
The Economic Power of BUG Labs + Open Source
前幾天寫了關於 BUG Labs 的一些觀察, 剛好這兩天因為 Lab meeting 的緣故看了一篇文章, 是 Dirk Riehle 的 "The Economic Motivation of Open Source Software : Stakeholder Perspectives" [1]. 在文章的前半段, 作者用了兩張圖來解釋 open source 對於 software company 獲利的影響.
第一張圖 ( referred and re-drawed from [1] ) 如下, 橫軸是潛在的願意購買 customer 數目, 縱軸是 customer 需要付出的價錢. 一個完整的 product 是由 hardware, software, 以及 services 所構成, 而非單只有其中一者. Customer 的需求被 modeling 成為一條曲線 ( 雖然圖上是一條直線, 不過這只是示意圖 ). 當 open source 被引入 software 那個區塊時, 由於對於整體 product 來說, 軟體的研發製作成本降低了, 因此在維持原售價的情況下, software company 可以從每個 customer 身上獲得的利潤就會增加.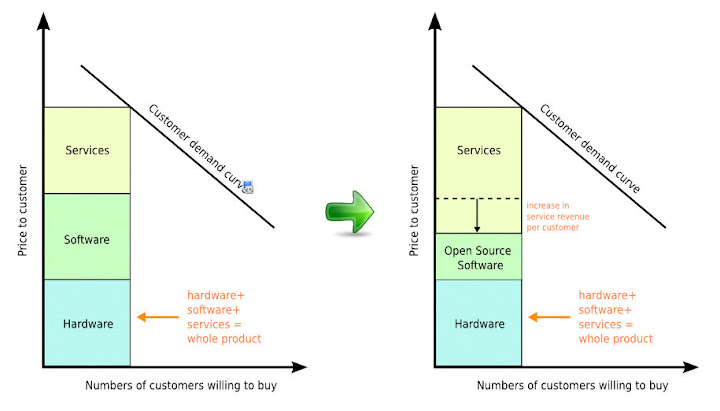 而假使 software company 的利潤完全來自於 service, 而不包含販賣 hardware 以及 software 時可能獲得的利潤, 這時整個 hardware 以及 software 的兩個部份對於 product 就是完全的成本而已. 那麼扣掉 service cost, 剩下的就是 software company 可以獲得的 service profit.
而假使 software company 的利潤完全來自於 service, 而不包含販賣 hardware 以及 software 時可能獲得的利潤, 這時整個 hardware 以及 software 的兩個部份對於 product 就是完全的成本而已. 那麼扣掉 service cost, 剩下的就是 software company 可以獲得的 service profit.
當然 service profit 會根據最後的 service 定價而定, 假設 service 最低價要高於所有的成本, 那們我們就可以在成本與 customer 需求曲線之間括出一塊可以獲利的區域, 在下圖左中以灰色區域標示. 當 open source 取代原本的 software 區塊後, 可以想見的, 因為成本降低, 因此可獲利區域也就隨之增大. 同時藉由價格的調降, 負擔得起該 service 售價的 customer 將會變多, 亦即相對市場就可以變大. 這是下圖右的說明.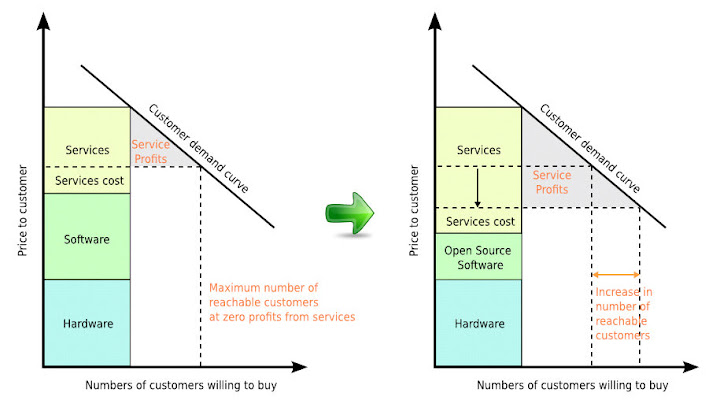 在 [1] 中並未討論到 hardware 的問題. 而如果我們考量 BUG Labs 的願景, 以及所謂 open source hardware 的想法, 很有可能我們可以基於 open source software 之上, 把成本再一次地降低, 使得更多的人可以負擔起一樣的 service.
在 [1] 中並未討論到 hardware 的問題. 而如果我們考量 BUG Labs 的願景, 以及所謂 open source hardware 的想法, 很有可能我們可以基於 open source software 之上, 把成本再一次地降低, 使得更多的人可以負擔起一樣的 service.
下圖左是只有 open source software 的樣子, 下圖右把 hardware 部份用 BUG Labs 取代, 由於硬體部份不再需要一個整體性的產品, 而是可以讓 customer 根據自己的需要選購適用的硬體, 電子製造商將沒有辦法將電子產品的硬體規格掌握在手中, 因此我認為這部份的成本可以降低. ( 事實上也可能帶動 open source software 部份的成本再度降低, 因為 open source software/hardware 的整合會在 project 中完成, 不需要採用者額外進行, 但這裡先不考量這一點 )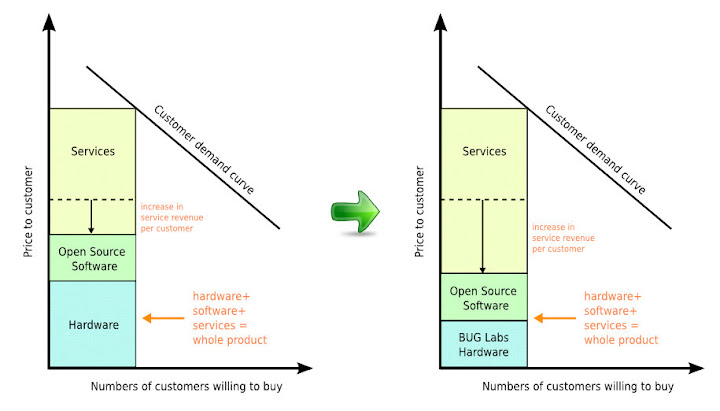 很顯然的, 所帶出的結果就是 service profit 的可調整空間再度變大, 同時有意願購買, 也有能力購買的潛在 customer 市場也變得越大. 對於 customer 來說, 將可以用更加便宜 (或者該說是更加有彈性) 的購買方案, 來獲得需要的 service.
很顯然的, 所帶出的結果就是 service profit 的可調整空間再度變大, 同時有意願購買, 也有能力購買的潛在 customer 市場也變得越大. 對於 customer 來說, 將可以用更加便宜 (或者該說是更加有彈性) 的購買方案, 來獲得需要的 service.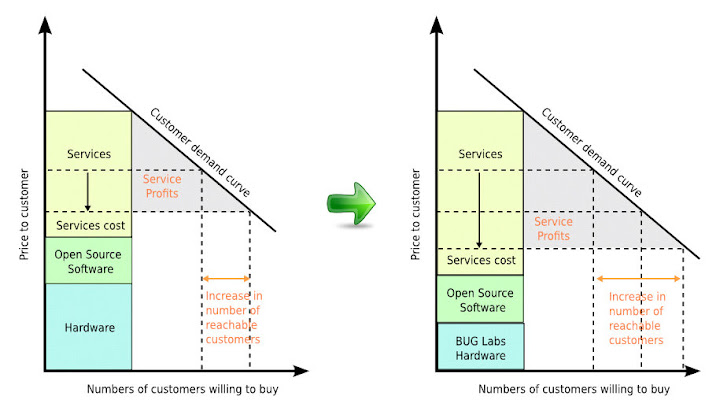 同時在這樣的市場中, Long Tail 的效應可能會更加明顯, 因為新的 service 未必一定要搭配新的 hardware, 在目前的市場中受限於電子製造商, 使得我們要換 service 好像就一定要買新的 device, 手機就是一個很明顯的例子 (如果我可以把現在手機的 300 萬畫素攝影模組移到新手機, 我就不用買新手機的 600 萬畫素模組, 我只需要 300 萬畫素的就夠用了 ).
同時在這樣的市場中, Long Tail 的效應可能會更加明顯, 因為新的 service 未必一定要搭配新的 hardware, 在目前的市場中受限於電子製造商, 使得我們要換 service 好像就一定要買新的 device, 手機就是一個很明顯的例子 (如果我可以把現在手機的 300 萬畫素攝影模組移到新手機, 我就不用買新手機的 600 萬畫素模組, 我只需要 300 萬畫素的就夠用了 ).
References
[1] Dirk Riehle, "The Economic Motivation of Open Source Software : Stakeholder Perspectives," IEEE Software, pp.25-32, April 2007
BUG Labs : decide what YOU can use, it's YOUr call
在說到 BUG Labs 之前, 先看看這張圖 (取用自 BUG Labs 公開可用圖庫) :
這張圖是什麼 ? 看起來有點像一些小積木疊在一起, 然後用線連著, 然後每堆好像長的不太一樣. 每堆中好像都有一個比較特殊的, 邊邊帶有灰色矩形的積木存在. 其他就不一定. 這是什麼 ?
身為 software scientist (it this term exist) 以及 hacker, 我們看到一個喜歡 software 時往往會首先想到兩件事, 第一是 : 這東西怎樣運作的, 第二個是 : 我要怎樣把他改成可以跟我手邊的其他 software 合作. 一般的使用者不會這樣想是因為, 一般使用者難以認識到內部的運作, 從而即便想了第二個問題, 也沒辦法用自己的能力讓想法實現.
而 BUG Labs, 就是想要讓這樣的事情變成可能.
BUG Labs 採用 Lego 積木的想法, 把 computer 拆解成數個方塊, 每一個方塊上具有一個或是數個 services, 例如 GPS 應用, 數位攝影機, Webcam, LCD 小螢幕, 或是鍵盤. 同時 BUG Labs 提供一塊小小的 motherboard, 讓你可以自由地把這些方塊插上去.
BUG Labs 的 product 網頁上給了一個例子 : For example, with BUG, you can easily assemble and program a GPS + digital camera device that automatically publishes geo-tagged photos as a web service. Integrating with an online photo-sharing service like Flickr is only a few more lines of code away, and now you have your own real-time, connected traffic-enabled mobile Webcam!

 這樣的想法並非全新, 至少在 software 領域, component-based software development (CBSD) 的發展已久, 即便是後來的 service computing 也預計會朝同樣的路走下去. 而在實際的產品上, 我記得已經有教育性的產品是透過 USB port 標準, 可以把不同的 software 事先安裝在 USB 上, 然後孩子用的主機不需要進行軟體安裝, 而是透過主機上數十個 USB port, 匯入不同的 softwares 共同運作. 但是相對來說 performance 就不適合一般使用.
這樣的想法並非全新, 至少在 software 領域, component-based software development (CBSD) 的發展已久, 即便是後來的 service computing 也預計會朝同樣的路走下去. 而在實際的產品上, 我記得已經有教育性的產品是透過 USB port 標準, 可以把不同的 software 事先安裝在 USB 上, 然後孩子用的主機不需要進行軟體安裝, 而是透過主機上數十個 USB port, 匯入不同的 softwares 共同運作. 但是相對來說 performance 就不適合一般使用.
而 BUG Labs 應該是在非教育領域, 第一個把這樣的概念具體化成為一般消費用商品, 並公開展示的公司. 歐, 我沒有提到更棒的是, 他們希望是採用 open source software / hardware 的概念來推廣.
