小孩子用的設備跟效果都比當初好了.
Johnny Mnemonic 跟珊卓布拉克的 The Net 是個人認為好萊塢早期引入具體的電腦科技想像, 最重要的兩個嘗試, 雖然兩部片評價都很低, 也讓在 Speed 中紅起來的兩人各自迎接第一個低潮期...
Platform Selection in System Analysis - About Apple's Policy
Mashable news article : "The Apple-Adobe War Escalates: Using Flash to Build iPhone Apps Banned" brings me an interesting thought.
在 System Analysis 或決定 Software Features 的時期, Platform 的選擇一直是一個很重要的考量因素 ( Factor ). 不過在一般的系統中, Platform 往往被過份忽略 -- 因為我們主要的選擇就是那些, 同時看起來對後面的 Software Development Phases 很少有極具限制性的影響. 大部分時候, 似乎主要的限制都是還來自於問題本身 ( 例如 Embedded Systems 中的資源限制, 可用背景函數限制 ), 而不是受限於 Platform 的選擇.
而在 Windows / Linux ... 層級的作業系統 Platform 選擇上, 真正會影響到一般 Apps 開發的因素就又更少了. 於是我們在 Software Development Phases 有很高的自由度去決定其他的事情, 例如可用的 Framework, API, Programming Languages, Compilers 等等.
但是 Apple 的限制提供了一個反向思考, 是否我們真的一定需要有如此高的自由度 ? 限制越多, 是否 Software Development Process 可以越簡單 ? 以及選擇 Platform 在開發限制上的影響對比更重要的商業利益, 是否的確微不足道 ?
- 增加延伸分析連結, 2010-04-11 : http://daringfireball.net/2010/04/why_apple_changed_section_331
Online Game that Requires Specialists...
昨晚在看 Caprica 時, 想到一個很有趣的對比.
Caprica 是 Battlestar Galactica 的前傳, 講述複製人 ( Cylon ) 的誕生以及疑似毀滅 12 Colonies 的計畫起源. 不過這劇情在此無關緊要. 在 Caprica 中, 女主角 Zoe 的父親 Daniel 所開設的公司透過 AI 以及全息影像技術, 發明了 "Holo-Bands", 類似眼鏡的裝置, 不過戴上時要閉起眼睛, 透過該裝置給予眼睛的刺激來讓使用者置身虛擬世界 ( VR ). 我覺得這篇 Singularity Hub 上的簡介寫的不錯, 不需要知道劇情, 只要對目前的相關技術略知一二即可對照.
有這樣的技術跟裝置, 當然衍生出很複雜的虛擬遊戲世界. 但是不同於目前的 Online Game, 在 Caprica 中的虛擬世界是很嚴峻的, 你在每一個虛擬世界中死亡的話, 將永遠不能再次進入該虛擬世界, 因此真人跟自己的 "Avatar" 是 One-to-One 的對比.
而在這樣的設定下, 當你必須在該遊戲中達成某項任務或是目的時, 非常有可能是你一個新加入的人作不到的 ( 例如要在充滿黑幫的市區中找尋特定角色, 同時該市區還不斷地被飛空艇轟炸 = = ). 而遊戲本身也不會給予你的 Avatar 任何特殊技能 -- 說穿了你的 Avatar 跟本人在一開始的能力是完全一樣的.
因此在 Eposide 106/107 的劇情中, 某劇中角色就需要在遊戲中僱用類似傭兵/領路人的角色 ( 也是真實世界中的某人 ), 然後付費給真實世界中的玩家, 來完成找人的任務.
