
CVSGrab
看名字就知道 CVSGrab 是用來抓取 CVS 資料用的. 不過 CVSGrab 並非一般利用 pserver 與 CVS server 作 communication 的 CVS client, 而是透過 CVS web interface, 去讀取 CSV server 內的資料.
之所以這樣做是因為, 往往要 access 某個 project 的 CVS server 時, 卻發現被網路上的某個 firewall 擋住了 pserver, 不見得是刻意檔的, 可能是公司只有開放 http port 之類的, 因此就無法利用走 pserver protocol 的 CVS client 去讀取 CVS 資料. 而 CVSGrab 利用 http, 透過各種 CVS web interface (例如 ViewCVS or CVSWeb, ViewCVS 現在叫 ViewVC 了, 因為也支援 SVN 了 ) 去抓取 CSV 上的資料, 來解決這樣的問題.
不過這樣的話, 我倒覺得名字應該叫做 WebCVSGrab 或是 CVSWebGrab 比較適切 :p
Pyra Lab
最近迷上了 Blogger 上方的 "下一個 Blog>>" 連結, 想知道背後的 linking 機制是怎樣. 每次按 "下一個 Blog>>" 都會連結到其他的 Blog, 但是每次幾乎都不相同, 如果到到下一個 Blog 再 return, 再按一次結果也是會不同, 真的是隨機的嗎 ? 真是令我好奇.
學資訊的總是想挖看看別人是怎麼搞的, 看到 link 上有 next_blog.pyra , 本來以為是某種 script, 想抓卻抓不下來, 於是就找找 .pyra 是什麼格式, 結果意外發現原來 pyra 是有意義的, 應該是指 Blogger 被 Google 收購之前的母公司 Pyra , 不過現在網頁只剩下紀念性質的頁面了. 另外 Wikipedia 也可以找到 Pyra Lab 的歷史說明頁面. 不過仍然不知道 .pyra 是否是某種程式語言格式的副檔名, 畢竟公司內部有開發方便自己用的程式語言也是正常的事情.
後 來發現直接用 next_blog 的網址 : http://www.blogger.com/redirect/next_blog.pyra 也可以直接得到下一個 blog, 只是不知道他的 argument 怎樣輸入, 或許可以藉由大量蒐集 next blog 的回應, 反推其 next blog 的機制是怎樣 ?
Paper Writing Process (2) : 國科會 proposal
之前依照自己寫 NSC proposal 的經驗, 幫實驗室整理了一份 paper writing process, 並畫了一張簡圖如下, 應該可以作為整理 paper writing process 的開端. ( 底下的內容去除了關於我們實驗室的 specific configuration ) Process Explanation
Process Explanation
-
如果在開始撰寫國科會計畫之前, 就已經跟老師有過充分的討論, 並確定了解此國科會計畫申請書, 所要寫出的內容及願景 ( Scope, Vision ), 則此部分可以略過. 否則的話, 這部分實為相當重要的一部分. 類似於 Software Development 中的 Domain Analysis, Requirement Phase, 需要把此次計畫的 Context 確認清楚, 包含自己是否完全了解此計畫之意義, 與老師對於內容的意見是否一致, 對於往後的撰寫有很大的影響. 如果這部分弄不清楚, 則後續的 Writing 很可能會寫的極為不順利, 且 Iterative Refinement 階段會需要反反覆覆修改很多次, 甚至把原先的想法都弄混了.
-
Section Planning 階段主要是根據國科會計畫書的格式, 在此次計畫的內容下, 去規劃整份計畫書的大綱. 國科會計畫書的格式, 在計畫內容部分主要可以分為十三個大項目. 其中只有第十二項目是計畫的主體內文部份, 也是這個階段主要規劃的項目. 這部分各實驗是可能有不同的慣用寫法. 這部分接近 Analysis, Architecture Design, High-level Design.
-
Writing 的部分沒什麼特別的, 就是按照規劃開始分工撰寫, 最後再合併. 只有幾點要注意, 可以省下之後合併的功夫. 這部分接近 Detail Design, Implementation.
所有同計畫的撰寫者最好統一使用同樣的編輯軟體, 並以同樣的一份原始檔案去作修改
所有專有名詞, 除了第一次出現時後面用括號附註英文原文, 其他一率使用中文翻譯取代, 不要使用英文. 因此撰寫團隊應該在一開始就統一使用相同的辭彙, 避免中英混用
分工撰寫時應該注意各段落間的邏輯相關性, 避免把邏輯相關性強的分給不同的人撰寫, 減少因為邏輯思維落差產生的問題
撰寫時請記得隨時備份 ( 很重要 )
-
初稿交給老師後, 撰寫人員可以先開始想計畫中英文名稱, 填寫前面的申請補助經費規劃部份,主要研究人力, 以及設備規劃. 中英文名稱以及經費規劃需要徵詢老師的意見. 設備規劃與老師討論實驗室的需要, 是否與計畫需要共同考量, 購買較會使用到的設備. 主要研究人力基本上是從第十二項的內容, 依年度作簡化整理撰寫.
