
The Middle Observer Pattern
在 Design Pattern [2] 書中對於 Observer Pattern 舉了一個 Graphical User Interface 上的例子作說明. 底層的 Application Data 可能會不斷地更新, 而 Presentation Objects 需要不斷地獲得最新的資料以便進行畫面的更新. 透過 Observer Pattern 設計, 可以處理在此問題下的 Data Object 與 Presentation Object 之間的 Coupling 問題, 同時能夠應付未來可能新增的 Observer Classes.
而 Pablo Iaría 以及 Ulises Chesini 整理的 Middle Observer Pattern [1] 則進一步考量了一個問題 : " 如果我想在這些 Presentation Objects 之間, 保持各個 Data Objects 被呈現時的 Colors 各自是一致的, 同時易於進行調整, 該如何設計 ? "
關於 Colors 的資訊, 與時常會被更新的 Data Objects 內容並不相同, 因此不適合放在 Observer 身上, 當 Observer Classes 數量多時會造成額外的 Data Redundancy 問題 ( 對於 Subject 來說也是會有同樣的問題 ), 同時不利於重新進行 Colors 調整. 如果由 Subject 透過特殊的 Interface 告知 Observers ( 或是提供 Observer 查詢 ), 則會造成兩者之間額外的 Coupling, 這也不是原本的 Observer Pattern 想要的. 利用兩個 Observer Pattern 的作法就更加不可能了.
這個問題可進一步延伸成為, " 如果 Data Objects 除了更新的資料需要被通知 Presentation Objects 之外, 還需要伴隨著其他的 Metadata, 那麼這些 Metadata 應該如何被管理 ? "
作者採用的解法是加上一個額外的 Object : Middle Observer.
Middle Observer 負責對於 Metadata 的管理以及提供 Concrete Observers 查詢 Metadata 的能力. 對於 Subject 來說, Middle Observer 的行為跟一般 Observer 相同, 而對於 Concrete Observer 來說, Middle Observer 提供了跟 Subject 一模一樣的介面. 唯一不同的是可以透過 setExtraState/getExtraState interface 去得到 Metadata 的資訊, 以及用來維持所有 Observers 之間的 Metadata Consistency.
在 [1] 中也說明了與此 Pattern 概念相關的其他 Design Patterns, 包含 Decorator, Proxy, Mediator, Singleton, 以及 Chain of Responsibility Patterns. 不過我覺得最關鍵的還是讓 Middle Observer 扮演雙面人的想法.
從上圖中其實看得出來 Middle Observer 也是做了他份外的事 : 幫忙 Delegate 來自於 Concrete Subjects 與 Concrete Objects 之間的溝通. 如果把 Middle Observer 獨立開來, 只做 Concrete Observers 之間的 Metadata Coordination 動作, 也是足以完成同樣的事情. 但是效果就會類似於使用兩個 Observer Patterns 作組合, 對於 Concrete Observers 來說要同時參與兩個 Observer Patterns 感覺是累了點 :p , 況且 Metadata 的更動其實並不頻繁. 因此讓 Middle Observer 扮演了雙面人, 則 Concrete Observers 就只需要參與一個 Observer Pattern 的運作即可.
References
[1] Pablo Iaría and Ulises Chesini, "Refining the Observer Pattern: The Middle Observer Pattern," Proceedings of Pattern Languages of Programs (PLoP), 1998, PDF file on PLoP
[2] Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley, 1995
FileZilla 對密碼採用明碼紀錄 !?
在嘗試修改 FileZilla 的一些 Configuration 時意外發現, FileZilla 在紀錄最近一次的連線時, 居然是採用明碼來紀錄 Password = =
FileZilla 為了方便重新連線到剛剛斷線的 FTP Server, 或是快速進行常用的連線, 會把最近一次的連線資料紀錄在 $HOME/.filezilla/filezilla.xml 的最後面, 在 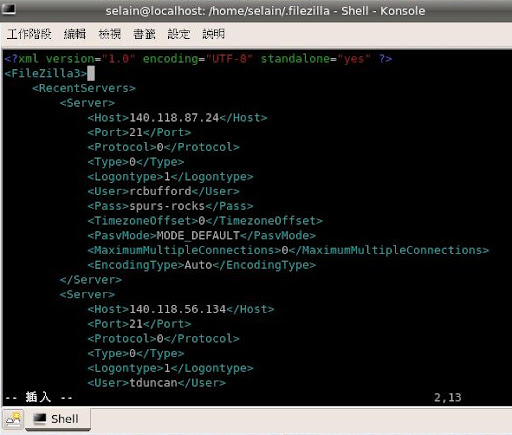 對於 FileZilla 使用來說當然問題不大, 因為只要你能夠用該帳號啟動 FileZilla, 就能夠透過 FileZilla 進行前幾次的快速連線, 看不看的到密碼差別不大. 但是以使用者的角度來說, 因為 filezilla.xml 以及 recentservers.xml 這兩個檔案都是一般閱讀權限, 因此只要使用該帳號執行的程式都有相當的機會去讀取這兩個檔案, 這時候用明碼跟編碼差別就很大了.