在每一個方塊內當然會有相對的 software 可以提供 service, 同時也可能有必要的 operating system 在裡面. 不同的方塊之間基本上透過 OSGi 進行 communication. ( 但由於 OSGi 的 license 問題, 使得 BUG Labs 無法直接使用 OSGi 的 source, 否則對於他們的 open source 計畫會造成阻礙, 於是他們重寫了 OSGi 的 implementation [1]) 然而使用者並不需要了解這些, 使用者只需要把他們想要的某項 application, 所需要的方塊都插到 motherboard 上就好了.
需要知道這些的是 service developer, 可能是 open source community 的人, 也可能是 commercial company 的人. 透過 BUG Labs 提供的 motherboard 作為 platform, 開發者同樣是專注在本來他想提供的 service 就好, 其他的部分是從 BUG Labs community 內可以找到的其他方塊來提供. 這也是上面第一張圖所代表的意義之一.
然而看著上面第二第三張圖, 還是會有個疑問, 看起來只有四個槽, 如果需要安裝比較多的方塊, 怎麼辦呢 ? 我想這應該可以回到第一張圖, 誰說 motherboard 上不能再接 motherboard ? 或者我可以在不同的 motherboard 之間透過 wireless 連接溝通, 一樣可以應付需要更多方塊的情況. 然而 BUG Labs 是否能夠成功仍然有很大的疑慮, 我想他們選擇 open source community 作為主要合作對象應該也是希望可以解決一些關鍵問題. 提供以及制定 motherboard 倒不是問題, 而是這樣的使用方式基本上相對於目前主流電子產品來說有別. 目前主流電子產品製造權是掌控在電子製造商手裡的, 而且軟硬體都是. 看看如果你想改造 iPod, 會遇到哪些完全是非技術性的限制. 而 BUG Labs 的產品完全是顛覆 (disturb) 目前的產品線. 在 BUG Labs 的 vision 下, 消費者才是最終決定手上的 product 長什麼樣子的人 (軟硬體都是), 而非目前的電子製造商.
然而 BUG Labs 是否能夠成功仍然有很大的疑慮, 我想他們選擇 open source community 作為主要合作對象應該也是希望可以解決一些關鍵問題. 提供以及制定 motherboard 倒不是問題, 而是這樣的使用方式基本上相對於目前主流電子產品來說有別. 目前主流電子產品製造權是掌控在電子製造商手裡的, 而且軟硬體都是. 看看如果你想改造 iPod, 會遇到哪些完全是非技術性的限制. 而 BUG Labs 的產品完全是顛覆 (disturb) 目前的產品線. 在 BUG Labs 的 vision 下, 消費者才是最終決定手上的 product 長什麼樣子的人 (軟硬體都是), 而非目前的電子製造商.
但顯然地, 這需要大量的軟硬體開發支援, 特別是 software 部分. 如果可以替換的 software service 太少, 則 BUG Labs 的 motherboards 是完全沒有意義的. 透過 open source community 的生產力以及創造力, 能夠幫助 BUG Labs 把他們的 motherboard 之可能性發揮到最大. 同時究竟消費者會希望 BUG Labs 的產品以什麼樣貌展現, 也正在進行調查中 [1].
在通往成功的路上, BUG Labs 還有很長一段要走. 但是以我們小小工程師的角度來說, 身為 BUG Labs 的一份子, 手上握著足以顛覆世界的想法以及產品, 真的是作夢也會笑阿 :)
References
[1] David Cohn@DigiDave, "Evolving from Larvae To Bug Lab: The Rise of Open Source Hardware," URL : http://www.digidave.org/adventures_in_freelancing/2007/11/evolving-from-l.html
PCManX FireFox Plugin on Mandriva 2008
雖然努力了一個小時還是沒有成功, 但是還是紀錄一下好了.
因為找不到現成的 package, 所以就打算自己處理, 參考了一些網頁的經驗分享, 首先利用
./configure --enable-plugin
進行 configuration, 產生 makefile. 這裡遇到錯誤的話就裝上該裝的東西, 需要 gtk+ >= 2.4.0, 記得要裝 libgtk+2.0_0 package. 另外記得 libmozilla-firefox package 也需要裝.
而後進行 make 時可能會在進行 po/Makefile 時遇到這樣的錯誤 :
.po.gmo:
file=`echo $* | sed 's,.*/,,'`.gmo \
&& rm -f $$file && $(GMSGFMT) -o $$file $<
command not found
這是由於 GMSGFMT 參數變成了空白, 所以 command 在執行時變成了 -o, 所以系統無法辨認. 而 GMSGFMT 空白的原因是少裝了 GNU gettext package, 裝上去就 ok 了.
繼續進行 make 可能會遇到這樣的錯誤訊息 :
Making all in src
make[3]: Entering directory `/home/scsi/tmp/pcmanx-pure-gtk2-0.2.6/plugin/src'
make[3]: *** No rule to make target `pcmanx_interface.idl', needed by `pcmanx_interface.h'. Stop.
這在摩托學園有詳細的討論, 不過這已經是 2005 的討論了, 為什麼我現在還是遇到一樣的問題呢 ? 照著 jserv 的建議, 不過看了看 Makefile.am , 還是不知道怎樣產生 pcmanx_interface.h 檔案, 加上有討論說到 pcmanx_interface.idl在包裝中是缺少的...well, 搞不清楚情況下我的 make 嘗試就到此為止了.
剛好這時候資料找著找著, 看到了 DreamerC's Backyard 有提供修正遺失檔案的 package 下載, 就直接拿來用了. 這個 package 就沒問題了, 可以順利進行 make. 而在 make install 後, 相關的檔案就會自動部屬到該在的地方. 但是 Mandriva 2008 上預設的 firefox 安裝跟一般的不同, 結果 make install 是把相關的 components 安裝到 libmozilla-firefox 裡面了.
不知道這樣的部屬 (deployment) 是否正確, 不過總之最後雖然部屬了, 還是沒辦法在 FireFox 中順利啟用 PCManX. 之後參考大步向前走的手動部屬提示, 做了檢查以及更動嘗試, 還是沒辦法進行. 只好先記下上面的東西摟, 之後有空再繼續 try 吧.
至少 make 後單機版可以用倒是沒問題.
從 Vixta OS 思考 Software User Interface Separation 的可能性
在我涉入 Software GUI 的研究領域之初, 我所思考的第一個問題其實是跟 Software User Interface Copy 有關的問題. 當時的觀察對象是 XMMS 跟 Winamp, 以及其他在 Desktop Linux 上跟已經在 Windows 上存在已久的 softwares 之間極為相似的 GUI 設計. 當時的想法是希望探討 GUI 的設計模仿跟 OSS 的成功之間是否存在關係, 以及是否 OSS 可以在發展初期藉由模仿既有的 popular software GUI 設計, 取得較大的成功優勢. 當然這背後還牽涉到怎樣把 functionality 跟 non-functionality 的 GUI 連結起來並從整個 global software 身上分離的問題, 這在目前也還沒有具體的研究成果. 不過這個想法最終是死在對於智慧財產權的考量. 因此雖然我還是在嘗試解決相關的問題, 但是採用的是完全不同的做法.
這幾天看到一個有趣的 Desktop Linux Distro. : Vixta Linux. (以下 screenshots 取自 Vixta@S.F.net)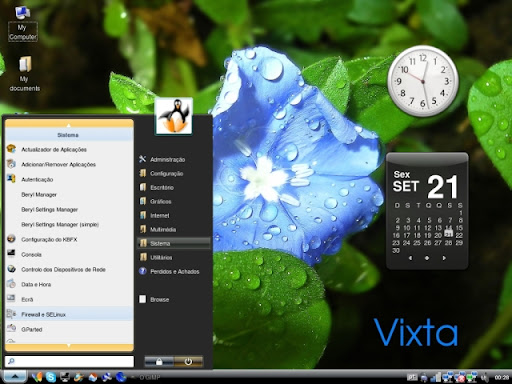 Vixta 是以 Fedora 8 為基礎作修改的 Desktop Linux Distro. , 從名稱以及外觀不難看出來是 follow Windows Vista 的 style. 雖然模仿 Windows style 這不是第一樁, 但是在隨著 EeePC 使得 Linux 能見度再度提高的同時, 出現了跟 Windows Vista 極為相似的 Linux Desktop, 還是比起之前對於 Windows 2k, XP 的模仿更具意義. 而即便是在一些操作的介面上, 例如 File Manager, 也弄得很接近 Windows 傳統的方式. (不過其實原本 Konqueror 的 side bar 比較 powerful)
Vixta 是以 Fedora 8 為基礎作修改的 Desktop Linux Distro. , 從名稱以及外觀不難看出來是 follow Windows Vista 的 style. 雖然模仿 Windows style 這不是第一樁, 但是在隨著 EeePC 使得 Linux 能見度再度提高的同時, 出現了跟 Windows Vista 極為相似的 Linux Desktop, 還是比起之前對於 Windows 2k, XP 的模仿更具意義. 而即便是在一些操作的介面上, 例如 File Manager, 也弄得很接近 Windows 傳統的方式. (不過其實原本 Konqueror 的 side bar 比較 powerful)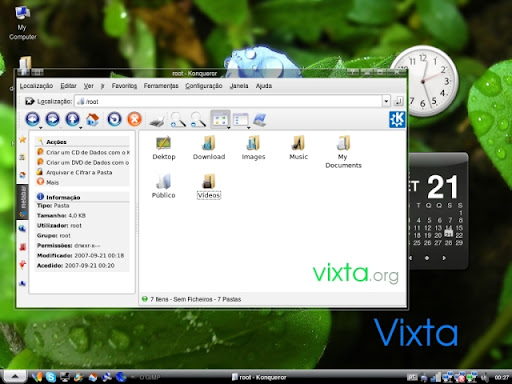 這樣的模仿, 目的之一當然是希望能夠混淆視聽, 讓使用者分不出來這是 Linux 還是 Windows Vista, 以達到想要的結果, 也就是寫在 Vixta Goals 裡的 : Spread linux to the "masses", User-Friendly, 以及 Familiar look and Feel.
這樣的模仿, 目的之一當然是希望能夠混淆視聽, 讓使用者分不出來這是 Linux 還是 Windows Vista, 以達到想要的結果, 也就是寫在 Vixta Goals 裡的 : Spread linux to the "masses", User-Friendly, 以及 Familiar look and Feel.
假設 Vixta 可以達到他想要的效果好了, 這意味著使用者無法在使用 Vixta 時分清楚究竟現在他用的是 Linux 系統還是 Windows 系統, 要達到這個程度, 不是只改改 layout 介面就可以作到的. Software GUI 的真正意涵在於連接 Software 的運作邏輯 (Software Implementation Model) 與 User 的使用邏輯 (User's Conceptual Model) [1][2], 而通常後者的可變動性 (flexibility) 是比較大的, 因此可以說 Software GUI 是決定了怎樣把 Software 的運作邏輯表現給 User, 使得 User 可以在最小修正使用邏輯的前提下, 最有效率地利用該 Software. 而如果今天出現了一個 Software GUI, 可以讓 User 察覺不到背後的系統更換, 那麼被更換的兩個系統, 與 Software GUI 之間必定有相當程度的 decoupling -- 換句話說, 在 Software GUI 與背後的系統之間有相當清楚的 Interface 存在.