這樣的模式跟目前 Online Game 會有上班族花錢請人練角色等級看起來很像, 但是這兩種遊戲在設計本質上有極大的差別. ( 當然, 兩者所預設面對的 "Problems/Requirements" 其實也是不一樣的 )
在一般的遊戲設計中, Challenge Levels 的規劃是一項很重要的議題, 通常會避免只有單一的 Challenge Level ( 遊戲極簡單或是極難的情況 ). 當然這也是要視情況而定, 例如很多小遊戲本來就只想你花幾分鐘玩完就算了, 達到宣傳或其他效果就好, 這樣的 Challenge Level 就單一且極低. 但是 Caprica 中的遊戲, 其 Challenge Level 在我看來是極高的, 在那樣的世界中, 單獨一個人的生存率極低, 而依靠已經成功在該世界中生存下來的專家 ( Specialists ) 才會有比較高的存活率.
這樣的 Game 在現在的 Online Game 觀念中應該很難賣, 也不可能被做出來賣吧 ( 想像你在 Diablo II 中的角色, 死亡一次就掰掰要整個從新世界玩起... ), 但對某些人來說卻是刺激度滿點的遊戲, 同時這時候遊戲中的合作嚴謹度也可能會完全不一樣.
這樣, 才是真的靠玩遊戲當作職業賺錢吧, Specialists 死亡一次就失業了 XD
Paper Bad Smell Detection (2)

- Long Sentences
- Vague Words
- Countable/Uncontable Words
- Similair Words
- Verb Auxiliary + V-ed Violation
Dynamic IEEEXplorer Online Limitation ?
當你 24 hours 都有機會使用 IEEEXplorer 時, 就會察覺某些特定的時間, "All Seats were Occupied !!"
這些時間包含了正常工作日的下午 1 ~ 4 點, 晚上的 10 ~ 凌晨 02 點 (偶爾, 打完電動該查個 paper 了是吧). 以及禮拜天晚上, 禮拜一早上 (要趕 survey 給老闆交代是吧). 遇到這些時段受人數限制連不上當然就很討厭.
當然 IEEEXplorer 要付費限制上線人數 絕對有道理, 目前成大買的是同時間 15 seats, 但是考量沒有正常 logout 導致的 penalty (很多人習慣不好阿), 真實的 availability 應該是會小於 15 seats 應該有的效果.
但是如果我們以 IEEEXplorer 的伺服器總負荷量以及總頻寬量, 以及全球服務的角度來看的話, 其實不同國家的研究人員使用 IEEEXplorer 的頻繁時段是不一樣的, 像是台灣的深夜幾乎不可能遇到 all seats occupied 的情況. 不同時區顯然使用曲線不同. 是否 IEEEXplorer 應該在同樣的費用下, 採用動態調整, 讓使用效益最佳化 ?
After You Re-Install the SCIM...
上週去參加 CSCST 2010 前夕, 我那本來就有點不太聽話的 SCIM 正式掛點了. 原因不詳, 總是當初隨 Mandriva 2007 裝的 SCIM 1.0 很容易在快速切換 Apps. 以及輸入法時陷入短暫 Idle 的狀態, 特別是當 Firefox 參與其中時...
索性移除所有 SCIM 相關 Packages, 整個重裝, 不過結果是只要進 KDE 所有 Apps 都開不起來, 會被 SCIM 或是 SCIM-Bridge 暴衝卡住 CPU, 就算砍掉 SCIM processes 還是會再跑起來. 直到現在我還是搞不懂為什麼 Apps 跑起來的時候都要先跑 SCIM 或 SCIM-Bridge ?
不過參加會議在即, 就先不管他, 直到回來又花了一天才修好. SCIM 跟 SCIM-Bridge 的選擇姑且不提, 在安裝新酷音 chewing 時, 又遇到裝上了, 卻無法開啟 SCIM-setup 來調整的情況, 當然也就無法使用 chewing. 倒是其他的輸入法就沒這問題.
總之, 後來發現 SCIM 重裝跟 chewing 重裝都注意把 .scim 跟 .chewing 先移除或是清空, 否則就出現上面奇怪的情況.
是否利用 Package Manager 移除 Package 時, 應該更 "Smart" 地主動考量 Configurations 一併移除的問題呢 ?