
Multimedia Analysis and Retrieval System (MARS)
最近因為 lab group meeting 的關係看了一篇平常大概不會特意去看的 paper : Supporting Ranked Boolean Similarity Queries in MARS [1].
這是 98 年的 paper 了, 內容主要是提出一個改進的 boolean retrieval model, 以產生 ranked retrieval results. 而應用在 multimedia analysis and retrieval system (MARS) 上, 不過 paper 內只有提到 image, 沒有 film 之類的, 估計是因為差別在於所選擇的 features 而已.
這篇 paper 有幾個值得深入討論的地方, 首先, 雖然他是 10 年前的 paper 了, 但是在當時他所使用的 query 就不只是利用 text-based 方式在描述 image 的 features 了. 他是用一組 images, 稱為 set I 好了, 裡面的 iamges I1, I2, I3... 分別用來表示一組 features, 稱為 set F 好了, 裡面的 features F1, F2, F3...., 換句話說, 是利用多個 images, 各取你覺得有用的部分, 合起來去尋找你真正想要的 image.
很容易就想到白蘭氏的這個廣告.
這種想法在現在來說應該已經不新奇了(特別是對 CS domain 的人), 我在看 paper 的同時也去找了目前有提供相似功能的 product, 但是找到的 image retrieval softwares [2][3][4] 似乎都只支援 text-based features, 以及 single image retrieval, 而沒有 multiple image retrieval 的, 不知道是為什麼 ? 其中 CIRES 支援 signal image retrieval, 可以調三個 features, 可以線上使用, 只是搜尋要等一段時間. 另外可以看看據說是 T. S. Huang 的學生在網頁上所放上的, 他們實驗室作的 MARS 的 screenshots : 在這裡 [5]. 通常我們說 academy 的研究成果是領先 industry 大約 6 ~ 7 年的時間, 但是都過了 10 年了卻沒有相似的 product 出現, 這點實在有點奇怪.
另外當進行這一類搜尋時, 勢必須要從固定的 selected image base 中選定作為 features 的 images. 然而 selected image base 除了需要事先分類過以外, 其 size 也會對於整體 performance 造成很大的影響. 第一個影響是 user 需要花費多少 effort 去形成他的 query. 另外一個影響是所形成的 query 之準確度. 如果 selected image base 中的分類不夠好, 或是 size 太大, user 會需要花較多的時間形成 query, 同時準確度也不見得會比較好. 而 size 太小, 顯然地 query 就比較難準確, 得到的結果一定會比較差. 這之間的 trade-offs 不知道該如何衡量.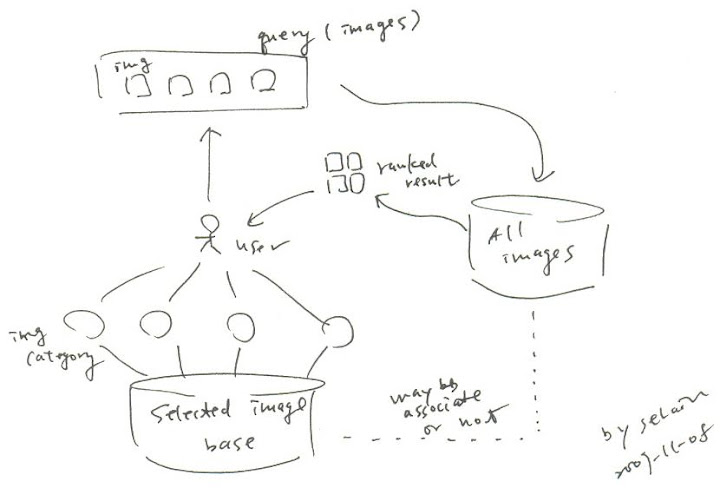
想像當我們到警察局要依照分類過的特徵照片拼湊犯人長相時, 如果需要看個一兩千張照片來拼湊一個 image set 作為 query, 應該會想扁警察吧. 但是如果只有一二十張, 我們一定又會覺得沒辦法選出想像中的 features, 結果當然也就不會好.
就 feature set F 來說, 其組成也是需要探討的地方. 通常 features 之間不會全然是 independent, 同時我們也不可能要求 user 要填寫三四十個 features 才能準確搜尋. 因此怎樣選擇可以造成最大區別度的 features 是另外一個問題. 在 paper 中選擇了 colors, texture, shape, color layout, 以及 textual annotation 作為 feature set. 然而我想實際上 feature set 的選擇可能會跟 image base 裡面究竟存哪些 images -- 換句話說目前應用的 context 是什麼有關係, 唯有考慮 context 的問題才有可能決定最有效率的 feature set.
另外 paper 內容有一點很有趣, 他使用了兩個 form 來表達 pseudo code, 一個是常見的 text-based pseudo code 形式, 另外一個是有點像流程圖的方塊形式 (我以前沒看過這樣畫的), 講的是同一個 algorithm, 但是兩個要表達的東西又各自有點不同, 所以你也不能批評他說是多餘的. 倒是 paper 內也沒有解釋為什麼需要特別用兩種方式表達就是了, 或許是因為整合起來會太複雜吧, 分開成兩個簡化的 view 效果一樣, 各自有各自的焦點在, 就跟 UML 需要分成好幾個 view 一樣. ( figure bellow is referred from [1])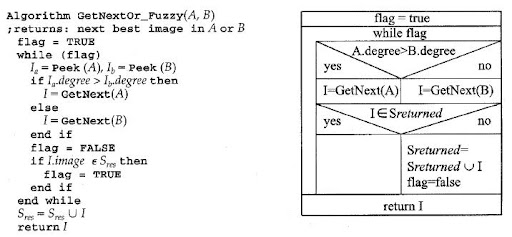
雖然跟我的 major domain 稍微有點距離, 很多 detail 也看不太懂, 但是從單純 information retrieval 的角度去思考, 以及想到 multimedia retrieval 應用的可能問題, 還是蠻有意思的一篇 paper.
References
[1] M. Ortega, Y. Rui, K. Chakrabarti, K. Porkaew, S. Mehrotra, and T. S. Huang, "Supporting ranked boolean similarity queries in mars," IEEE Transactions on Knowledge and Data Engineering, vol. 10, pp. 905-925, Nov/Dec 1998.
[2] CIRES, URL : http://cires.matthewriley.com/
[3] imgSeek, URL : http://www.imgseek.net/
[4] GIFT, URL : http://www.gnu.org/software/gift/
[5] MARS snapshot, URL : http://www.ifp.uiuc.edu/~qitian/MARS.html
0 意見:
張貼留言