D. Collins 在 [1] 中引用了 J. Bennett 的 model [3][4], 訴說 User Interface 中四個不同的主要部分 : (the figure bellow is referenced form [1] )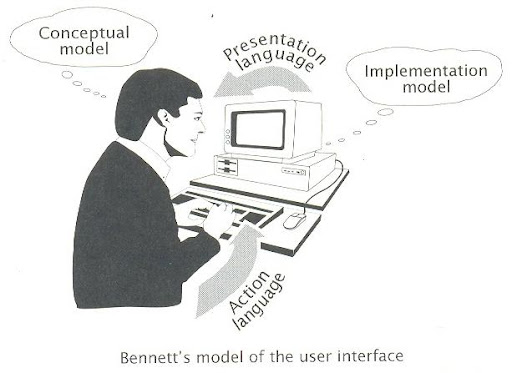 圖中的 Implementation Model 是同時包含了 hardware 以及 software 的部分. 可以看的出來各部分之間的 coupling 關係, 使得要完成一個完整的 Software User Interface Copy 是很難的事情, 因為多多少少不同的系統在 Implementation Model 上都有差異, 也會影響到 Presentation Language 以及 Action Language 的呈現. 如果為了 Copy 而去改變 Implementation Model 就有點本末倒置了. 我相信 Vixta 總不會為了要讓 User Interface 更像 Vista 一點而去改 Linux 系統本身吧.
圖中的 Implementation Model 是同時包含了 hardware 以及 software 的部分. 可以看的出來各部分之間的 coupling 關係, 使得要完成一個完整的 Software User Interface Copy 是很難的事情, 因為多多少少不同的系統在 Implementation Model 上都有差異, 也會影響到 Presentation Language 以及 Action Language 的呈現. 如果為了 Copy 而去改變 Implementation Model 就有點本末倒置了. 我相信 Vixta 總不會為了要讓 User Interface 更像 Vista 一點而去改 Linux 系統本身吧.
但是這是不是意味著 Software User Interface Separation (from Functional Application Part) 是不可能的呢 ? 我覺得倒也未必, 只是可能不會由目前的模仿之路作到, 而是透過 UI Design Patterns 的路作到. 重點還是在於 User 是否需要這樣的東西.
即便在 Windows 上也是有許多嘗試改變 Windows 預設 User Interface 的 softwares 存在, 例如比較有名的可能是仿 Mac 的 FlyakiteOSX, (figure bellow is referred from Screeshots@FlyakiteOSX)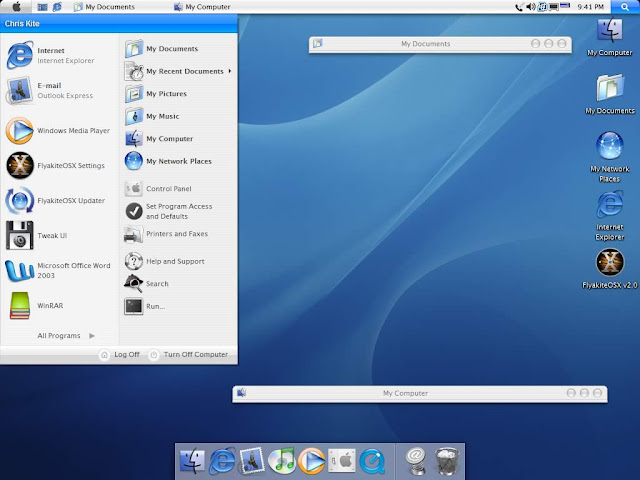 這下好了, 用 Linux 的人在用 Windows 的 Desktop, 用 Windows 的人改用 Mac 的 Desktop, 下一個會是誰用誰的呢 ? 但是可以肯定的是, 只要 User 有這樣需求的一天, User Interface Separation 的可能性就一直存在, 差別可能只在於會在哪出現, 是在 OS 上, 還是會率先在 Web Applications 上出現呢 ?
這下好了, 用 Linux 的人在用 Windows 的 Desktop, 用 Windows 的人改用 Mac 的 Desktop, 下一個會是誰用誰的呢 ? 但是可以肯定的是, 只要 User 有這樣需求的一天, User Interface Separation 的可能性就一直存在, 差別可能只在於會在哪出現, 是在 OS 上, 還是會率先在 Web Applications 上出現呢 ?
References
[1] Dave Collins, Designing Object-Oriented User Interfaces, Addison-Wesley, 1995
[2] Theo Mandel, The Elements of User Interface Design, Wiley, 1997.
[3] John Bennett, "User-Oriented Graphics Systems for Decision Support in Unstructured Tasks," ACM SIGGRAPH, 1977
[4] John Bennett, "Analysis and Design of the User Interface for Decision Support Systems," In Building Decision Support Systems, Addison-Wesley, 1983
Who Should be Responsible for the Installation Burden and Risks ?
其實我只是想換個 theme 罷了.
基本上我這個人對於 Desktop Operating System 越來越沒有特定的信仰. 以前無知時只用 Windows, 後來還是有點無知時只用 Desktop Linux, 再後來雖然還是蠻無知的, 不過變成了看心情跟需要, 一陣子用 Windows, 一陣子就改用 Desktop Linux. 昨天剛剛換成了 Mandriva 2008, 好一陣子沒用, 之前是用 Ubuntu. 但是可能因為 KDE 版本有差, 之前沿用的 theme 讓 menu bar 出現了問題, 所有的 icons 跟 quick links 都不見了, 變成空白一條. 弄了幾下調不回來, 索性整個 KDE 相關的設定都重來吧, 反正只是調整幾個地方.
上 KDE-look 找了個看起來不錯的 theme : Domino style engine, 想說裝裝看, 結果到我可以 make 為止, 總共遇到了以下的問題 :
- 缺少 C++ Preprocessor
- 缺少 libX11 development package
- 缺少 libxext
- 缺少 libz
- 缺少 Qt-devel
- 缺少 KDE headers
configure: error: C++ preprocessor "/lib/cpp" fails sanity check
在Mandriva 2008 中, 根據 package manager 的分類, 利用 gcc 關鍵字可以查到的有四個主要的 packages, gcc, gcc-c++, gcc-cpp, gcc-gfortan, libgcc1. 如果只知道要裝 gcc 是不夠的, 因為這裡的 gcc 是指 GNU Compiler Collection, 包含的是 GNU 的各個 compilers 會需要的基本元件, 而各種 programming languages 的 compiler 在架構上是分開的, 也就是還需要裝 gcc-c++ 在這裡才能夠符合需要.
第四個問題的訊息是這樣的 :
checking for libz... configure: error: not found.
Possibly configure picks up an outdated version
installed by XFree86. Remove it from your system.
這個 libz 又是甚麼呢 ? 而且他的提示訊息居然還建議我移除可能的安裝 !? 查了許久才確定應該是 libz.so.1 這個 library, 隸屬於 zlib package, 而且他需要的是 zlib-devel package.
我不想討論這些 installation burden 跟 risks 的問題, 這已經被討論到爛了, 從六年前 Desktop Linux 看起來開始可以讓一般使用者接受時, 到現在一直還是存在這問題.
基本上我覺得這是短時間不可能消失的問題, 應該要被討論的是, 誰應該對這個問題負責任 ? Who Should be Responsible for the Installation Burden and Risks ?
是使用者自己嗎 ? 這樣 Desktop Linux 又變為只有 hacker 可以用的系統. 使用者說, 我只是想換個 theme 阿, 為什麼看起來不相干的準備工作這麼多, 這些動作到底在做甚麼, 為什麼這些不是給我 software 的 developer 處理好.
是 software developer 嗎 ? developer 會說, 我哪管得了那麼多, 那根本是在我的 software 之外阿, 我哪知道不同的 distro. 會預設哪些 library, 哪有美國時間每個 distro. 都去測試, 況且沒幾天就有一個新的 distro. 誕生. 這問題還是丟給 distro. 公司以及 community 解決吧.
是 Desktop Linux distro. 嗎 ? 製作 Linux distro. 的公司說, 奇怪了, 使用者又要可以選擇自由安裝的 flexibility, 又抱怨不知道該裝哪些, 我對於每個 package 的說明不是都寫的很清楚了, 我怎麼可能知道使用者會裝哪些我預期外的 software, 又怎麼可能幫該 software 決定要抓哪些 library 來裝, 這是 developer 的事情阿.
當大家都把責任往外推的時候, 其實就是建立標準的時候了. 這不是個不能解決的問題, 只是沒有任何一方想要擔負這個責任, 因為很麻煩. 之所以麻煩就是因為缺乏標準. 如果可以有一個標準讓所有人去遵循, 結果可能就會出現像 UPnP 的東西, 大家遵照該標準做事就 OK 了.
附帶一提, 結果我還是沒辦法把該 theme 裝起來, 因為 make 後還是出現了看不懂的 compilation error, 這又要誰來解決 ?
UMLSpeed : a C-style light weight UML edition, layout tool
UMLSpeed 是一個 light weight 的 UML edition 以及 layout tool, 以 text-based 方式撰寫 UML-based design, 同時 UMLSpeed 則幫忙產生 SVG UML graphical layout, 以及支援轉換成 XMI 輸出, 或是其他 programming language 的 code generation.
UMLSpeed 作者之所以開發的理由包含 : (引用修改自 UMLSpeed 網頁)
- Graphical UML tools in general suck - why should we, as programmers have to drag and drop stupid graphical things and use a mouse when we could express what we want 10 times faster with a text editor and a simple notation?
- A declarative approach is closer to the mental model used by developers when designing systems.
- Why should we layout diagram components when the computer could do it for us?
- Graphical UML tools are bloated, huge, memory and disk-hogging monsters.
- Graphical UML tools use either a binary data format or XML, which is not particularly friendly to source code control systems.
以第 3 點來說, 雖然說 layout 不可能完全由 computer 取代, 身為吹毛求疵的 designer, 就算 tool 能夠自動幫我做 layout, 八成還是會對結果動手動腳的. 但是基本上 layout 結果的好壞是可以用一些 graph complexity metrics 去評量好壞的, 因此自動產生的結果是可以趨近 designer 會感到滿意的結果, 因而還是可以省下不少功夫, 更別說可以根據 designer 的喜好產生專用的 layout style. 第 4 點的問題應該常用許多 IDE 的 designer 都有相同的感覺吧, 有時候想要功能比較強, visualization 比較好看的 IDE, 卻會有需要大量 resource 的問題. 而 light weight 的 tool 往往功能上就比較被侷限住. 不過這基本上是個很難兩全其美的問題. 唯一的 solution 可能是能夠有一個 easy-customizable 的 IDE, 使得在不同的 environment 下可以很容易作 customization, 得到最需要的功能就好. (不過至今沒有這樣的 IDE 出現, 連 Eclipse 也還做不到)
同樣地對於第 1 點來說, grphical editor 在 visualization 上有他的優勢在, 我相信 graphical software design 只是還沒有突破性的發展, 但是 visualization 在 software design 上至少可以同時結合 design layout 與 design document (design code) 之間的 traceability, 但是像 UMLSpeed 這樣的 tool 就沒有支援這樣的 traceability, 只是因為 UMLSpeed 功能不強大, 所以這樣的缺點也就沒有被放大. 第 5 點也是見仁見智的問題, 採用 XML-based solution 是為了標準化以及延伸性考量, 如果不考慮此點當然可以批評採用 XML 的做法. 但是相對來說, 採用自家標準的 tools 往往容易被淘汰, 至少我就不太會想用, 因為 data 無法被不同的 tools 共用, 換句話說無法被長久保存, 這是很困擾的事情. 要是 UMLSpeed 沒有支援 SVG 或是 XMI 輸出, 我大概也不會想用了.