老師看完初稿後, 會找撰寫團隊進行檢討會議. 撰寫團隊應該詳細紀錄老師給的建議, 並將不清楚的地方確認問清楚, 然後估計可以修改完的時間告知老師. 這裡要提醒的是, 請不要因為急著修改而將修改時間訂的很短. 在可用的時間內, 應該好好地思考如何針對老師的建議進行修改, 而不是只急著修改表面的文字, 卻最終無法達到老師的要求. ( Time-Task Trade-Off Consideration )
這個階段視情況可能會反覆很多次, 因此草稿可以完成的時間越早越好, 同時撰寫團隊應該利用反覆修正的機會, 重新檢視自己對於此計畫的想法是否一直在正確的方向上, 或是應該做適度的修正. 這部分想當然相似於 V & V 摟.
Built-in Test ( BIT )
Built-in Test (BIT) 簡單來說就是把 object 內( 在 OO 中來說 )加上 self-testing 的部分, 因而此 object 就會有兩種 modes, 一種是正常的 functional mode, 另一種是 testing mode. 藉由執行 testing mode, 可以確認 object 的運作是否正常, 因而達成 testing 的部分目的. 因為此 tests 是建立在 object 內, 因此叫做 Built-in Test.
下圖取自於 [Wang2000] 可以簡單看出 BIT 的概念, 至於 BIT 的地位以及原始概念可以參考 [Binder1994] : 這些 built-in tests 可能會以 testcases 的方式呈現, 但是基本上跟 JUnit 之類的 testcase 還是有所不同. 例如 BIT 可以測試的對象以及能保證的事情, 跟一般在 object 外部的 testcase 就不完全相同, 同時兩者所持的觀點也不相同.
這些 built-in tests 可能會以 testcases 的方式呈現, 但是基本上跟 JUnit 之類的 testcase 還是有所不同. 例如 BIT 可以測試的對象以及能保證的事情, 跟一般在 object 外部的 testcase 就不完全相同, 同時兩者所持的觀點也不相同.
當然我們也可能把一般的 testcase 整合進 object 內作成 BIT 的樣子, 但是這樣一來就失去了不少 flexibility, 同時也造成 maintainability 的問題. 另外一個問題是, BIT 幾乎只有對原始程式碼了解的人, 可能只有原本的 developers, 可以產生, component consumers 要加入 BIT 有許多困難存在.
References
- [Binder1994] Robert V. Binder, "Design for Testability in Object-Oriented Systems," Communications of the ACM, vol.37, no.9, pp.87-101, Sept. 1994
- [Wang2000] Yingwu Wang, Graham King, Mohamed Fayad, Dilip Patel, Ian Court, Geoff Staples, and Maraget Ross, "On Built-in Test Reuse in Object-Oriented Framework Design," ACM Computing Surveys (CSUR), vol.32, no.1es, March 2000
Jdec : Java Decompiler
Jdec 就如其名是一個 Java Decompiler, 目前主要支援的 features 包含 :
- Decompiling a Java class
- Decompiling a jar file : 我喜歡直接支援 jar file 的 decompiler, 而不是需要使用者自己利用各種技巧來作到
- Selective Decompilation of a class file : 這個功能是不錯, 但是需要知道該 class 的 specific name, 如果可以作到將 jar file 當作 code repository, 而可以利用 keyword 去作 mapping 就更好了. 而且 Jdec 也不能自動將相關的 classes 都作 decompiling. 事實上我們作 decompiling 就是想看 code, 因此如果能自動找出直接相關 (high-coupling) 的, 形成一個 concern, 或許會更為有用.
- Decompiling 2 Versions : 感覺不太有用, 只是方便想比較的人, 但是我直接利用 decompiling a Java class 找出兩個版本, 再用其他更 powerful 的 tool 去比較版本不是更好 ?
- Disassembling a Java class : 這個能力不錯, 雖然我用不太到. 其他的 Java decompilers好像也沒有看過這能力. 但是這功能跟 decompiler 關係有很大嗎 :p
- Local variable information : 只對原本的 developer 較有用而已, 或是想認真 trace code 的人
- Exception Table Information : 這個對於 code tracing 也很有用, 或是 component reuse 時, 可以用這功能加以擴充, 作 contract checking. 不過他還作的不夠好就是了. 既然又作這個, 其實可以在 Decompiling a jar file 功能上搭配這個, 幫忙分析 code 中的 exception handling coverage 情形, 可以用樹狀圖之類的表示. 不過這同樣超越一般 code decompiler 的能力了.