對於 FileZilla 使用來說當然問題不大, 因為只要你能夠用該帳號啟動 FileZilla, 就能夠透過 FileZilla 進行前幾次的快速連線, 看不看的到密碼差別不大. 但是以使用者的角度來說, 因為 filezilla.xml 以及 recentservers.xml 這兩個檔案都是一般閱讀權限, 因此只要使用該帳號執行的程式都有相當的機會去讀取這兩個檔案, 這時候用明碼跟編碼差別就很大了.
不知道 FileZilla 選擇用明碼的理由是甚麼 ? 多想兩秒鐘, 其實你可以編一下碼的.
Evri, The First Try
昨天 Sign Up, 今天就收到 Invitation 摟 :)
不過目前開放的試用內容其實讓人有點失望. 首先是內容其實跟之前在 Evri Blog 上看到的圖片差不多, 再來是 UI 操作上沒有我想像中的那麼具有 Revolution.
目前有 Most Popular People, Most Popular Places, 以及 Most Popular Things 可以選擇. 但是任何一個項目都還沒有辦法讓你自己指定 Search Keywords. 換句話說我想 Search Evri 是沒辦法的, 只能選擇他 Popular 列表上對象. 這個正式開放後應該會可以進行 Keyword Search, 不然可能一整個月 Popular List 都不會變阿 = =
左邊是 Most Popular 列表, 右邊是最近的 Rising & Falling 列表, 中央是 Evri 所謂的 "Data Graph". 下方則是關於主題的文章列表, 但是決定出現文章順序的演算法未知.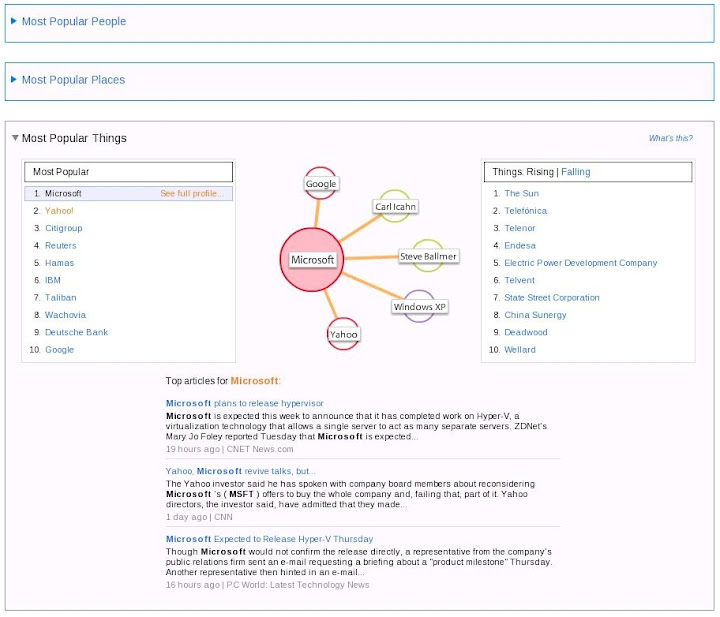 點選主題旁邊的 See Full Profile 可以看到關於主題的更詳細資訊頁面. 左下方的 "What's happening with ... " Section 有點意思, 基本上利用 Keywords 作為 Indexing, 對於相關的 Information 做了樹狀分類, 因此可以快速地選擇關鍵方向瀏覽該方向的 Information.
點選主題旁邊的 See Full Profile 可以看到關於主題的更詳細資訊頁面. 左下方的 "What's happening with ... " Section 有點意思, 基本上利用 Keywords 作為 Indexing, 對於相關的 Information 做了樹狀分類, 因此可以快速地選擇關鍵方向瀏覽該方向的 Information.