UMLSpeed 的使用是以 C-style 的 text-based code "programming" 展開, 看圖就很清楚了, (下圖取用自 UMLSpeed 網站 )
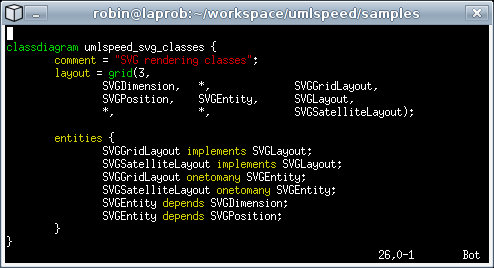
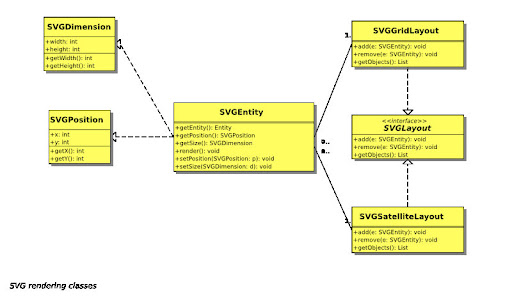 而輸出是以 SVG 格式的檔案輸出, 另外支援 XMI UML 文件輸出. 另外從網站上看來, UMLSpeed 目前支援 use case diagram, class diagram, sequential diagram, 以及 deployment diagram.
而輸出是以 SVG 格式的檔案輸出, 另外支援 XMI UML 文件輸出. 另外從網站上看來, UMLSpeed 目前支援 use case diagram, class diagram, sequential diagram, 以及 deployment diagram.基於 UMLSpeed 的特性, 我認為有幾個不錯的額外用途 :
- Software project 階段性的 design review, code review : 在 software project 進行過程中, 偶爾會需要進行 design review 或是 code review. 這通常是由於 design 或是 source code 已經有點混亂, 因此該部分的 leader 會召開會議, 把所有負責各部分的 designer / programmer 集合起來, 針對整個 design / source code 作 review, 確認每個部分的用途, 以及解決方法是否足夠好. 由於會議人數眾多, 同時進行會議中可無法容忍慢吞吞的大型 IDE, 或是時不時出現的 IDE 怪問題. 因此像是 UMLSpeed 這樣能夠快速進行 pure text-based modification 以及自動 layout 的 tool 應該適合使用. 但是要達成此點, UMLSpeed 跟其他 project 會用到的主流 IDE 之間的 data consistency 問題可能需要被解決.
- Design on mobile devices : 可能會想要這樣功能的人很少, 但是我就是其中之一 :p . 在 mobile devices 上, 或是如最近的 ASUS EeePC 上要跑平常的 IDE 幾乎是不可能的(很辛苦), 但是畢竟我想要的只是在等人或是喝個咖啡時, 可以思索一下最近手上計畫的 software architecture 的一小部分 design 而已, 一個 light weight, 可以馬上產生圖的 tool 就足夠使用了. 這些需求 UMLSpeed 看起來通通符合 :)
- UML programming on Wiki, Blog System : 我們實驗室使用的是 MoinMoin Wiki System, 偶爾會想在 Wiki 上畫個 UML 圖形來說明. 在 MoinMoin 上已經有類似的 plug-ins, 使用上跟 UMLSpeed 有點像, 只需要撰寫特定格式的 UML code, 就可以在頁面上被轉換成為 UML graph. UMLSpeed 應該可以提供在 Wiki 或是 Blog System 上的類似支援
reJ : what kind of bytecode inspection tool do you actually need ?
雖然我是個平常用不到 bytecode inspection tool 的人, 不過今天因緣際會看到 reJ 這個 tool, 起了一點想法.
我們對於什麼東西都可以用 5W1H, who, when, why, what, where, how 來嘗試弄清該東西的本質, 而我就想問了, what kind of bytecode inspection tool do you actually need ? 以及 who else also need this tool ?
reJ 這樣說了,
There are various robust libraries/APIs available for bytecode manipulation, such as:
- BCEL - http://jakarta.apache.org/bcel/
- ASM - http://asm.objectweb.org/
- Serp - http://serp.sourceforge.net/
關鍵句子出現了, "serve the needs of the user interface".
現在已經有很多強大的 bytecode manipulation library 出現, 尤其是 BCEL 跟 ASM, 基本上最近幾年在比較好的 software engineering conference / journal 上看到關於需要處理 bytecode 的 paper 都脫不了使用這兩個 tools. 在品質上顯然是受到信賴的.
然而 bytecode manipulation 終究只是技術的問題. 怎樣從 bytecode data 中挖出 information 並不該是身為 programmer 的我們需要花費最多關注的問題, 畢竟這是個一定可以被解決的問題. 我們更應該關注的是怎樣更有效率地挖出有意義的 information, 或者換句話說, bytecode inspection tool 要該要呈現什麼樣的 user interface 給 programmer, 才能夠讓 bytecode inspection 的動作有意義且有效率. 我相信 reJ 的那段話就是在嘗試說明此點.
User interface 在這裡並不單純指 software GUI 而已, 而是包含了 programmer 跟 bytecode inspection tool 之間的各種 operating languages. 透過 user interface 的設計, bytecode inspection tool 可以知道 programmer 真正想要的 information, 並且將之呈現給 programmer.
從 reJ 的 screeshots 可以看到這種努力, 雖然目前支援的 views 還很少, 但是這是以 service 的觀點來製作 bytecode inspection tool, 嘗試把 programmer 真正想要用的 views 帶進 software. (這不就是 service-oriented computing ?) 底下 screeshots 取自 reJ @ SourceForge.net.
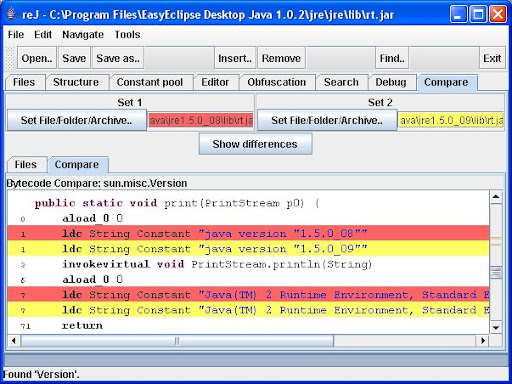
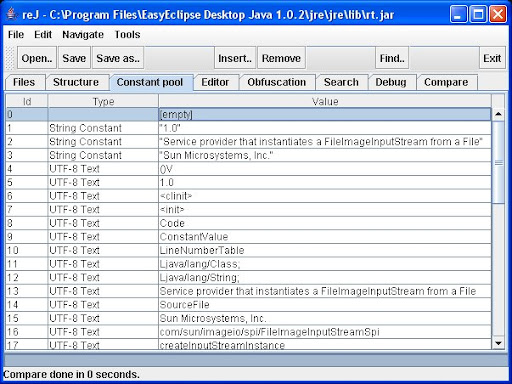 也有其他的 tool 有類似的想法, 例如 jclasslib, 可以看到的 information 更多, 但是過多的 information 卻沒有整理成適當的 views, 一樣對於 programmer 來說是種困擾. 底下是 jclasslib 的一張 screeshot, 其他的 screeshots 可以在他的網站找到.
也有其他的 tool 有類似的想法, 例如 jclasslib, 可以看到的 information 更多, 但是過多的 information 卻沒有整理成適當的 views, 一樣對於 programmer 來說是種困擾. 底下是 jclasslib 的一張 screeshot, 其他的 screeshots 可以在他的網站找到.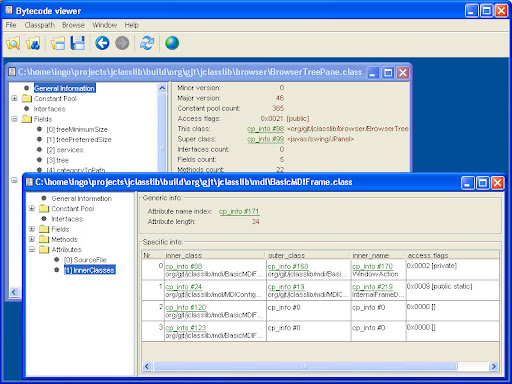
Reusing Source Code Document Generator as Program Parser
之前在對於某個 software measurement 想法進行 prototyping 時, 因為短時間內需要建立數個不同 programming languages 的 parsers, 同時還要能容易取得 parsing results, 因此很傷腦筋. 雖然已經有類似 ANTLR 的 parser generator, 但是寫 grammar file 還是很麻煩的一件事, 而別人已經寫好的 grammar file 能支援的 programming languages 也有限, 有些是尚沒有最新版本的 grammar files, 有些則是要自己寫. 而就算寫出來, 通常 parser generator 也不會特別幫你設計 parsing information 存取的 interface, 還是需要手動去 parser 裡面作一些修改, 一整個麻煩.
因為想偷懶, 結果就把腦筋動到支援較多 programming language 的 source code document generator 上, 例如 Doxygen.
Source code document generator 本身就一定會有 parsing 的功能, 但是要把這塊 component 挖出來也不容易, 畢竟人家本來就不是 design for reuse. 所以就採取折衷的辦法, 利用 document generator 能夠產生 HTML 或是 XML 等 formatted document 的特性, 再寫一個 XML parser 去讀取需要的 parsing information 就好. 寫 XML parsing 就簡單多了, 基本上就是在樹上繞來繞去而已. 整個流程像這樣 :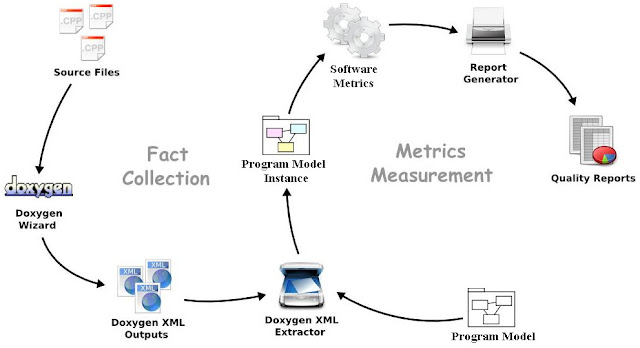
這樣在 Fact Collection 的 phase 幾乎不用作什麼事情了, 而同時 Doxygen 對於不同 programming language 的 parsing results, 用 XML 存的話, naming 都還蠻一致的, 所以所建立的 Doxygen XML Extractor 幾乎不用作太多的修改就可以不斷地 adapt 到不同的 programming languages 身上.
剩下的是在 Metrics Measurement phase, 把從 Doxygen 得到的 parsing information 塞到自訂的 program model 上, 然後利用特定的 software metrics 進行 measurement 就得到 program quality report 了.
在 development effort 上大大地省下許多功夫, 也能滿足 prototyping 的目的. 不過相對來說, 付出的 performance 代價是十分地恐怖, 恐怖到我一點也不想去比較真正的 parser 跟這個作法的 performance, 至少差了幾千倍吧. Performance 的 bottleneck 在於兩個地方, 一個是 Doxygen 要建立 document, 因此需要不斷地 cross-reference code entities, 另外一個則是 Doxygen 與 Doxygen XML Extractor 對於 document file 的 I/O. 對於程式碼很大且複雜的 software 來說, 例如 GCC, 可能要跑個幾天才會出來結果 (我用還蠻不錯的 PC machine 是跑了兩天多才出來).