- Constant Pool Details : 一樣, 對於作底層的人, 或是 performance 比較可能比較有用, 一般人大概沒什麼用
- Skeleton Display of Class File : 實用的功能
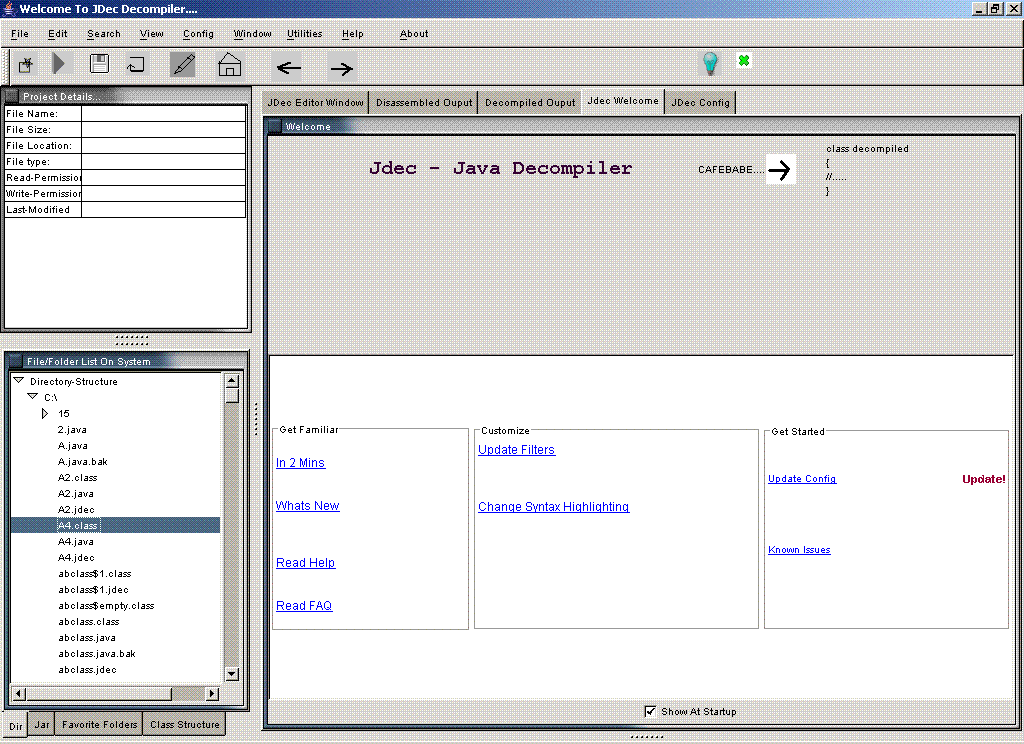
不過我覺得他的操作流程設計不是很好, 新建 decompiling project 時的選擇方式非常 engineer-thinking, 這樣限制使用者的 view 會讓人感覺很不舒服. 同時 configuration 必需所有的欄位都填完才能 decompile 一個 .jar file, 還我一開始試了好幾次, 難道不能有預設值嗎 ?
他的 UI 設計應該是是有受到 Eclipse 使用 JFace 的影響, 不過還差遠了 XD
整體來說是作為一個一般 Jave decompiler 該有的功能都有了, 但是這個時代這樣已經不夠了, 或許 decompiler 所定義的能力範圍就是那樣, 但是我們總是希望更好, 總是希望一個 tool 不只是完成整個 scenario 內的一個 role, 而是能幫我演出整個 scenario, 或是只少把他跟其他 role 的關係交代清楚, 而不是我要自己去指導它們怎麼演戲, 不是嗎 ?
TouchScreen on Linux
看到這三個 YouTube 連結 :
- StarCraft + Touchscreen on linux with wine
- 3D Desktop! TouchScreen and XGL on Linux!
- 3D Desktop! TouchScreen and XGL on Linux (part 2)
XGL 之前利用 LiveCD 玩過, 沒想到搭配 TouchScreen 的能力可以做到這樣, 雖然說實用性還有問題, 但是這跟利用 keyboard & mouse 的 interaction interface 比起來, 已經算是 PC 上的一個 milestone 了 (雖然現在 TabletPC 以及 UltraMobile 也是可以這樣, 但是 PC 還是以 keyboard & mouse 為主).
這也意味著 Softwae GUI 的設計會邁入一個新時代嗎 ? Software Non-GUI part 與 Software GUI part 的分離之議題是否會更加被重視 ?