右下方則是針對主題所建立的 Profile. 不過 Profile Template 應該需要知道對像是 People, Place, Company 之類的才有辦法建吧, 一般雜亂的 Things 要怎麼建 Profile ? 因為 Evri 給的 Demo 裡面在 Things 部份幾乎都是 Company, 不知道未來這部份會如何處理.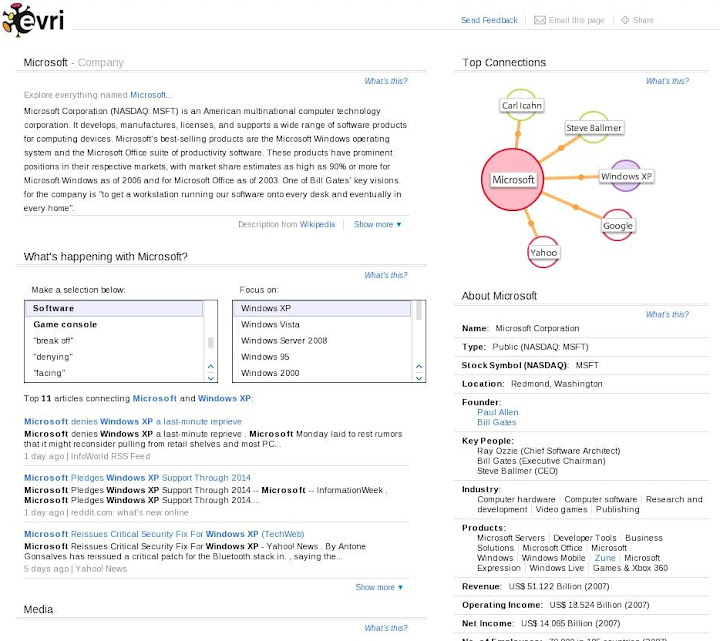
至於所謂的 "Data Graph" 或是上圖的 Top Collection 部份, 實際的作用沒有想像中的大. 基本上就是利用視覺化的方式告訴你哪些其他主題與你目前所觀看的主題相關度最大, 但是並沒有實際的搜尋導引作用, 你無法透過此 Data Graph 來快速切換主題, 而是必須透過左下方的文章內的關鍵字連結來切換主題. 會這樣設計應該也是有理由的. 可能的原因是點選 Data Graph 內的其他連結點是用來更新下面的相關文章到特定個關聯方向, 而不是一下子就切換到其他主題去.
好吧, 我想大概就是這樣了, 我應該沒漏掉什麼東西, 整體來說並沒有太多令人驚艷的設計, 這使得我不是很看好 Evri ="= , 除非正式開放之後出現其他的爆點摟. 以目前 Evri 的能力來說, 我認為 Google 想要的話大概一週 ~ 兩週就可以完成同樣的 Beta 服務網站, 甚至資料量會遠勝 Evri. 因此不管 Evri 是否能打響第一炮, 都很難令人對其前景樂觀, 加上技術難度不高, 要複製很容易, 使得 Evri 想賣個好價錢大概也很困難.
希望 Evri 能讓我看走眼摟 ~ 這樣事情會比較有趣 :)
Evri : Yet Another Semantic Search Engine ?
上個月 Evri -- 號稱是嶄新的 Content-based Search Engine -- 在 6th D Conference 上有了 Demo. ( 以下圖片引用自 D6, evri session photos )
在 RWW 的介紹文章 Evri Beta Launches: Search Less - Understand More 下, Falafulu Fisi 給的回應其實還蠻中肯的 :
{kind=link}
...... there is nothing new here. The technique they used has been around for a long time and it is called, Latent Semantic Indexing (LSI) ...... The only thing that matters in the domain of search if one can show that his/her system has higher recall capability than his/her competitor or similar system out there......
的確以目前可得的資訊看起來, Evri 也是基於對 Content 進行 LSI 或其他 Semantic Web Analysis 來建構整個 Search Topology, 這點從 Evri 的 Hiring 資訊也看得出來. 不過如果我們再更仔細一點去看 Evri 的 Blog ( ㄜ... 雖然文章很少 ), 在 6/24 的 Little Room 文中說道 :
...... And, even with great semantically-aware data, it’s all about the UI. Evri is building a “data graph” that shows interesting and useful connections to explore about things in the outside world-things that aren’t part of your social graph.