所以基本上呢, 這種做法就只適合 prototyping 用吧, 另外就是需要不計較執行時花的時間, 唯一省下的好處是要寫 parser 或是 grammar file 的時間 :p
在 wikipedia 上有其他 source code document generator 的比較列表, 其他 document generator 應該也是可以取代 Doxygen 位置, 只要輸出的格式是 formatted document 就沒問題.
WebST : visualizing the Website STructure
WebST 是一個會根據你給定的 webpage 自動進行連結頁面 retrieval, 建立 star structure visualization 的 Java-based tool, 但很可惜地在 1.0 出現之後就沒有繼續發展了. 前一陣子有在 SourceForge.net 上作過 survey, 好像這類的 open source tools 並不多, 或是可能因為我不知道該用什麼關鍵字去找的關係 ?
WebST 執行的方式很簡單, 就是一般的 .jar 執行方式. 首先會出現輸入目標網頁的對話視窗, 但是這裡要注意前面不用加 http:// , 另外結尾要指定特定的網頁, 例如 index.htm , 而不能夠只有網域名稱. 舉例來說要看成大電機中文網站的結構, 要輸入 www.ee.ncku.edu.tw/chinese/index.htm , 而不能夠只輸入 www.ee.ncku.edu.tw/
輸入後就會進入主視窗. WebST 的 retrieval 動作還蠻快的, 這可能跟他不是一次抓完整個網站有關. 主視窗左邊是網頁預覽, 右邊是 star structure visualization. 上方有幾個不同的選項可以調整. 底下說明的 nodes, edges, radius 都是 Graph Theory 內的東西, 當然 Google 上很容易找到 definition.
- Show E# : 除了目前所選擇為 focus 的網頁 node 之外, 其他具有大於 E# 個 edges 的 nodes 不會呈現出來
- Expand E# : 除了目前所選擇為 focus 的網頁 node 之外, 其他具有大於 E# 個 edges 的 nodes 不會被展開
- Radius : 目前所選擇為 focus 的網頁在 radius 個 edges 內, 所以可連結到的所有頁面 nodes 都會被呈現出來. 簡單地說, 從目前 focus 的網頁出發, 經過 radius 次的網頁超連結切換, 所可以到達的網頁都會被列出來到 star structure visualization 中.
- Show BlackLinks : 把與目前選擇為 focus 的網頁之間有 backlink 關係 (其他網頁連結回目前的選擇網頁) 的網頁列出, 但是我有點懷疑這個功能有點小 bug.
- Zoom : 調整視野大小, 達到放大縮小的功能
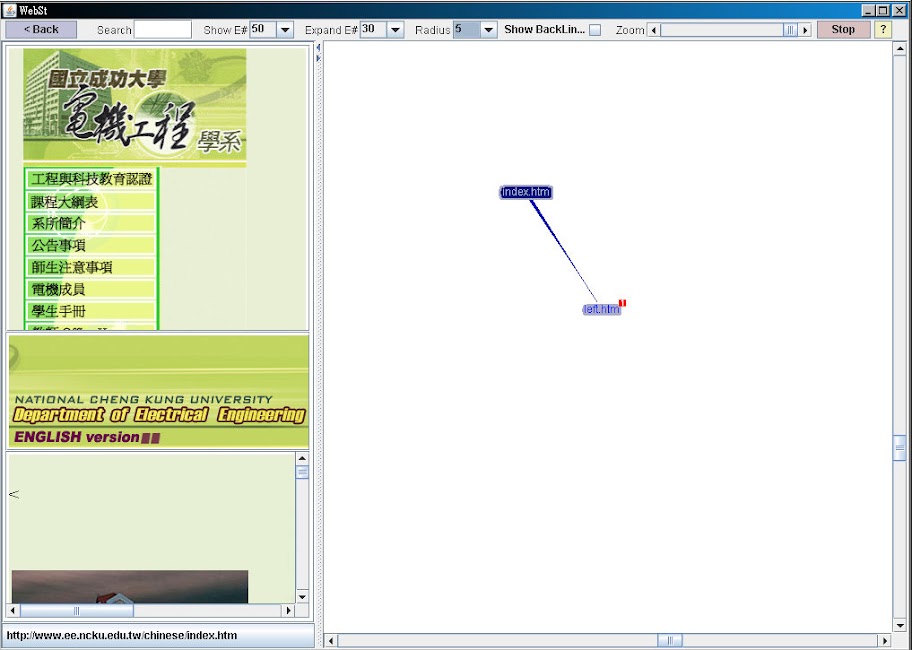 可以看到上面的圖雖然跑出來了, 但是似乎不太正確, 成大電機系網站不會只有這兩個頁面吧, 就算再調其他參數也是一樣的結果.
可以看到上面的圖雖然跑出來了, 但是似乎不太正確, 成大電機系網站不會只有這兩個頁面吧, 就算再調其他參數也是一樣的結果.這是因為 WebST 的 MyParserCallback class 只有對 Frame Tag 作處理, 而電機系網頁用了 Map Tag 而非 Frame Tag 去連結其他頁面, 因此 WebST 就無法解讀相關的 links. 同時對於 links 的路徑判斷很單純, 沒有考慮原始網頁開發人員將絕對及相對路徑混用的情況.
剛好 WebST 有把 source 提供, 因此我就去作了一點 hacking, 讓 WebST 可以處理 Map Tag, 同時可以在一開始指定要 retrieval 的 level 深度. 我改過的 WebST 可以在這裡下載 (要處理 Map Tag 才需要, 正常的網站應該是可以用原版的就好). 除了 MyParserCallback class 之外其實還要改其他地方, 有興趣的人就自己利用 decompiler 比較差異摟.
執行的方式相同, 只是一開始輸入的除了網頁 URL 之外, 還多了 level 的指定. 同時就這樣就可以正常地看到成大電機系中文網頁的星狀結構了.
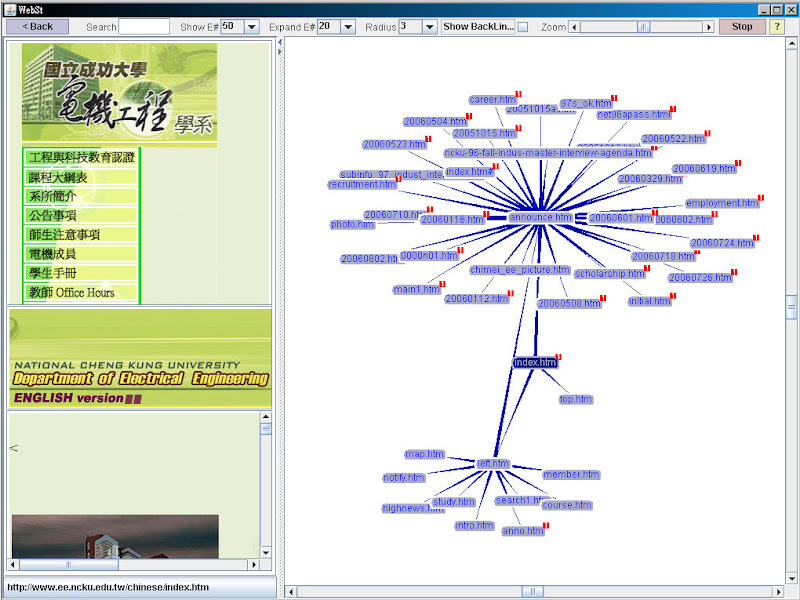 雖然說 WebST 的介面設計實在有點陽春, 同時功能也只有 visualization, 不過因為我還蠻喜歡串聯小 tool 使用的, 同時 free software 中也找不到相似的 tools 了 (另外一個類似的 WebLoupe 對於過大網站的 visualization 會有問題), 所以基本上 WebST 還是算堪用. 再不然就需要自己 parse 再接 graph library 了, 這樣可用的 library 倒是很多.
雖然說 WebST 的介面設計實在有點陽春, 同時功能也只有 visualization, 不過因為我還蠻喜歡串聯小 tool 使用的, 同時 free software 中也找不到相似的 tools 了 (另外一個類似的 WebLoupe 對於過大網站的 visualization 會有問題), 所以基本上 WebST 還是算堪用. 再不然就需要自己 parse 再接 graph library 了, 這樣可用的 library 倒是很多.不負責任的推測, WebST 應該是大學生的修課作業之類的. 因為在 WebST 網站上有一個 Business Plan 的 pdf 檔案, 雖然內容看不懂, 但是有點像是大學部或研究所的 project document, 加上 WebST 本身也像是一個 project 作業, 然後完成後就沒有繼續 maintain 了, 一整個很像是課程 final project ^^b
{kind=link}
MyHeritage 人臉辨識
MyHeritage 是一個可以讓你利用人像照片建立 family tree 的 web service, 以及可以利用照片比對不同 family tree 之間長的相似的人, 藉此建立關係. 其原始想法應該是啟自 Geni 這個始祖的 service, 但是結合了人臉辨識的想法. 雖然說長的有點像跟血緣關係之間我覺得是沒有直接的邏輯關係啦 = = , 或者說至少目前的人臉比對技術還沒有到那種程度吧. 所以還是當作建 family tree 的 service 外加 for fun 的人臉辨識就好.
既然是 for fun, 當然要試一下. 以找出同一個人為驗證的標準, 首先用了手邊的一張近期廣末涼子的正面照片去作比對, 結果在第四相似照片有找到, 相似度是 90% 左右. 這邊也可以看出跟髮型, 髮色無關. 另外挑選出的照片除了第三張不知道是哪位韓國人, 其他的從眉毛, 眼睛以及笑的嘴型可以看出一些相似度. 再試了一張跟早期短髮時期比較像的. 這次第一相似就找到了. 應該也是五官影響大一點. 第六張的 Camilla Belle 那張照片好醜, 本人是很漂亮的, 在去年上映的重拍電影 When a Stranger Calls 有獨挑大樑的演出.
