
Reusing Source Code Document Generator as Program Parser
之前在對於某個 software measurement 想法進行 prototyping 時, 因為短時間內需要建立數個不同 programming languages 的 parsers, 同時還要能容易取得 parsing results, 因此很傷腦筋. 雖然已經有類似 ANTLR 的 parser generator, 但是寫 grammar file 還是很麻煩的一件事, 而別人已經寫好的 grammar file 能支援的 programming languages 也有限, 有些是尚沒有最新版本的 grammar files, 有些則是要自己寫. 而就算寫出來, 通常 parser generator 也不會特別幫你設計 parsing information 存取的 interface, 還是需要手動去 parser 裡面作一些修改, 一整個麻煩.
因為想偷懶, 結果就把腦筋動到支援較多 programming language 的 source code document generator 上, 例如 Doxygen.
Source code document generator 本身就一定會有 parsing 的功能, 但是要把這塊 component 挖出來也不容易, 畢竟人家本來就不是 design for reuse. 所以就採取折衷的辦法, 利用 document generator 能夠產生 HTML 或是 XML 等 formatted document 的特性, 再寫一個 XML parser 去讀取需要的 parsing information 就好. 寫 XML parsing 就簡單多了, 基本上就是在樹上繞來繞去而已. 整個流程像這樣 :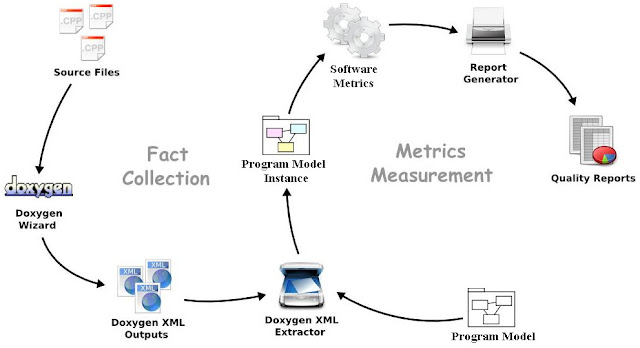
這樣在 Fact Collection 的 phase 幾乎不用作什麼事情了, 而同時 Doxygen 對於不同 programming language 的 parsing results, 用 XML 存的話, naming 都還蠻一致的, 所以所建立的 Doxygen XML Extractor 幾乎不用作太多的修改就可以不斷地 adapt 到不同的 programming languages 身上.
剩下的是在 Metrics Measurement phase, 把從 Doxygen 得到的 parsing information 塞到自訂的 program model 上, 然後利用特定的 software metrics 進行 measurement 就得到 program quality report 了.
在 development effort 上大大地省下許多功夫, 也能滿足 prototyping 的目的. 不過相對來說, 付出的 performance 代價是十分地恐怖, 恐怖到我一點也不想去比較真正的 parser 跟這個作法的 performance, 至少差了幾千倍吧. Performance 的 bottleneck 在於兩個地方, 一個是 Doxygen 要建立 document, 因此需要不斷地 cross-reference code entities, 另外一個則是 Doxygen 與 Doxygen XML Extractor 對於 document file 的 I/O. 對於程式碼很大且複雜的 software 來說, 例如 GCC, 可能要跑個幾天才會出來結果 (我用還蠻不錯的 PC machine 是跑了兩天多才出來).
所以基本上呢, 這種做法就只適合 prototyping 用吧, 另外就是需要不計較執行時花的時間, 唯一省下的好處是要寫 parser 或是 grammar file 的時間 :p
在 wikipedia 上有其他 source code document generator 的比較列表, 其他 document generator 應該也是可以取代 Doxygen 位置, 只要輸出的格式是 formatted document 就沒問題.
0 意見:
張貼留言