我覺得 Evri 光明正大的提到 UI 是件很好的事情 ( 這個 UI 讓我很想試用看看阿 ). 利用 Semantic Web 的 Content-based Search Engine 在這一兩年陸陸續續地出現, 但是有哪個真正吸引了大眾的目光, 有哪個真的足以威脅到 Big Three Search Engine : Google, MS Live Search, Yahoo 的佔有率 ?
以 Business 的角度來說, 或許像 Evri 開始改用 User 的角度來思考, 希望透過更好更易懂的 User Interface 來包裝 Semantic Web 會是一個不錯的嘗試. 不用想要去教會 User 什麼是 Semantic Web, 因為 Semantic Web 本來就存在我們的腦袋跟生活裡, 而是透過 UI Languages, 讓 User 很容易地在 Computer System 上操作 Semantic Web, 補足缺少的資訊區塊.
回頭來看 Evri 的標語 : Search Less, Understand More.

看起來似乎很合理, 不是嗎 ? 我已經 Sign Up 了, Evri 快點公開讓我用用看吧 ~
WikiCafe : Wiki for Video
( 原始報導請參考 ReadWriteWeb 上 Marshall Kirkpatrick 的文章 WikiCafe: MetaCafe Invites Users to Edit Video Metadata )
影音分享網站 MetaCafe 提出了一個有趣的實驗性計畫 : WikiCafe.
顧名思義 MetaCafe 希望把 Wiki System 目前在文字文件的成功模式複製到影像文件上, 不過 WikiCafe 現階段還僅止於把 Vedio Metadata 以及 Commentary 給 Wiki 化, 把 Vedio Tagging 的修改權力從 Vedio 分享者擴張到整個 Community.
首要的考量當然會是 Metadata Quality 的問題, 在 Marshall 的文章中也提到 MetaCafe 的 Community 整體素質比起 YouTube 來的高, 因此計畫成功的可能性也比較高. 不過我懷疑 MetaCafe 的 Community 素質高跟他目前的主要使用者族群有關, 如果 MetaCafe 的使用者族群分佈跟 YouTube 趨近的話, Community 素質是否還能維持就很難說了.
因此管理制度還是很重要的, 即便是 Wikipedia 也免不了面對此問題. 在爭議性高的議題上, 例如中國與台灣主權的問題, Wikipedia 也相當依賴頁面管理者仲裁, 甚至暫停管制該頁面的自由更新. MetaCafe 是否能複製 Wikipedia 的成功, Community 自身的管理制度我想會是成敗關鍵.
而在 Marshall 的文章中也提到另外一個 Versioning 的問題.
純論 Metadata 的 Versioning 問題, 也跟上述的管理制度有關, 同時我想透過 Wiki-like 的方式解決應該沒有甚麼問題. 會有問題的可能是 (1) Vedio 本身的 Versioning 問題, 以及 (2) Vedio 與 Metadata 之間的 Versioning 問題.
Vedio 本身的 Versioning 問題指的是當原作者修改了 Vedio, 甚至是 Community 修改了 Vedio 之後的 Vedio Version Control 問題. MetaCafe 並沒有提到 Vedio 本身被修改的事情, 當誰說不可能呢 ? 我們有 Open Source Software , Open Source Hardware, 還有 Open Disk Spaces (例如 000webhost.com ) , 也許下一個流行的就會是 Open Source Media :p ( 扯遠啦 ~ )
同樣的, Vedio 與 Metadata 之間的 Versioning 問題也來自對於原本 Vedio 所進行的修改. 在 Vedio 經過修改之後, 原本的 Commentary 是否還適用呢 ? 是否所有經過修改的 Vedio 都必須被視為新的 Vedio, 無法跟之前的 Commentary 拉上關係呢 ? 到目前為止好像沒有看到哪家 YouTube-like Website 針對這個問題提供管理服務.
不過解決方法其實已經具雛型了. 在 André Santanche 的 Fluid Web [1] 中其實就說明了類似的模型, 以及對於 Versioning 的解決方案. 如果可以被成功用上的話, 應該可以大幅降低 Versioning 管理的 Cost.