再試了一張跟早期短髮時期比較像的. 這次第一相似就找到了. 應該也是五官影響大一點. 第六張的 Camilla Belle 那張照片好醜, 本人是很漂亮的, 在去年上映的重拍電影 When a Stranger Calls 有獨挑大樑的演出.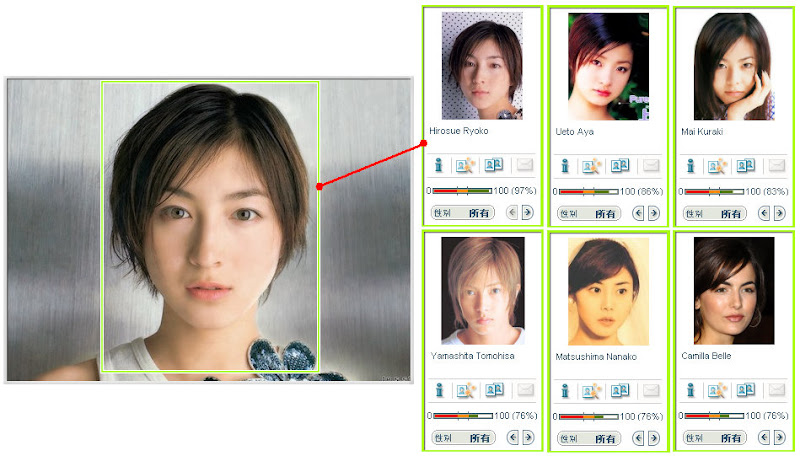
如果用角度稍微偏的, 例如 25 度左右側臉的, 或是臉部有往左右旋轉一個角度的, 出來的結果就比較不準, 這應該跟 image base 裡面的既有 images 有關. 下面兩個嘗試都是完全沒找到. 從下面的第一個嘗試可以看出來側臉會被考慮進去, 換句話說輪廓形狀也是進行比對的因素之一, 所以找出來的都是側臉的. 第二個嘗試應該還是跟五官比對的關係度大一點, 不過第五張出現的蔡某人就不知道是怎麼一回事了, 感覺上跟其他的照片在五官表現上的差異度蠻大的.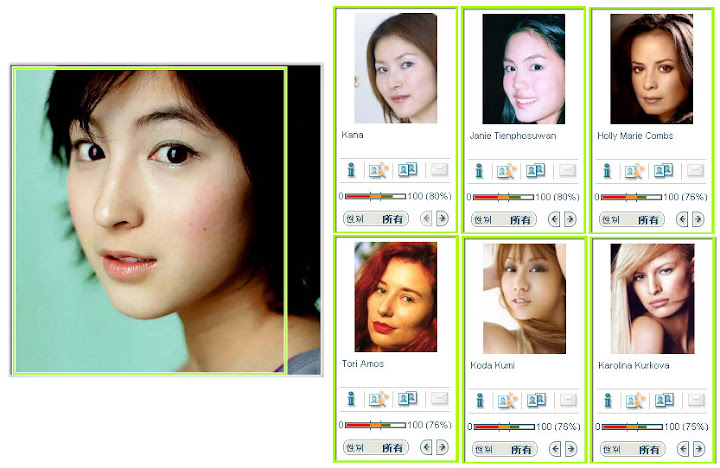
 最後比較一下一樣的照片用彩色的跟灰階的兩種去比對, 結果是否會相似 ? 就拿第二張的最高相似度來嘗試, 結果前半段的相似度是一樣的, 但是後面就有些變化. 所以色調應該也是有些影響, 但是主要特徵的辨識應該可以說是不太受色調的影響.
最後比較一下一樣的照片用彩色的跟灰階的兩種去比對, 結果是否會相似 ? 就拿第二張的最高相似度來嘗試, 結果前半段的相似度是一樣的, 但是後面就有些變化. 所以色調應該也是有些影響, 但是主要特徵的辨識應該可以說是不太受色調的影響.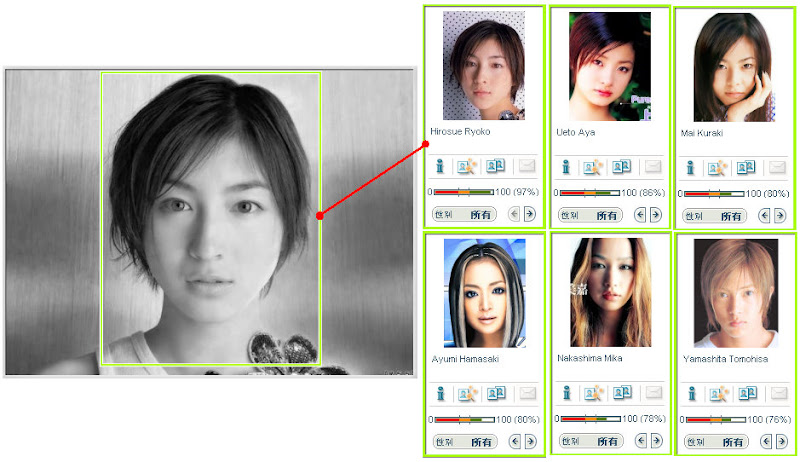
另外我也用了一樣是廣末涼子的素描畫像, 以及跟廣末涼子無關的一隻狗臉照片去嘗試, 結果發現會因為找不到特徵所以無法比對, 所以基本上這個 service 的檢查算是有考慮這些點, 會先判斷是否為系統可接受的人臉照片.
除了單人的比對, MyHeritage 也可以接受一張照片裡有多個人臉, 他會嘗試把每一個都辨認出來, 然後自 matching 到相似度高的人臉照片. 不過偶爾還是會找到奇怪的東西就是了, 像是下面這一張, 成功把狗臉踢掉了, 但是右方不該有臉的地方卻找到了臉.(還是說這裡真的有東西 ? 恐怖歐 ~~ )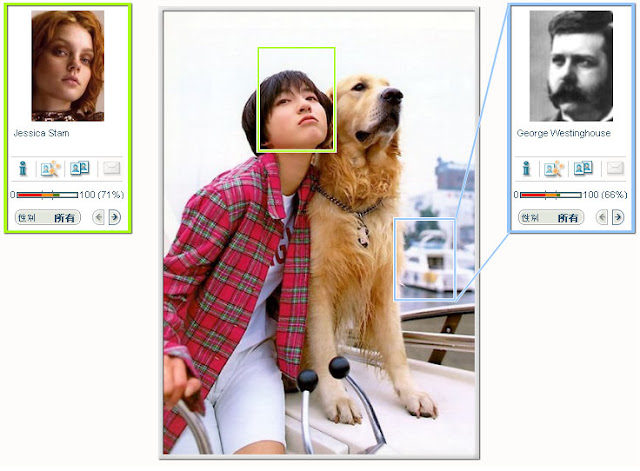
總地來說,我覺得除了選用的人臉特徵之外, 跟 image base 內有哪些 images 也有相當的關係. 另外上面的比對都是以找出同一個人為驗證的標準, 而不是以演算法得到的相似度, 否則難以從人眼看的觀點作平段.
另外談談黑暗面, 上面稍微有點不自然地出現了蔡某人的照片, 加上最近台灣唱片業的買排名黑箱事件, 很難不讓人聯想到這類應用的黑暗面. 畢竟這一類的應用也算是一種 Search Engine, 會不會同樣也可以利用買廣告的方式, 讓某些特定人士的臉孔比較容易在比對中出現, 進而達到特定的宣傳目的呢 ? 呵呵...
jlayout : Seperating the GUI Configuration from Java Code
jlayout 是一個可以把 GUI configuration 與 Java code 分開處理的 tool. 遵從 jlayout 的 annotation 以及 configuration 語法, 可以把原先 Java code 中一大串的 GUI code 部分以少量的 annotation 取代掉, 而在 configuration file 上是以對每個 object 獨立作 configuration 的方式, 指定 object 的 state, 以及 objects 之間的 association. 整體概念可以簡單用下圖說明.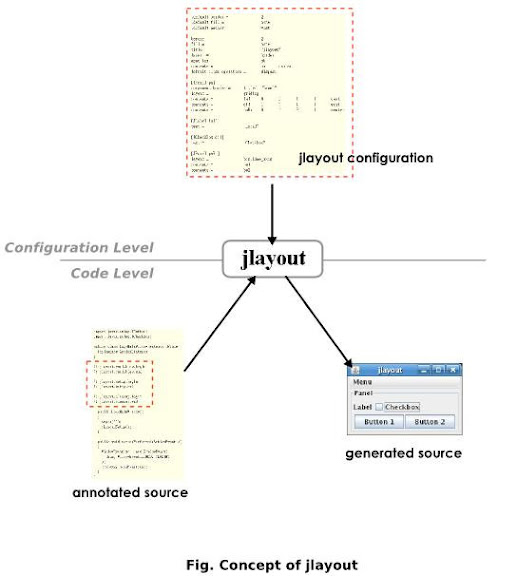
概念上跟 CSS 之類的有點相似, 但是 jlayout 沒有辦法支援長相一樣的 GUI objects 使用同樣的 configuration, 當然就更別說 styles 之間的 inheritance 關係.
從 configuration file 的長相可以看到其實 jlayout 在 code 跟 configuration file 之間還是有蠻強的 coupling. 需要依靠 object name 作為 configuration deployment 的依據, 也幾乎每一個 GUI object 都需要一個獨立的 configuration section.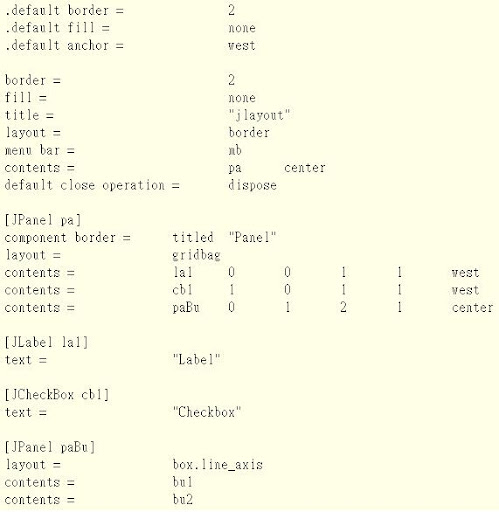
換句話說, jlayout 提供的好處其實只有可以縮短原先 Java code 內的繁雜長串 GUI 部分, 以及可以透過 text-based configuration 調整 GUI object 的 state, 以及 GUI objects 之間的 associations. 進行調整時, 因為許多 method call 的 code 被省略了, 因此可以用更簡潔一點的方式作調整.
TagSEA
TagSEA [2] 是好一陣子前看 ICSE paper [1] 時發現的 tool, 當時就覺得蠻有趣的, 不過好像中文網站還沒有太多的介紹. 作者群在 ICSE 的那篇 paper 是 tool demonstration short paper, 應該蠻容易看懂的. TagSEA 網站上也可以直接看的到.
如其名, TagSEA 的主要功能在於能夠讓你隨意在程式碼上加上各種 tags. 有些是 TagSEA 已經訂好的 common tags, 例如 TODO tag, 而你也可以自定習慣的 tags. Tag 的位置可以在程式碼上, 註解上, 或是空白的部分. 加上 tag 的方式可以採用手動以 Java comment 語法加上 @tag 標籤, 或是直接在要註解的地方按 mouse 右鍵, 從選單中加入 waypoint (TagSEA 稱呼在 source code 中被標上 tag 的 location 為 waypoint). 在 waypoint dialog 中可以再指定要創造新的 tag 或是採用既有的 tags. 更詳細的說明在 TagSEA 網站上有很多易懂的 examples. 值得注意的是用 @tag 標籤加上的稱為 parsed waypoint, 而利用選單加上的稱為 resource waypoint. 這在後面製作 presentation tour 時會有差別.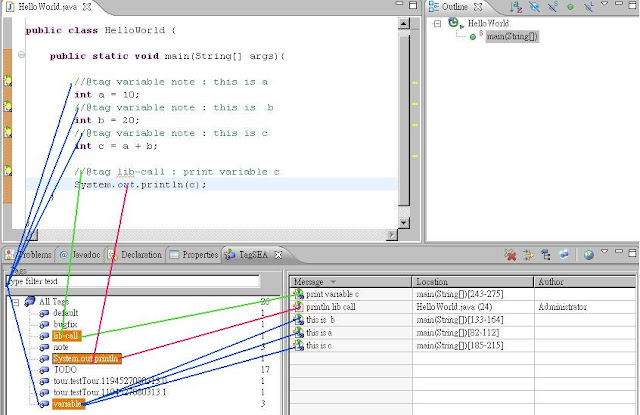
TagSEA 對於 waypoints 提供了 hierarchical tree view (上圖左下方), 以及有趣的 cloudsee view.
CloudSee view 雖然好像有些趕流行, 但是對於想一眼看出不同 tags 數量關係還蠻有用的, 況且 programming environment 內實在需要出現一些有趣點的東西, 可以紓解 debug 壓力 :p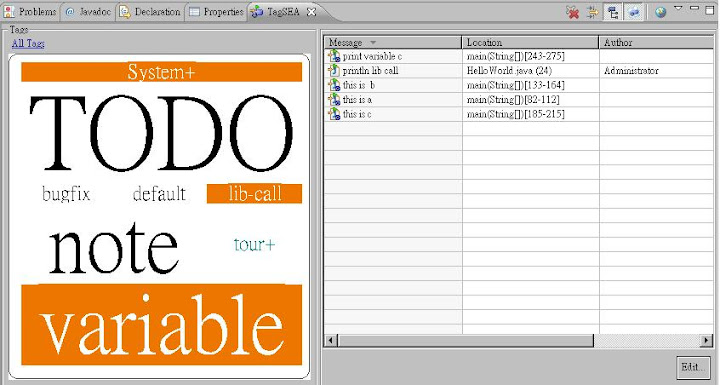
不過在右方的 tag message list 有點小 bug, 當新增 tag 時, tag message list 不會馬上更新, 需要等到再加一個新 tag, 或是 mouse 右鍵 tags -> show waypoints 才會更新.
TagSEA 內的 waypoint 應該是沿用自 GPS 系統的稱呼 [3], 可以想見 TagSEA 其實定位自己是 Eclipse 上的 GPS navigator 系統. 因此同樣地, 數個 waypoints 以特定順序串在一起就形成 route (同樣來自於 GPS 系統) [1], 而一長串的 route 其實就是一個 navigation tour.
TagSEA 也提供 Tour 的幫手功能 (但是需要 Eclipse 3.3 以上), 藉由 Tour 功能, 你可以快速地利用已經標好的 tags, 在 Eclipse 上建立一個簡單的 presentation (進行的步驟在 TagSEA 網站上寫的很清楚了). 只要執行編輯好的 Tour, 然後利用播放鍵就可以很順利地依照你的 plan 進行 presentation, 再也不用擔心 present 到一半卻忘了要開哪個檔案, 或是找不到要講的那段 code, 或是忘了本來要開的 view 是哪一個 -- 是的, Eclipse 上的 view 也可以作為建立 presentation tour 時的一的造訪點 (其他可以加的東西都在右側的 Tour Palette 上). 但是這裡要注意的是, 如果你要 Tour 自動根據 tag 換到該位置, 必須要是 resource waypoint 的 tag 才可以, 如果只是 parsed waypoint, 似乎 Tour 不會有反應.
執行後的 Tour 會在上方出現播放控制盤, 可以看到目前的位置, 也可以前後播放, 不過還沒有辦法直接跳躍到某個步驟. 可以看到當執行第一個步驟時, 畫面就自動切換到第一個 resource waypoint 所 tagging 的地點了.
可以看到當執行第一個步驟時, 畫面就自動切換到第一個 resource waypoint 所 tagging 的地點了.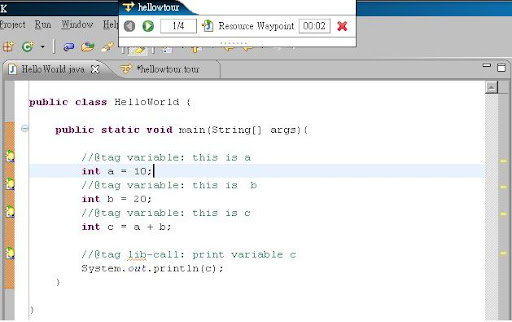
另外除了 Tour Palette 上可以加的東西, 以及 resource waypoint 之外, PowerPoint 之類的也可以加到 Tour 裡面, 我嘗試了 OpenOffice.org 系列, odt 檔案可以, 但是 odp 就會出現一些顯示的問題, 不過這些問題應該跟 TagSEA 無關, 是 Eclipse 本身的問題 (OpenOffice.org 會直接以 OLE 物件的方式開啟在 Eclipse 視窗內, 而 PowerPoint 會獨立開啟), 我也嘗試了 PDF, 但是會出錯, 根據錯誤訊息應該是我 local 端的設定問題. 換句話說只要你 local 端有相對支援開啟的 software, 應該都可以順利在 presentation 過程中開啟. 下面是開啟 odt 檔案的樣子.
從 tool 的角度來看, TagSEA 算是蠻小巧好用的 tool, 而我喜歡他的另外一點是, 從 research 的眼光來看, 這個小 tool 有相當大的潛力. 現在 TagSEA 只能在 code 上加 tag, 而別忘了 Eclipse platform 上的 plug-ins 幾乎快涵蓋了整個 model-driven software development, 雖然有些 plug-ins 還不算太成熟, 但是當 TagSEA 可以更順利地支援直接在 use case, object model, analysis model, architecture design, detail design 上加註 tag 時, 想想他將會有的 power, 給 software developer 提供的 traceability service 以及 consistency checking service, 還有很多可能的應用, 都可以建立在這一個看起來很簡單的 tool 身上去實現.
我想這是包含我在內的許多台灣研究學生, 經常忽略的一點, 在我們手上的許多小想法因為他們簡單, 所以擁有更大的發展空間, 老想著重新作出全新的東西, 會讓我們的研究工作前進的十分緩慢. 好好地利用已經有的東西, 往上堆積新的價值, 才是一直以來研究該有的方式.
References
[1] L. Cheng, M. Desmond, and M.-A. Storey, "Presentations by Programmers for Programmers," In Proceedings of the 29th international Conference on Software Engineering, pp.788-792, 2007
[2] TagSEA, URL : http://tagsea.sourceforge.net/
[3] waypoint @ Webster's dictionary, URL : http://www.websters-online-dictionary.org/definition/waypoint
Multimedia Analysis and Retrieval System (MARS)
最近因為 lab group meeting 的關係看了一篇平常大概不會特意去看的 paper : Supporting Ranked Boolean Similarity Queries in MARS [1].
這是 98 年的 paper 了, 內容主要是提出一個改進的 boolean retrieval model, 以產生 ranked retrieval results. 而應用在 multimedia analysis and retrieval system (MARS) 上, 不過 paper 內只有提到 image, 沒有 film 之類的, 估計是因為差別在於所選擇的 features 而已.
這篇 paper 有幾個值得深入討論的地方, 首先, 雖然他是 10 年前的 paper 了, 但是在當時他所使用的 query 就不只是利用 text-based 方式在描述 image 的 features 了. 他是用一組 images, 稱為 set I 好了, 裡面的 iamges I1, I2, I3... 分別用來表示一組 features, 稱為 set F 好了, 裡面的 features F1, F2, F3...., 換句話說, 是利用多個 images, 各取你覺得有用的部分, 合起來去尋找你真正想要的 image.
很容易就想到白蘭氏的這個廣告.
這種想法在現在來說應該已經不新奇了(特別是對 CS domain 的人), 我在看 paper 的同時也去找了目前有提供相似功能的 product, 但是找到的 image retrieval softwares [2][3][4] 似乎都只支援 text-based features, 以及 single image retrieval, 而沒有 multiple image retrieval 的, 不知道是為什麼 ? 其中 CIRES 支援 signal image retrieval, 可以調三個 features, 可以線上使用, 只是搜尋要等一段時間. 另外可以看看據說是 T. S. Huang 的學生在網頁上所放上的, 他們實驗室作的 MARS 的 screenshots : 在這裡 [5]. 通常我們說 academy 的研究成果是領先 industry 大約 6 ~ 7 年的時間, 但是都過了 10 年了卻沒有相似的 product 出現, 這點實在有點奇怪.
另外當進行這一類搜尋時, 勢必須要從固定的 selected image base 中選定作為 features 的 images. 然而 selected image base 除了需要事先分類過以外, 其 size 也會對於整體 performance 造成很大的影響. 第一個影響是 user 需要花費多少 effort 去形成他的 query. 另外一個影響是所形成的 query 之準確度. 如果 selected image base 中的分類不夠好, 或是 size 太大, user 會需要花較多的時間形成 query, 同時準確度也不見得會比較好. 而 size 太小, 顯然地 query 就比較難準確, 得到的結果一定會比較差. 這之間的 trade-offs 不知道該如何衡量.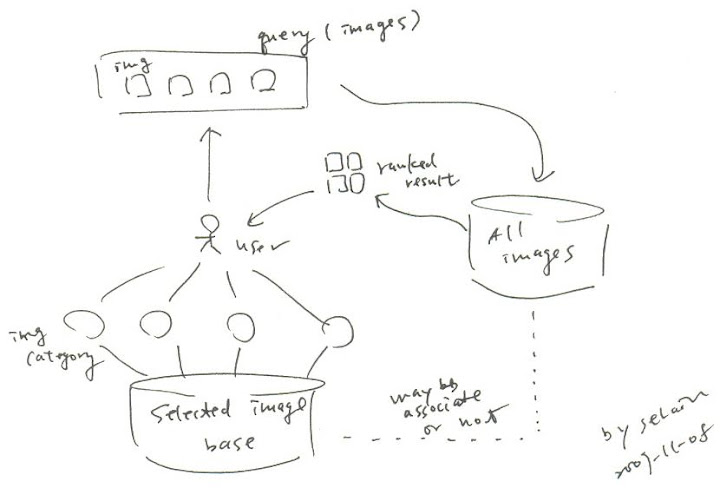
想像當我們到警察局要依照分類過的特徵照片拼湊犯人長相時, 如果需要看個一兩千張照片來拼湊一個 image set 作為 query, 應該會想扁警察吧. 但是如果只有一二十張, 我們一定又會覺得沒辦法選出想像中的 features, 結果當然也就不會好.
就 feature set F 來說, 其組成也是需要探討的地方. 通常 features 之間不會全然是 independent, 同時我們也不可能要求 user 要填寫三四十個 features 才能準確搜尋. 因此怎樣選擇可以造成最大區別度的 features 是另外一個問題. 在 paper 中選擇了 colors, texture, shape, color layout, 以及 textual annotation 作為 feature set. 然而我想實際上 feature set 的選擇可能會跟 image base 裡面究竟存哪些 images -- 換句話說目前應用的 context 是什麼有關係, 唯有考慮 context 的問題才有可能決定最有效率的 feature set.
另外 paper 內容有一點很有趣, 他使用了兩個 form 來表達 pseudo code, 一個是常見的 text-based pseudo code 形式, 另外一個是有點像流程圖的方塊形式 (我以前沒看過這樣畫的), 講的是同一個 algorithm, 但是兩個要表達的東西又各自有點不同, 所以你也不能批評他說是多餘的. 倒是 paper 內也沒有解釋為什麼需要特別用兩種方式表達就是了, 或許是因為整合起來會太複雜吧, 分開成兩個簡化的 view 效果一樣, 各自有各自的焦點在, 就跟 UML 需要分成好幾個 view 一樣. ( figure bellow is referred from [1])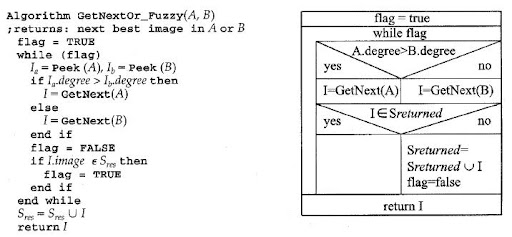
雖然跟我的 major domain 稍微有點距離, 很多 detail 也看不太懂, 但是從單純 information retrieval 的角度去思考, 以及想到 multimedia retrieval 應用的可能問題, 還是蠻有意思的一篇 paper.