References
[1] A. Santanche and C. B. Medeiros, "A Component Model and Infrastructure for a Fluid Web," IEEE Transactions on Knowledge and Data Engineering, vol. 19, no. 2, pp. 324-341, Feb. 2007
Emailcash 的獎勵郵件漏洞
(請勿利用本篇文章內容進行任何違法行為)
在 Emailcash 的獎勵郵件中, 通常會在廣告最後附上一個連結位址, 透過 Browser 連結到該位址, 就會自動在你的帳號中加入一定數量的獎勵點數, 期間不需要你的帳號登入的動作. 連結位址長的像是這樣 :
http://www.emailcash.com.tw/edmrating/main2.asp?uid=seLain
&aid=2F99D6CA-7A7C-474C-8BE6-8C80DAAD309C
位址中的 uid 參數用來說明要加入點數的帳號, 而 aid 則是辨認該封獎勵郵件的特殊編號.
獎勵郵件編號的產生演算法雖然不清楚, 但是透過偷偷修改編號, 重新送出連結可以得知, 系統是透過編號去確認該封獎勵郵件的存在以及時效.
而進一步偷偷修改 uid ( 修改成其他真實存在的帳號 K ), 不改變 aid, 再重新送出連結要求時, 會發現連結會被判定是有效的, 即便該帳號 K 並非你所有, Emailcash 還是會認定有效, 並且給予該 uid 紀錄帳號獎勵點數.
因此可以得到兩個結論 :
- uid 可以自由變動, 只要你知道哪些 uid 是真實存在的
- aid 隨著不同的獎勵郵件而有不同, 但是同一封獎勵郵件對於不同帳號寄出的實體電子郵件使用同樣的 aid
- 透過有意識地蒐集真實存在的帳號, 可以簡單地建立一個自動看獎勵郵件的系統. 只需要從一個帳號取得 aid, 就可以幫所有的帳號得到獎勵點數, 而不需要真實使用者的介入. 這對於 Emailcash 原本的廣告目的來說是完全違背的. 大量真實帳號的取得有很多種方式, 像是從首頁的每日得獎名單, 從真實的使用者身上蒐集, Emailcash 論壇, 或自己申請等等. 甚至是使用暴力法或辭典法去嘗試所有可能的帳號. 不管何者都會造成 Emailcash 的安全威脅.
- Emailcash 原本可能透過所建立的 User Profiles, 針對不同的族群發送不同的獎勵郵件. 而如果在使用者送出獎勵郵件連結之後, Emailcash 的 Server 端沒有針對該使用者帳號是否為原本應該收到該封廣告信的族群作檢查的話 ( 例如上面的帳號 K 可能原本不該會收到我所收到的這封獎勵郵件 ), 那麼透過修改 uid 重新送出連結, 就會使得非預設廣告族群的帳號獲得額外的利益. 這種情況大量發生的話 Emailcash 官方也會很難處理, 因為此額外利益如果其來源缺乏 Traceability 就很難一一追溯取消, 同時也不容易追究責任, 因為進行此行為的未必是這些獲得利益的帳號擁有者, 就跟上一點說的情形一樣
FireFox 3 效能測試
就在本週之初, 與 FireFox Download Day 同一天, MiningLabs 公佈了一個對於 FireFox 3 的部份效能測試 ( Empirical Study ), 並與 FireFox 2 做了簡單的圖表比較.
大致的重點為 :
- JavaScript 執行效率有顯著改進
- Memory 使用量 FireFox 3 比 FireFox 2 更吃重
- Memory 釋放率 FireFox 3 比 FireFox 2 來的好
而 Memory Release 的改善我很明顯的感受到了 :)
以下圖片引用自 MiningLabs.
 過去 FireFox 2 在我的系統上經常會飆高到佔用 Memory 40 % ( 約 400 MB ) 以上的可怕情況, 這固然跟我使用習慣有關, 經常是開了 30+ 以上的分頁, 包含許多 PDF 頁面. 但是即便在 Idle 時期也不會降下來, 這就是 FireFox 2 本身有缺點的地方了.
過去 FireFox 2 在我的系統上經常會飆高到佔用 Memory 40 % ( 約 400 MB ) 以上的可怕情況, 這固然跟我使用習慣有關, 經常是開了 30+ 以上的分頁, 包含許多 PDF 頁面. 但是即便在 Idle 時期也不會降下來, 這就是 FireFox 2 本身有缺點的地方了.FireFox 3 在本週的使用中, 當我偶爾用到一半刻意開 top 觀察的時候, 多在佔用 Memory 20 % 以下, 而 Idle 時則肯定在 10% 以下. 由於我整天 FireFox 幾乎是不關的, 因此 FireFox 本身 Memory Release 效能的改善也帶動整體工作環境的操作順暢感 :)