References
[1] M. Ortega, Y. Rui, K. Chakrabarti, K. Porkaew, S. Mehrotra, and T. S. Huang, "Supporting ranked boolean similarity queries in mars," IEEE Transactions on Knowledge and Data Engineering, vol. 10, pp. 905-925, Nov/Dec 1998.
[2] CIRES, URL : http://cires.matthewriley.com/
[3] imgSeek, URL : http://www.imgseek.net/
[4] GIFT, URL : http://www.gnu.org/software/gift/
[5] MARS snapshot, URL : http://www.ifp.uiuc.edu/~qitian/MARS.html
從小型 maintenance 看服務供應商的能力與決心之別
Google Blogger 之前已經提醒過台灣時間今天下午 3:00 左右會暫停服務 10 分鐘左右, 估計是進行過必須重新啟動系統的 maintenance 工作. 相對來說, 所謂 "台灣網路創業成功案例" 的無名小站, 就我之前輾轉看到的公告, 似乎都需要停止服務接近一天以上 (而且還都選在假日, 加班有錢賺 ?), 從這種小事情就可以看到服務供應商的 maintenance 能力, 對於自身的定位, 以及對於市場競爭的覺悟.
Google Blogger 只停了 10 分鍾不代表 maintenance 工作只進行了 10 分鐘, 在此之前我認為可能長達三個工作天以上完成這個 maintenance 作業. 而經過事前審慎的規劃分析, 降低所有的 complexity, 得到的結論就是一個詳細的計畫, 以及最後需要 10 分鐘的暫時停止服務. 然而無名小站的整天停止服務就不知道是什麼原因會需要這麼久了.
Non-stopping applications 的議題在 academic 已經有二十多年以上的討論, CS 領域的研究人員很早以前就意識到 Non-stopping applications 在 maintenance 上必須要被克服的種種問題, 許多大學研究所的 fault tolerance 課程多少都有介紹到. 然而理論是一回事, 業界的公司在實行時還是需要考量到花費的 costs 問題. 大部分的一般性支援 non-stopping adaptation or maintenance 方法還是需要額外的 hardware/software redundancy, 這同時也是比較容易達成的方法.
我並不是在說沒有作到 Google Blogger 的 10 分鐘就是罪惡, 而是從這種小事情就可以看出服務供應商的能力與決心. 我自己也在管理一個平均上站人次在每日 200 ~ 300 人的小型系站 BBS, 偶爾我也必須暫停服務以更新軟硬體, 更別說當被攻擊或是硬體損壞時, 停個幾天的服務也是可能的. 由於經費以及我可用的時間限制, 我所能作到的最好結果就是這樣, 這也反映出我所 maintain 的這個 BBS 其目的以及定位就是只有給系上的學生使用, 我也沒有什麼市場競爭的考量. 當然我可以花更多的心思去爭取經費, 作到 non-stopping service, 但事實是, 我並不需要.
然而放到 business domain 來說, 作為 company manager 也好, project manager 也好, 你對於你的 product, 有著怎樣的 maintenance 能力, 有著怎樣的定位以及理想, 你用什麼樣的 strategy 去應付市場的競爭, 這些因素在在透過許多小事情會展現出來. 作為提供 product 以及 service 的人, 如果在這些小地方隨便應付, 恐怕休想你的 product 會有美好的將來. 而作為聰明的投資人或是使用者, 應該更需要從這些小地方應該就要開始判斷這個 product 的 reliability, 畢竟我們可不希望付出的時間成本就悄悄地埋葬在 awful manager 的手裡.
具備嶄新 User Interface 的新世代 Mobile PC : 我們還需要買 Hardware 嗎 ?
記得在五年前吧, 當時台北捷運剛剛落成不久, 恰好搭上城市無線網路以及寬頻資訊的夢想起飛, 於是在台北捷運內以及台北火車站就出現了兩個後來被證明沒什用的東西 [1]. 一個是捷運生活站, 一個是無線上網桌.
無線上網桌的立意是認為許多現代(當時)台北市民是帶著 Notebook 到處走的, 特別是上班族, 在捷運站內已經有提供無線網路的情況下, 當然會希望手上有 Notebook 的市民如需要收收信件之類的可以利用無線網路. 但是 Notebook 沒有乾淨平坦的地方可以放置, 在使用上是非常不便的. 當時我覺得立意還不錯, 只是看到設立的點少之又少, 不免覺得奇怪, 如果真的評估有此需要, 如此少的設點不會造成供不應求嗎 ?
當然後來的情況證明我錯了, 也顯示出事前的評估, 相關單位應該沒有認真作過調查, 只是提出個看起來覺得不錯, 但是實際上卻沒人要用的方案 (找了許久終於找到有人用的照片了: 看這篇文章). 捷運生活站也是一樣, 我還沒有看過有人用過 ^^b
現在好啦, 就在大家邊用各種 Mobile PC 邊抱怨畫面太小, 操作介面太小, 接鍵盤很不方便, 可攜帶曲捲式的軟鍵盤很難按...blahblah...終於 ! 首先, 我們有了這個 : (圖片來自於 forwarding email, 很抱歉我查了很久查不到出處)

 上面的是日本公司的產品, 但是記得幾年前看到的最初 prototype 是印度公司首先做出來的.
上面的是日本公司的產品, 但是記得幾年前看到的最初 prototype 是印度公司首先做出來的.
然後呢, 我們又有了這個 ( pictures are referred from here [2] ) :
 好吧, 雖然說我連他怎樣投射出影像來的都看不清楚, 但是我承認我還真想要這兩個東西...我相信應該很多人也會想要.
好吧, 雖然說我連他怎樣投射出影像來的都看不清楚, 但是我承認我還真想要這兩個東西...我相信應該很多人也會想要.
如果在不久的將來, 可能是一年內, 這些東西成功量產, 商品化了, 似乎人手一台的可能性也頗高. 這樣我們是不是也要針對這些應用建造公共設施呢 ? 畢竟投影的鍵盤也是需要略為平坦乾淨的平面阿, 畫面的投影也不是隨片找個花花的牆就可以, 如果我們再考慮到 privacy 呢 ? 會不會以後在捷運站看到把平常沒在用的臨時投票所拿出來擺在那裡給大家用, 有點像是公共廁所的公共電腦室 ^^b. 而...會有人用嗎 ?
而這些應用的另一個有趣的觀點是, 似乎電腦的硬體部分逐漸真正的 "embed" 到城市的硬體設施裡了, 而不再是大家需要隨身帶著走的東西. 以後我們待在身上的是屬於自己的 software, 以及 private data, 但是 hardware 卻是利用公共設施來作為 software 的載體, 大部分的 hardware 我們都可以不用再買了. 考慮到產業界會有的轉變, 這是個近在咫呎, 非常有意思的未來.
選擇 software 這條路, 的確是蘊藏著無限的可能 :)
References
[1] 慕容理深, "道具、玩具、證據," URL : http://blog.roodo.com/elysii/archives/3577609.html
[2]
NetJaxer : A Potential Platform for Web Service Composition Knowledge Sharing
NetJaxer [1] 是一個方便使用者搜尋以及使用既有的 web 2.0 application 的 tool, 可以想成是一個 software RSS reader (?) , 或是網路書籤的 client 版, 會自動匯集新的 web 2.0 applications, 並根據 application 的應用以及受歡迎程度作分類.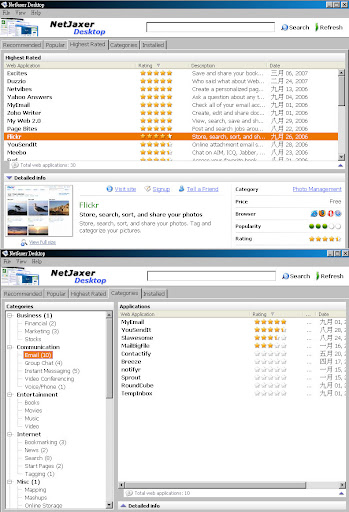
看看 NetJaxer 怎樣說明他自己 :
NetJaxer is a free and easy way to integrate your favorite Web 2.0 applications right into Windows. Now, they are always just a mouse click away. NetJaxer combines a categorized and searchable web directory of 100's of Web 2.0 sites that works hand and hand with a free small piece of software you download to your computer's desktop.
這裡面看到了幾個關鍵字, categorized, searchable, 以及 works hand and hand.
在今年稍早 Richard MacManus 寫的 NetJaxer - a Web/Desktop integration product… but is it useful? [2] 文中提到了他向 NetJaxer 的 development team 詢問一些未來發展的規劃, 從回答看來的確似乎還舉棋不定, 但是從目前 NetJaxer 的敘述看起來, 似乎也不全然是沒有方向, 至少那個 works hand and hand 就很引我注意了 :p
在 Ajaxian 上的一篇文章 [3] 也說到 :
Imagine dragging a document into a GMail icon or having desktop notification that your buddy just logged in to Campfire...
在前幾天我剛好也寫到 Software Bundles 的 knowledge 觀點, 如果 NetJaxer 不只是提供目前依據應用以及受歡迎程度作分類的推薦方式, 同時可以提供 有效率地串聯這些 applications 以滿足某特定目的 的使用方式呢 ? 那麼 NetJaxer 就不只是一個可以提供 categorized applications 以及 search applications 的 tool 了, 而是一個 application composition utilization knowledge sharing platform 了. (應用軟體整合知識分享平臺--什麼跟什麼阿)
更甚而, 如果不要把 application 當作最小單位, 而是再把 application 拆解成為數個 services, 那麼實際上進行的其實是對於 web services 的串聯以及分享, 也就是 web services composition utilization knowledge sharing -- 越來越長了.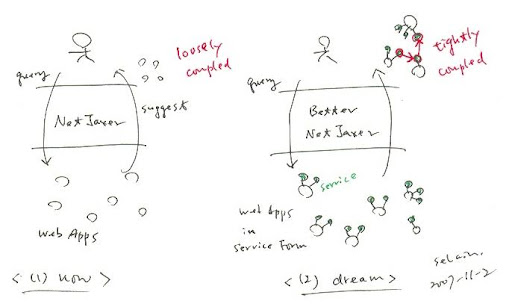
總之, 我只是想說 NetJaxer 是個蠻有趣具有潛力的 tool. 不過 service-oriented computing 相關研究最近幾年才開始快速展開, 對於 service selection 以及 composition 的議題都還在研究中, 加上目前的 web applications 所形成的 services 概念跟形式都與早期的 web services 有些不同, 不知道 NetJaxer 能夠利用多少具體的成果就是了.
References
[1] NetJaxer, URL : http://www.netjaxer.com/
[2] Richard MacManus, "NetJaxer - a Web/Desktop integration product… but is it useful?" URL : http://blogs.zdnet.com/web2explorer/?p=147
[3] Michael Mahemoff, "NetJaxer: Web-Desktop Integration," URL : http://ajaxian.com/archives/netjaxer-web-desktop-integration